



Acompáñenos a conocer más de cerca los nuevos modelos lingüísticos de visión de Google: PaliGemma 2. Estos modelos pueden ayudar a comprender y analizar tanto imágenes como texto.

Acompáñenos a conocer más de cerca los nuevos modelos lingüísticos de visión de Google: PaliGemma 2. Estos modelos pueden ayudar a comprender y analizar tanto imágenes como texto.
El 5 de diciembre de 2024, Google presentó PaliGemma 2, la última versión de su vanguardista modelo de visión-lenguaje (VLM). PaliGemma 2 está diseñado para realizar tareas que combinan imágenes y texto, como generar pies de foto, responder a preguntas visuales y detectar objetos en imágenes.
Basándose en el PaliGemma original, que ya era una herramienta sólida para el subtitulado multilingüe y el reconocimiento de objetos, PaliGemma 2 aporta varias mejoras clave. Estas incluyen tamaños de modelo más grandes, soporte para imágenes de mayor resolución y un mejor rendimiento en tareas visuales complejas. Estas actualizaciones lo hacen aún más flexible y eficaz para una amplia gama de usos.
En este artículo, analizaremos más de cerca PaliGemma 2, incluyendo cómo funciona, sus características clave y las aplicaciones en las que destaca. ¡Empecemos!
PaliGemma 2 se basa en dos tecnologías clave: el codificador de visión SigLIP y el modelo de lenguaje Gemma 2. El codificador SigLIP procesa datos visuales, como imágenes o vídeos, y los divide en características que el modelo puede analizar. Mientras tanto, Gemma 2 gestiona el texto, lo que permite al modelo comprender y generar lenguaje multilingüe. Juntos, forman un VLM, diseñado para interpretar y conectar información visual y textual sin problemas.
Lo que hace que PaliGemma 2 sea un gran paso adelante es su escalabilidad y versatilidad. A diferencia de la versión original, PaliGemma 2 viene en tres tamaños: 3 mil millones (3B), 10 mil millones (10B) y 28 mil millones (28B) de parámetros. Estos parámetros son como la configuración interna del modelo, lo que le ayuda a aprender y procesar datos de forma eficaz. También admite diferentes resoluciones de imagen (por ejemplo, 224 x 224 píxeles para tareas rápidas y 896 x 896 para análisis detallados), lo que lo hace adaptable para diversas aplicaciones.
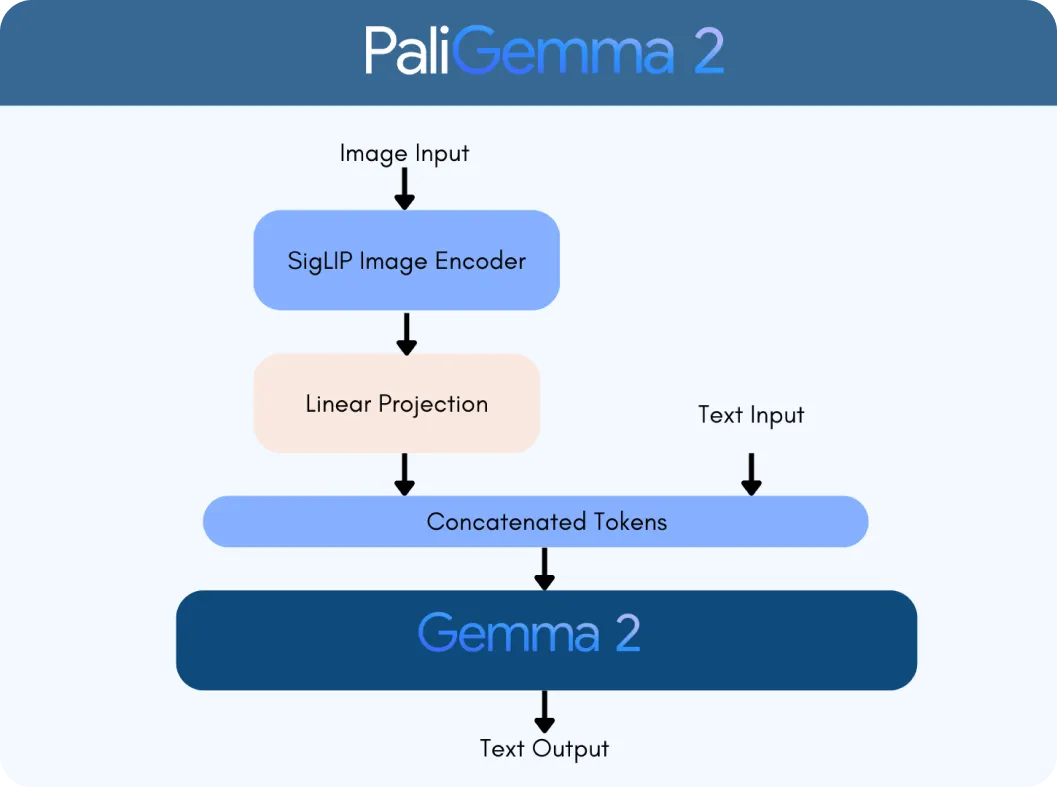
La integración de las capacidades avanzadas de lenguaje de Gemma 2 con el procesamiento de imágenes de SigLIP hace que PaliGemma 2 sea significativamente más inteligente. Puede manejar tareas como:
PaliGemma 2 va más allá del procesamiento de imágenes y texto por separado: los une de forma significativa. Por ejemplo, puede comprender las relaciones en una escena, como reconocer que "El gato está sentado en la mesa", o identificar objetos añadiendo contexto, como reconocer un punto de referencia famoso.
