



Explore la historia, los logros, los desafíos y las futuras direcciones de los modelos de visión.

Explore la historia, los logros, los desafíos y las futuras direcciones de los modelos de visión.
Imagine entrar en una tienda donde una cámara identifica su rostro, analiza su estado de ánimo y sugiere productos adaptados a sus preferencias, todo en tiempo real. Esto no es ciencia ficción, sino una realidad habilitada por los modelos de visión modernos. Según un informe de Fortune Business Insight, el tamaño del mercado mundial de visión artificial se valoró en USD 20.31 mil millones en 2023 y se proyecta que crezca de USD 25.41 mil millones en 2024 a USD 175.72 mil millones para 2032, lo que refleja los rápidos avances y la creciente adopción de esta tecnología en diversas industrias.
La visión por ordenador permite a los ordenadores detect, identificar y analizar objetos en imágenes. Al igual que otros campos relacionados con la IA, la visión por computador ha experimentado una rápida evolución en las últimas décadas, logrando avances notables.
La historia de la visión artificial es extensa. En sus primeros años, los modelos de visión artificial eran capaces de detectar formas y bordes simples, a menudo limitados a tareas básicas como reconocer patrones geométricos o diferenciar entre áreas claras y oscuras. Sin embargo, los modelos actuales pueden realizar tareas complejas como la detección de objetos en tiempo real, el reconocimiento facial e incluso la interpretación de emociones a partir de expresiones faciales con una precisión y eficiencia excepcionales. Esta dramática progresión destaca los increíbles avances realizados en la potencia computacional, la sofisticación algorítmica y la disponibilidad de vastas cantidades de datos para el entrenamiento.
En este artículo, exploraremos los hitos clave en la evolución de la visión artificial. Viajaremos a través de sus inicios, profundizaremos en el impacto transformador de las Redes Neuronales Convolucionales (CNN) y examinaremos los importantes avances que siguieron.
Al igual que con otros campos de la IA, el desarrollo temprano de la visión artificial comenzó con la investigación fundamental y el trabajo teórico. Un hito importante fue el trabajo pionero de Lawrence G. Roberts sobre el reconocimiento de objetos 3D, documentado en su tesis "Percepción de máquinas de sólidos tridimensionales" a principios de la década de 1960. Sus contribuciones sentaron las bases para futuros avances en el campo.
Las primeras investigaciones sobre visión por ordenador se centraron en técnicas de procesamiento de imágenes, como la detección de bordes y la extracción de características. Algoritmos como el operador Sobel, desarrollado a finales de los años 60, fueron de los primeros en detect bordes calculando el gradiente de intensidad de la imagen.

Técnicas como los detectores de bordes de Sobel y Canny desempeñaron un papel crucial en la identificación de límites dentro de las imágenes, que son esenciales para reconocer objetos y comprender escenas.
En la década de 1970, el reconocimiento de patrones surgió como un área clave de la visión artificial. Los investigadores desarrollaron métodos para reconocer formas, texturas y objetos en imágenes, lo que allanó el camino para tareas de visión más complejas.

