



Metas Llama 3 wurde kürzlich veröffentlicht und stieß in der KI-Community auf große Begeisterung. Erfahren wir mehr über Llama 3 – die neueste Errungenschaft von Meta AI.

Metas Llama 3 wurde kürzlich veröffentlicht und stieß in der KI-Community auf große Begeisterung. Erfahren wir mehr über Llama 3 – die neueste Errungenschaft von Meta AI.
Als wir die Innovationen im Bereich der künstlichen Intelligenz (KI) des ersten Quartals 2024 zusammenfassten, stellten wir fest, dass LLMs oder Large Language Models von verschiedenen Organisationen wie am Fließband veröffentlicht wurden. Diesem Trend folgend veröffentlichte Meta am 18. April 2024 Llama 3, ein hochmodernes Open-Source-LLM der nächsten Generation.
Sie denken vielleicht: Es ist nur ein weiteres LLM. Warum ist die KI-Community so begeistert davon?
Obwohl Sie Modelle wie GPT-3 oder Gemini für angepasste Antworten feinabstimmen können, bieten diese keine vollständige Transparenz hinsichtlich ihrer internen Funktionsweise, wie z. B. ihrer Trainingsdaten, Modellparameter oder Algorithmen. Im Gegensatz dazu ist Meta's Llama 3 transparenter, da seine Architektur und Gewichte zum Download zur Verfügung stehen. Für die KI-Community bedeutet dies mehr Freiheit zum Experimentieren.
In diesem Artikel werden wir untersuchen, was Llama 3 kann, wie es entstanden ist und welche Auswirkungen es auf den Bereich der KI hat. Fangen wir gleich an!
Bevor wir uns mit Llama 3 befassen, werfen wir einen Blick auf seine früheren Versionen.
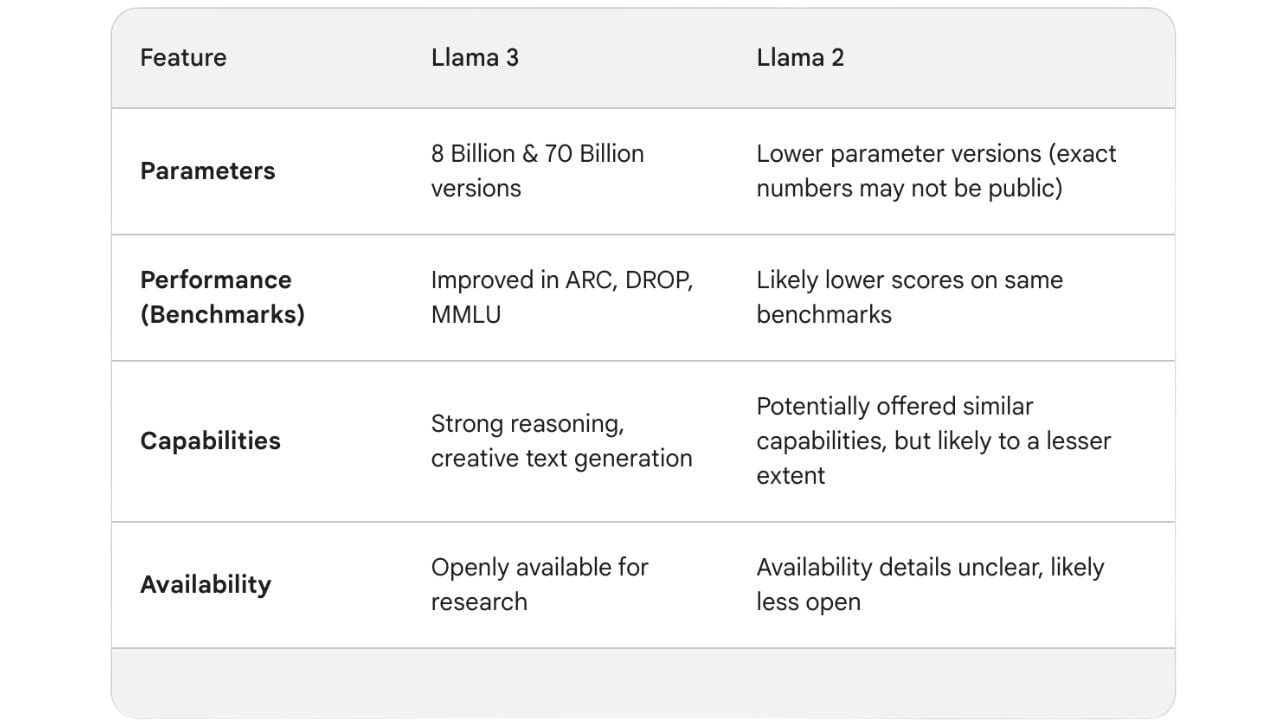
Meta brachte Llama 1 im Februar 2023 auf den Markt, das in vier Varianten mit Parametern von 7 Milliarden bis 64 Milliarden erhältlich war. Im maschinellen Lernen beziehen sich "Parameter" auf die Elemente des Modells, die aus den Trainingsdaten gelernt werden. Aufgrund seiner geringeren Anzahl an Parametern hatte Llama 1 manchmal Schwierigkeiten mit differenziertem Verständnis und gab inkonsistente Antworten.
Kurz nach Llama 1 brachte Meta im Juli 2023 Llama 2 auf den Markt. Es wurde mit 2 Billionen Token trainiert. Ein Token repräsentiert ein Textstück, wie ein Wort oder ein Teil eines Wortes, das als Grundeinheit für die Datenverarbeitung im Modell verwendet wird. Das Modell verfügte außerdem über Verbesserungen wie ein verdoppeltes Kontextfenster von 4096 Token, um längere Passagen zu verstehen, und über 1 Million menschliche Annotationen, um Fehler zu reduzieren. Trotz dieser Verbesserungen benötigte Llama 2 immer noch viel Rechenleistung, was Meta mit Llama 3 beheben wollte.
Llama 3 ist in vier Varianten erhältlich, die mit beeindruckenden 15 Billionen Token trainiert wurden. Über 5 % dieser Trainingsdaten (etwa 800 Millionen Token) stellten Daten in 30 verschiedenen Sprachen dar. Alle Llama 3-Varianten können auf verschiedenen Arten von Consumer-Hardware ausgeführt werden und haben eine Kontextlänge von 8k Token.