A continuación, veremos un ejemplo utilizando el gráfico que se muestra en la imagen a continuación para comprender mejor cómo PaliGemma 2 procesa datos visuales y textuales. Digamos que sube este gráfico y le pregunta al modelo: "¿Qué representa este gráfico?"

El proceso comienza con el codificador de visión SigLIP de PaliGemma 2 para analizar imágenes y extraer características clave. En el caso de un gráfico, esto incluye la identificación de elementos como ejes, puntos de datos y etiquetas. El codificador está entrenado para captar tanto patrones amplios como detalles finos. También utiliza el reconocimiento óptico de caracteres (OCR ) para detect y procesar cualquier texto incrustado en la imagen. Estas características visuales se convierten en fichas, que son representaciones numéricas que el modelo puede procesar. A continuación, se ajustan mediante una capa de proyección lineal, una técnica que permite combinarlos perfectamente con los datos textuales.
Paralelamente, el modelo de lenguaje Gemma 2 procesa la consulta adjunta para determinar su significado e intención. El texto de la consulta se convierte en tokens, que se combinan con los tokens visuales de SigLIP para crear una representación multimodal, un formato unificado que vincula datos visuales y textuales.
Usando esta representación integrada, PaliGemma 2 genera una respuesta paso a paso a través de la decodificación autorregresiva, un método donde el modelo predice una parte de la respuesta a la vez basándose en el contexto que ya ha procesado.
Ahora que hemos comprendido cómo funciona, exploremos las características clave que hacen de PaliGemma 2 un modelo de lenguaje de visión confiable:
Analizar la arquitectura de la primera versión de PaliGemma es una buena manera de observar las mejoras de PaliGemma 2. Uno de los cambios más notables es la sustitución del modelo de lenguaje Gemma original por Gemma 2, lo que aporta mejoras sustanciales tanto en el rendimiento como en la eficiencia.
Gemma 2, disponible en tamaños de 9B y 27B parámetros, fue diseñado para ofrecer una precisión y velocidad líderes en su clase, al tiempo que reduce los costos de implementación. Lo logra a través de una arquitectura rediseñada optimizada para la eficiencia de la inferencia en diversas configuraciones de hardware, desde GPU potentes hasta configuraciones más accesibles.
Como resultado, PaliGemma 2 es un modelo altamente preciso. La versión de 10B de PaliGemma 2 alcanza una puntuación de Non-Entailment Sentence (NES) más baja, de 20.3, en comparación con el 34.3 del modelo original, lo que significa menos errores factuales en sus salidas. Estos avances hacen que PaliGemma 2 sea más escalable, preciso y adaptable a una gama más amplia de aplicaciones, desde el subtitulado detallado hasta el respuesta visual a preguntas.
PaliGemma 2 tiene el potencial de redefinir las industrias combinando a la perfección la comprensión visual y lingüística. Por ejemplo, en lo que respecta a la accesibilidad, puede generar descripciones detalladas de objetos, escenas y relaciones espaciales, proporcionando una ayuda crucial a las personas con discapacidad visual. Esta capacidad ayuda a los usuarios a comprender mejor su entorno, ofreciéndoles una mayor independencia a la hora de realizar las tareas cotidianas.