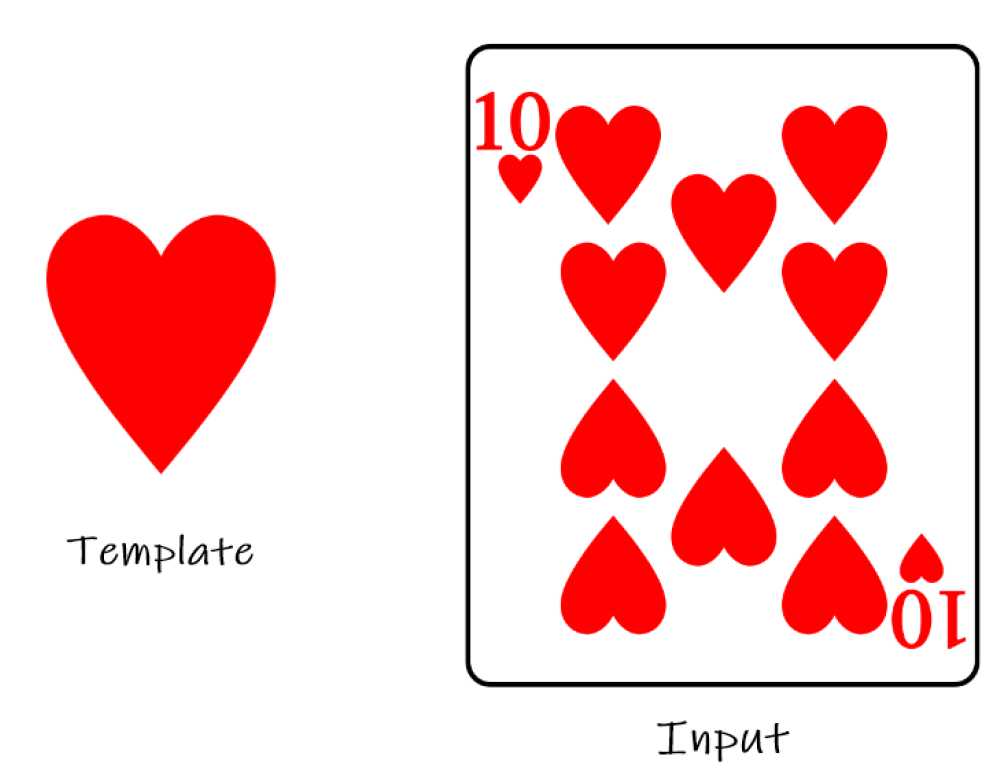
Uno de los primeros métodos para el reconocimiento de patrones consistía en la comparación de plantillas, donde una imagen se compara con un conjunto de plantillas para encontrar la mejor coincidencia. Este enfoque estaba limitado por su sensibilidad a las variaciones de escala, rotación y ruido.
Los primeros sistemas de visión artificial estaban limitados por la escasa potencia computacional de la época. Los ordenadores de las décadas de 1960 y 1970 eran voluminosos, caros y tenían capacidades de procesamiento limitadas.
El aprendizaje profundo y las redes neuronales convolucionales (CNN) marcaron un momento crucial en el campo de la visión artificial. Estos avances han transformado drásticamente la forma en que