Die Modellvarianten sind in zwei Größen erhältlich: 8B und 70B, was 8 Milliarden bzw. 70 Milliarden Parametern entspricht. Es gibt auch zwei Versionen, Base und Instruct. "Base" bezieht sich auf die Standard-Version, die vortrainiert wurde. "Instruct" ist eine feinabgestimmte Version, die durch zusätzliches Training mit relevanten Daten für bestimmte Anwendungen oder Bereiche optimiert wurde.
Dies sind die Llama 3-Modellvarianten:
Wie bei allen anderen KI-Fortschritten von Meta wurden strenge Qualitätskontrollmaßnahmen eingeführt, um die Datenintegrität zu gewährleisten und Verzerrungen bei der Entwicklung von Llama 3 zu minimieren. Das Endprodukt ist also ein leistungsstarkes Modell, das verantwortungsvoll erstellt wurde.
Die Llama 3-Modellarchitektur zeichnet sich durch ihren Fokus auf Effizienz und Leistung bei Aufgaben der natürlichen Sprachverarbeitung aus. Es basiert auf einem Transformer-basierten Framework und betont die Recheneffizienz, insbesondere bei der Textgenerierung, durch die Verwendung einer reinen Decoder-Architektur.
Das Modell generiert Ausgaben ausschließlich auf der Grundlage des vorhergehenden Kontexts, ohne einen Encoder zur Kodierung von Eingaben, was es viel schneller macht.