Además de la accesibilidad, PaliGemma 2 está teniendo un impacto en varias industrias, incluyendo:
Para probar PaliGemma 2, puedes empezar con la demo interactiva de Hugging Face. Te permite explorar sus capacidades en tareas como el subtitulado de imágenes y la respuesta a preguntas visuales. Sólo tienes que subir una imagen y hacerle preguntas al modelo sobre ella o pedirle una descripción de la escena.
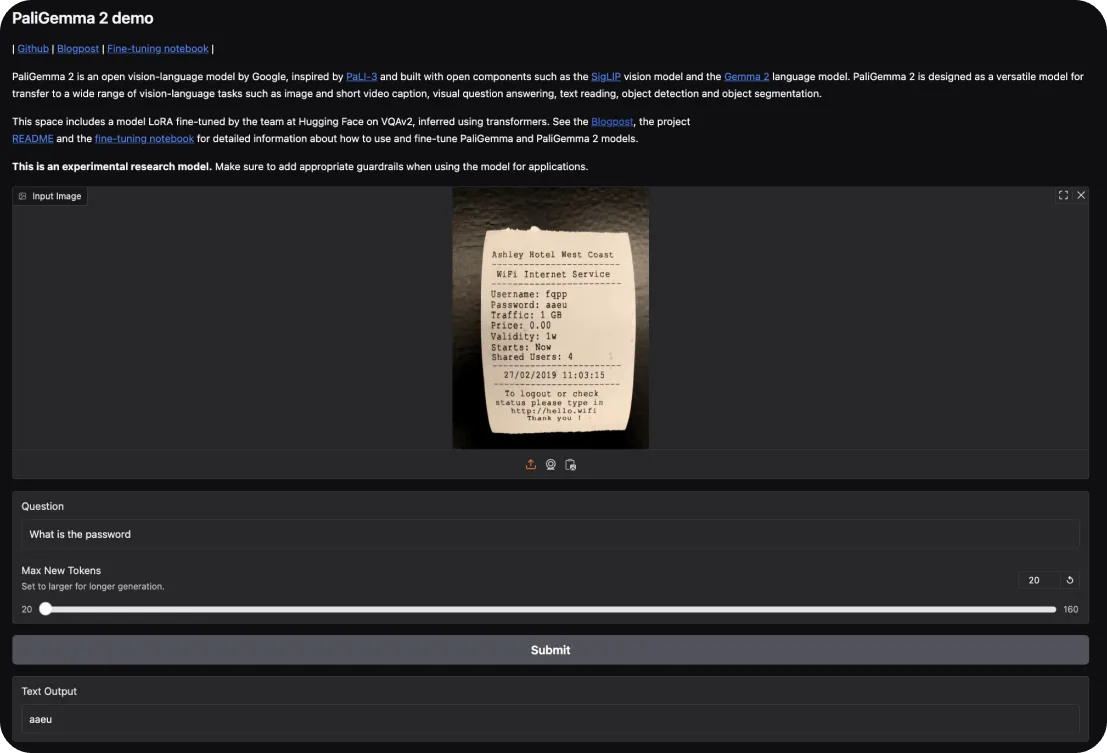
Si desea profundizar, aquí le mostramos cómo puede hacerlo de forma práctica:
Una vez que hemos comprendido cómo empezar a utilizar PaliGemma 2, echemos un vistazo más de cerca a sus principales puntos fuertes y débiles para tenerlos en cuenta al utilizar estos modelos.
Esto es lo que hace que PaliGemma 2 destaque como modelo de visión-lenguaje:
Mientras tanto, estas son algunas áreas en las que PaliGemma 2 puede enfrentar limitaciones:
PaliGemma 2 es un avance fascinante en el modelado de visión-lenguaje, que ofrece una escalabilidad mejorada, flexibilidad de ajuste fino y precisión. Puede servir como una herramienta valiosa para aplicaciones que van desde soluciones de accesibilidad y comercio electrónico hasta diagnósticos de atención médica y educación.
Si bien tiene limitaciones, como los requisitos computacionales y la dependencia de datos de alta calidad, sus puntos fuertes la convierten en una opción práctica para abordar tareas complejas que integran datos visuales y textuales. PaliGemma 2 puede proporcionar una base sólida para que investigadores y desarrolladores exploren y amplíen el potencial de la IA en aplicaciones multimodales.
Participe en la conversación sobre la IA consultando nuestro repositorio de GitHub y nuestra comunidad. Lea sobre cómo la IA está avanzando a pasos agigantados en la agricultura y la sanidad. 🚀