las computadoras interpretan y analizan los datos visuales, permitiendo una amplia gama de aplicaciones que antes se consideraban imposibles.
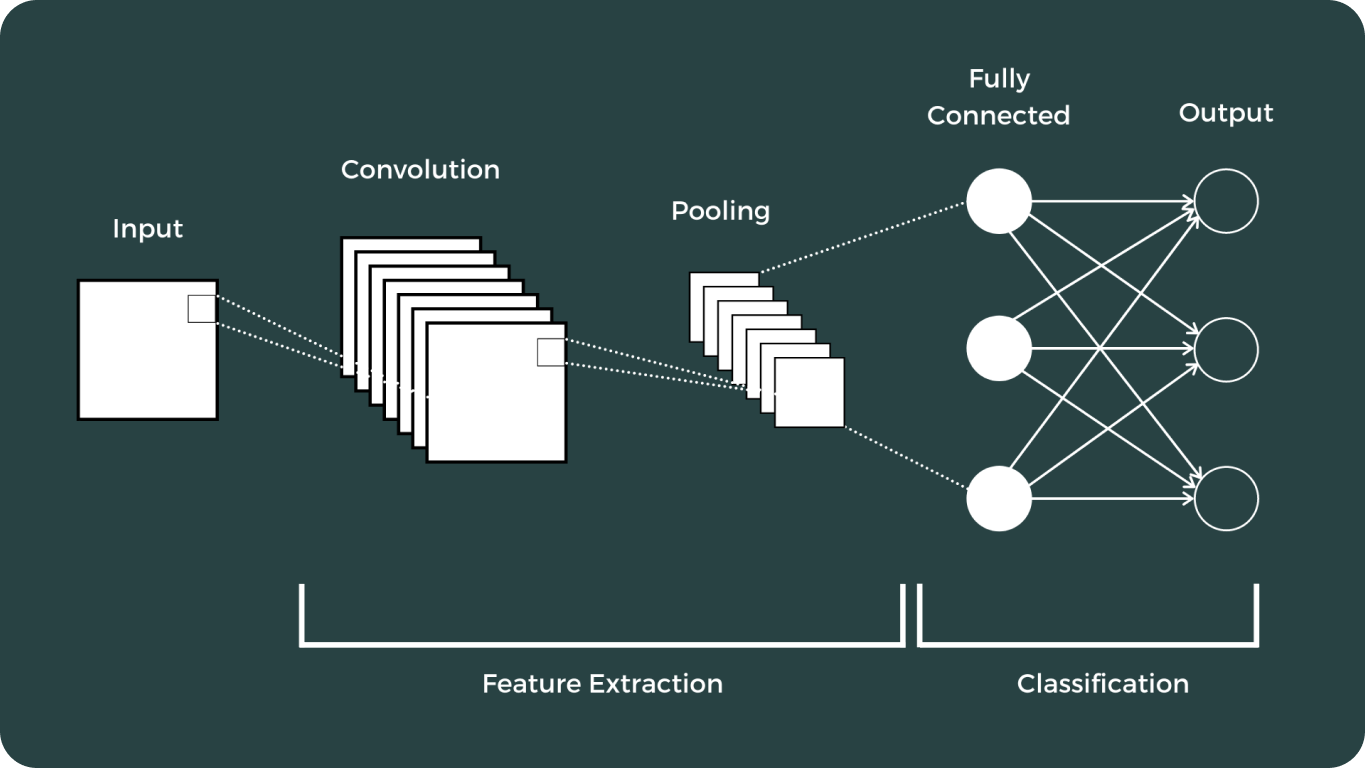
La trayectoria de los modelos de visión ha sido extensa, presentando algunos de los más notables:
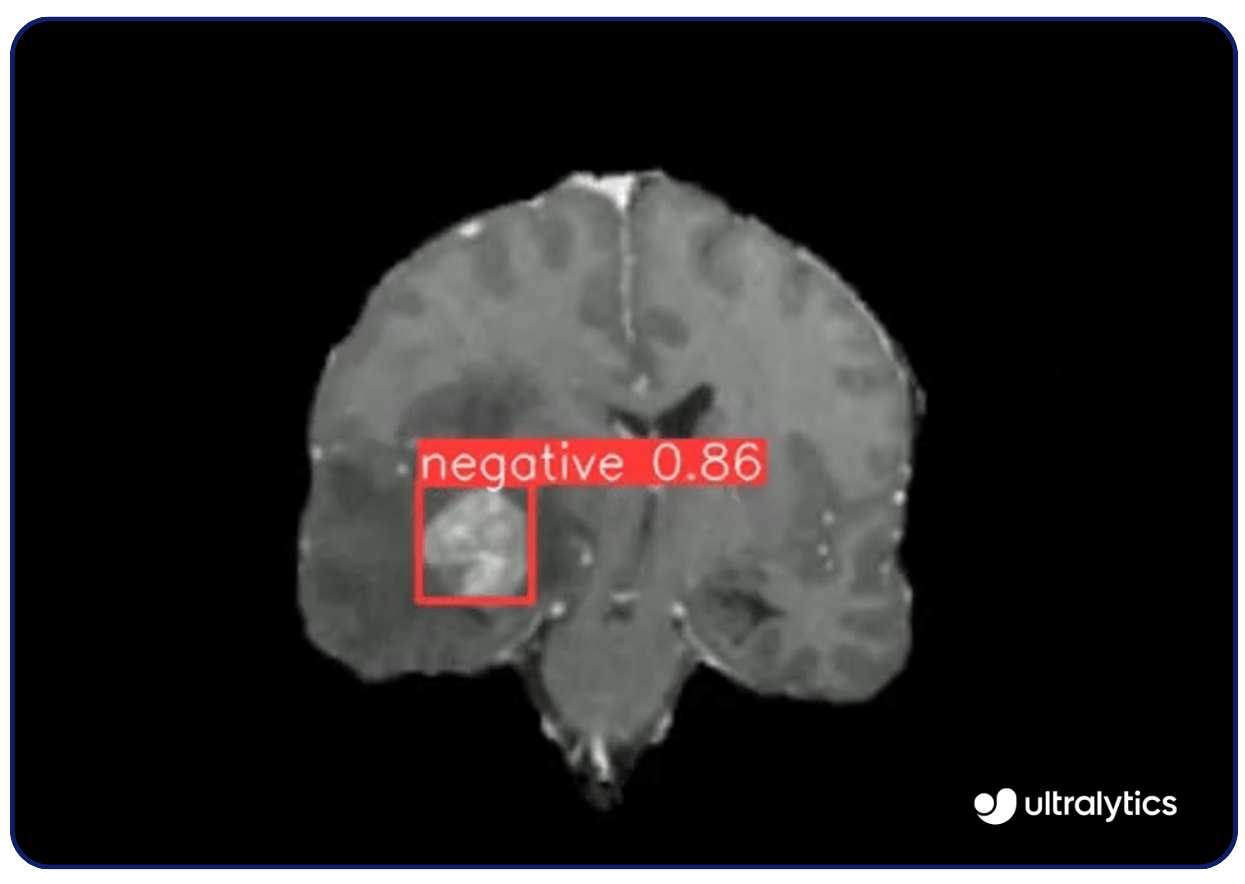
Losusos de la visión por ordenador son numerosos. Por ejemplo, modelos de visión como Ultralytics YOLOv8 se utilizan en imágenes médicas para detect enfermedades como el cáncer y la retinopatía diabética. Analizan radiografías, resonancias magnéticas y tomografías computarizadas con gran precisión, identificando anomalías de forma precoz. Esta capacidad de detección precoz permite intervenir a tiempo y mejorar los resultados de los pacientes.