Die Llama 3-Modelle verfügen über einen Tokenizer mit einem Vokabular von 128.000 Token. Ein größeres Vokabular bedeutet, dass die Modelle Text besser verstehen und verarbeiten können. Außerdem verwenden die Modelle jetzt Grouped Query Attention (GQA), um die Inferenz-Effizienz zu verbessern. GQA ist eine Technik, die man sich wie einen Scheinwerfer vorstellen kann, der den Modellen hilft, sich auf relevante Teile der Eingabedaten zu konzentrieren, um schnellere und genauere Antworten zu generieren.
Hier sind ein paar weitere interessante Details über die Modellarchitektur von Llama 3:
Um die größten Llama 3-Modelle zu trainieren, wurden drei Arten der Parallelisierung kombiniert: Datenparallelisierung, Modellparallelisierung und Pipeline-Parallelisierung.
Bei der Datenparallelisierung werden die Trainingsdaten auf mehrere GPUs aufgeteilt, während bei der Modellparallelisierung die Modellarchitektur aufgeteilt wird, um die Rechenleistung der einzelnen GPU zu nutzen. Die Pipeline-Parallelisierung unterteilt den Trainingsprozess in sequenzielle Phasen und optimiert so die Berechnung und Kommunikation.
Die effizienteste Implementierung erreichte eine bemerkenswerte Rechennutzung von über 400 TFLOPS pro GPU , wenn sie auf 16.000 GPUs gleichzeitig trainierte. Diese Trainingsläufe wurden auf zwei speziell angefertigten GPU durchgeführt, die jeweils 24.000 GPUs umfassen. Diese umfangreiche Recheninfrastruktur lieferte die nötige Leistung, um die großen Llama-3-Modelle effizient zu trainieren.
Um die Betriebszeit der GPU zu maximieren, wurde ein fortschrittlicher neuer Trainingsstack entwickelt, der die Fehlererkennung, -behandlung und -wartung automatisiert. Die Zuverlässigkeit der Hardware und die Erkennungsmechanismen wurden erheblich verbessert, um das Risiko einer stillen Datenbeschädigung zu verringern. Außerdem wurden neue skalierbare Speichersysteme entwickelt, um den Aufwand für Checkpointing und Rollback zu reduzieren.
Diese Verbesserungen führten zu einer Gesamttrainingszeit von mehr als 95 % Effektivität. Zusammengenommen erhöhten sie die Effizienz des Llama 3-Trainings im Vergleich zu Llama 2 um etwa das Dreifache. Diese Effizienz ist nicht nur beeindruckend, sondern eröffnet auch neue Möglichkeiten für KI-Trainingsmethoden.
Da Llama 3 Open-Source ist, können Forscher und Studenten seinen Code studieren, Experimente durchführen und sich an Diskussionen über ethische Bedenken und Vorurteile beteiligen. Llama 3 ist jedoch nicht nur für die akademische Welt gedacht. Es schlägt auch in praktischen Anwendungen Wellen. Es wird zum Rückgrat der Meta AI Chat Interface und integriert sich nahtlos in Plattformen wie Facebook, Instagram, WhatsApp und Messenger. Mit Meta AI können Benutzer natürliche Sprachkonversationen führen, auf personalisierte Empfehlungen zugreifen, Aufgaben ausführen und auf einfache Weise mit anderen in Kontakt treten.

Llama 3 schneidet in mehreren Schlüssel-Benchmarks, die komplexes Sprachverständnis und Denkfähigkeiten bewerten, außergewöhnlich gut ab. Hier sind einige der Benchmarks, die verschiedene Aspekte der Fähigkeiten von Llama 3 testen:
Mit seinen hervorragenden Ergebnissen in diesen Tests hebt sich das Llama 3 deutlich von Wettbewerbern wie dem Gemma 7B von Google, dem Mistral 7B von Mistral und dem Claude 3 Sonnet von Anthropicab. Den veröffentlichten Statistiken zufolge übertrifft das Llama 3, insbesondere das Modell 70B, diese Modelle in allen oben genannten Benchmarks.

Meta erweitert die Reichweite von Llama 3, indem es auf einer Vielzahl von Plattformen sowohl für allgemeine Benutzer als auch für Entwickler verfügbar gemacht wird. Für alltägliche Benutzer ist Llama 3 in Metas beliebte Plattformen wie WhatsApp, Instagram, Facebook und Messenger integriert. Benutzer können auf erweiterte Funktionen wie Echtzeitsuche und die Möglichkeit, kreative Inhalte zu generieren, direkt in diesen Apps zugreifen.
Llama 3 wird auch in tragbare Technologien wie die Ray-Ban Meta Smart Glasses und das Meta Quest VR-Headset für interaktive Erlebnisse integriert.
Llama 3 ist auf einer Vielzahl von Plattformen für Entwickler verfügbar, darunter AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM und Snowflake. Sie können auch direkt von Meta aus auf diese Modelle zugreifen. Die breite Palette an Optionen macht es Entwicklern leicht, diese fortschrittlichen KI-Modellfunktionen in ihre Projekte zu integrieren, unabhängig davon, ob sie es vorziehen, direkt mit Meta oder über andere beliebte Plattformen zu arbeiten.
Die Fortschritte im Bereich des maschinellen Lernens verändern weiterhin die Art und Weise, wie wir jeden Tag mit Technologie interagieren. Metas Llama 3 zeigt, dass es bei LLMs nicht mehr nur um das Generieren von Text geht. LLMs bewältigen komplexe Probleme und verarbeiten mehrere Sprachen. Insgesamt macht Llama 3 KI anpassungsfähiger und zugänglicher als je zuvor. Mit Blick auf die Zukunft versprechen geplante Upgrades für Llama 3 noch mehr Fähigkeiten, wie z. B. die Verarbeitung mehrerer Modelle und das Verständnis größerer Kontexte.
Besuchen Sie unser GitHub-Repository und treten Sie unserer Community bei, um mehr über KI zu erfahren. Besuchen Sie unsere Lösungsseiten, um zu sehen, wie KI in Bereichen wie Fertigung und Landwirtschaft eingesetzt wird.



{kind=link}
{kind=link}
{kind=link}