Los modelos de visión por ordenador ayudan a vigilar y proteger especies amenazadas analizando imágenes y vídeos de hábitats de fauna salvaje. Identifican y track el comportamiento de los animales, proporcionando datos sobre su población y movimientos. Esta tecnología sirve de base a estrategias de conservación y decisiones políticas para proteger especies como tigres y elefantes.
Con la ayuda de la visión artificial, se pueden monitorizar otras amenazas ambientales como los incendios forestales y la deforestación, lo que garantiza tiempos de respuesta rápidos por parte de las autoridades locales.

Aunque ya han logrado avances significativos, debido a su extrema complejidad y a la exigente naturaleza de su desarrollo, los modelos de visión se enfrentan a numerosos retos que requieren investigación continua y avances futuros.
Los modelos de visión, especialmente los de aprendizaje profundo, a menudo se consideran "cajas negras" con transparencia limitada. Esto se debe a que dichos modelos son increíblemente complejos. La falta de interpretabilidad dificulta la confianza y la responsabilidad, especialmente en aplicaciones críticas como la atención médica, por ejemplo.
Entrenar e implementar modelos de IA de última generación exige importantes recursos computacionales. Esto es particularmente cierto para los modelos de visión, que a menudo requieren el procesamiento de grandes cantidades de datos de imagen y video. Las imágenes y los videos de alta definición, al ser de las entradas de entrenamiento que más datos consumen, se suman a la carga computacional. Por ejemplo, una sola imagen HD puede ocupar varios megabytes de almacenamiento, lo que hace que el proceso de entrenamiento requiera muchos recursos y tiempo.
Esto requiere un hardware potente y algoritmos de visión artificial optimizados para manejar los extensos datos y los complejos cálculos involucrados en el desarrollo de modelos de visión eficaces. La investigación sobre arquitecturas más eficientes, la compresión de modelos y los aceleradores de hardware como las GPU y las TPU son áreas clave que harán avanzar el futuro de los modelos de visión.
El objetivo de estas mejoras es reducir la carga computacional y aumentar la eficacia del procesamiento. Además, el aprovechamiento de modelos avanzados preentrenados como YOLOv8 puede reducir significativamente la necesidad de un entrenamiento exhaustivo, agilizando el proceso de desarrollo y mejorando la eficiencia.
Hoy en día, las aplicaciones de los modelos de visión están muy extendidas, desde la atención médica, como la detección de tumores, hasta usos cotidianos como la monitorización del tráfico. Estos modelos avanzados han aportado innovación a innumerables industrias al proporcionar una precisión, eficiencia y capacidades mejoradas que antes eran inimaginables.
A medida que la tecnología continúa avanzando, el potencial de los modelos de visión para innovar y mejorar varios aspectos de la vida y la industria sigue siendo ilimitado. Esta evolución continua subraya la importancia de la investigación y el desarrollo continuos en el campo de la visión artificial.
¿Siente curiosidad por el futuro de la IA de visión? Para obtener más información sobre los últimos avances, explore los documentos de Ultralytics y consulte sus proyectos en Ultralytics GitHub y YOLOv8 GitHub. Además, para conocer las aplicaciones de la IA en diversos sectores, las páginas de soluciones sobre coches autónomos y fabricación ofrecen información especialmente útil.


