



Esplora la storia, i risultati, le sfide e le direzioni future dei modelli di visione.

Esplora la storia, i risultati, le sfide e le direzioni future dei modelli di visione.
Immagina di entrare in un negozio dove una telecamera identifica il tuo viso, analizza il tuo umore e suggerisce prodotti su misura per le tue preferenze, tutto in tempo reale. Questa non è fantascienza, ma una realtà resa possibile dai moderni modelli di visione. Secondo un rapporto di Fortune Business Insight, la dimensione del mercato globale della computer vision è stata valutata a 20,31 miliardi di dollari nel 2023 e si prevede che crescerà da 25,41 miliardi di dollari nel 2024 a 175,72 miliardi di dollari entro il 2032, riflettendo i rapidi progressi e la crescente adozione di questa tecnologia in vari settori.
Il campo della computer vision consente ai computer di detect, identificare e analizzare gli oggetti all'interno delle immagini. Come altri campi legati all'intelligenza artificiale, la computer vision ha conosciuto una rapida evoluzione negli ultimi decenni, raggiungendo notevoli progressi.
La storia della computer vision è molto ampia. Nei primi anni, i modelli di computer vision erano in grado di rilevare forme e bordi semplici, spesso limitati a compiti basilari come il riconoscimento di schemi geometrici o la distinzione tra aree chiare e scure. Tuttavia, i modelli odierni possono eseguire compiti complessi come il rilevamento di oggetti in tempo reale, il riconoscimento facciale e persino l'interpretazione delle emozioni dalle espressioni facciali con eccezionale accuratezza ed efficienza. Questa notevole progressione evidenzia gli incredibili progressi compiuti nella potenza di calcolo, nella sofisticazione algoritmica e nella disponibilità di enormi quantità di dati per il training.
In questo articolo, esploreremo le principali tappe dell'evoluzione della computer vision. Ripercorreremo i suoi primi inizi, approfondiremo l'impatto trasformativo delle reti neurali convoluzionali (CNN) ed esamineremo i significativi progressi che ne sono seguiti.
Come per altri campi dell'IA, lo sviluppo iniziale della computer vision è iniziato con la ricerca di base e il lavoro teorico. Una pietra miliare significativa è stata l'opera pionieristica di Lawrence G. Roberts sul riconoscimento di oggetti 3D, documentata nella sua tesi "Machine Perception of Three-Dimensional Solids" nei primi anni '60. I suoi contributi hanno gettato le basi per i futuri progressi nel settore.
Le prime ricerche sulla computer vision si sono concentrate sulle tecniche di elaborazione delle immagini, come il rilevamento dei bordi e l'estrazione delle caratteristiche. Algoritmi come l'operatore di Sobel, sviluppato alla fine degli anni '60, sono stati tra i primi a detect bordi calcolando il gradiente dell'intensità dell'immagine.

Tecniche come i rilevatori di bordi di Sobel e Canny hanno svolto un ruolo cruciale nell'identificazione dei contorni all'interno delle immagini, essenziali per il riconoscimento degli oggetti e la comprensione delle scene.
Negli anni '70, il riconoscimento di pattern è emerso come un'area chiave della computer vision. I ricercatori hanno sviluppato metodi per riconoscere forme, texture e oggetti nelle immagini, aprendo la strada a compiti di visione più complessi.

Uno dei primi metodi per il riconoscimento di pattern prevedeva il template matching, in cui un'immagine viene confrontata con una serie di template per trovare la corrispondenza migliore. Questo approccio era limitato dalla sua sensibilità alle variazioni di scala, rotazione e rumore.
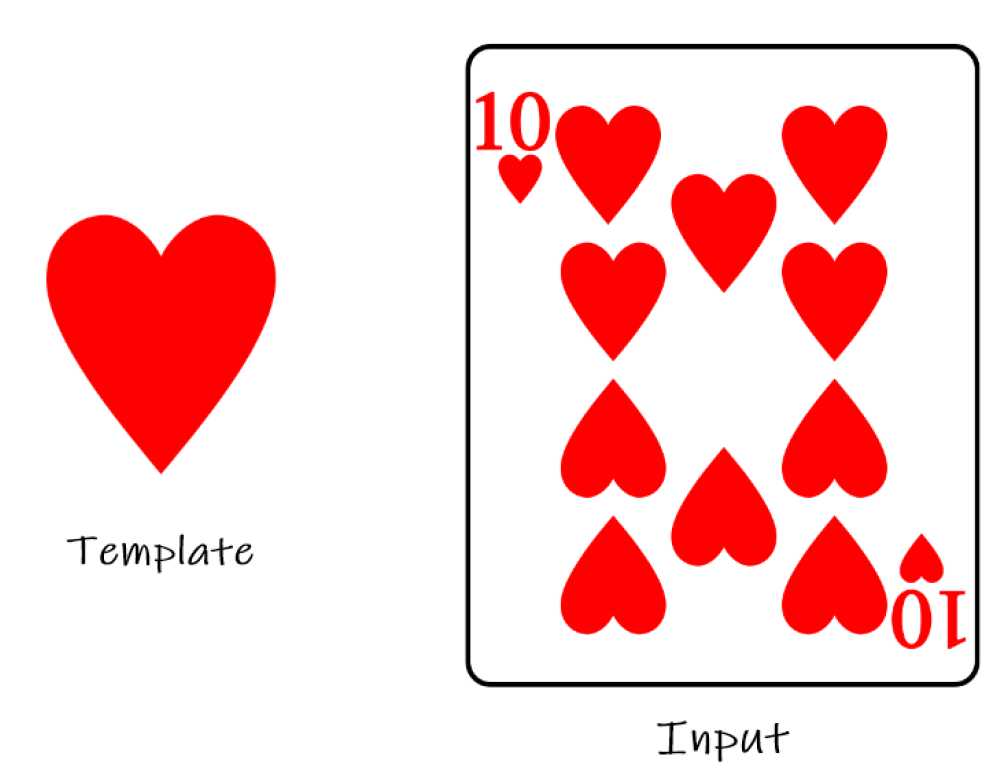
I primi sistemi di computer vision erano limitati dalla potenza di calcolo limitata dell'epoca. I computer negli anni '60 e '70 erano ingombranti, costosi e avevano capacità di elaborazione limitate.
Il deep learning e le Reti Neurali Convoluzionali (CNN) hanno segnato un momento cruciale nel campo della computer vision. Questi progressi hanno trasformato radicalmente il modo in cui i computer interpretano e analizzano i dati visivi, consentendo un'ampia gamma di applicazioni che prima si pensavano impossibili.
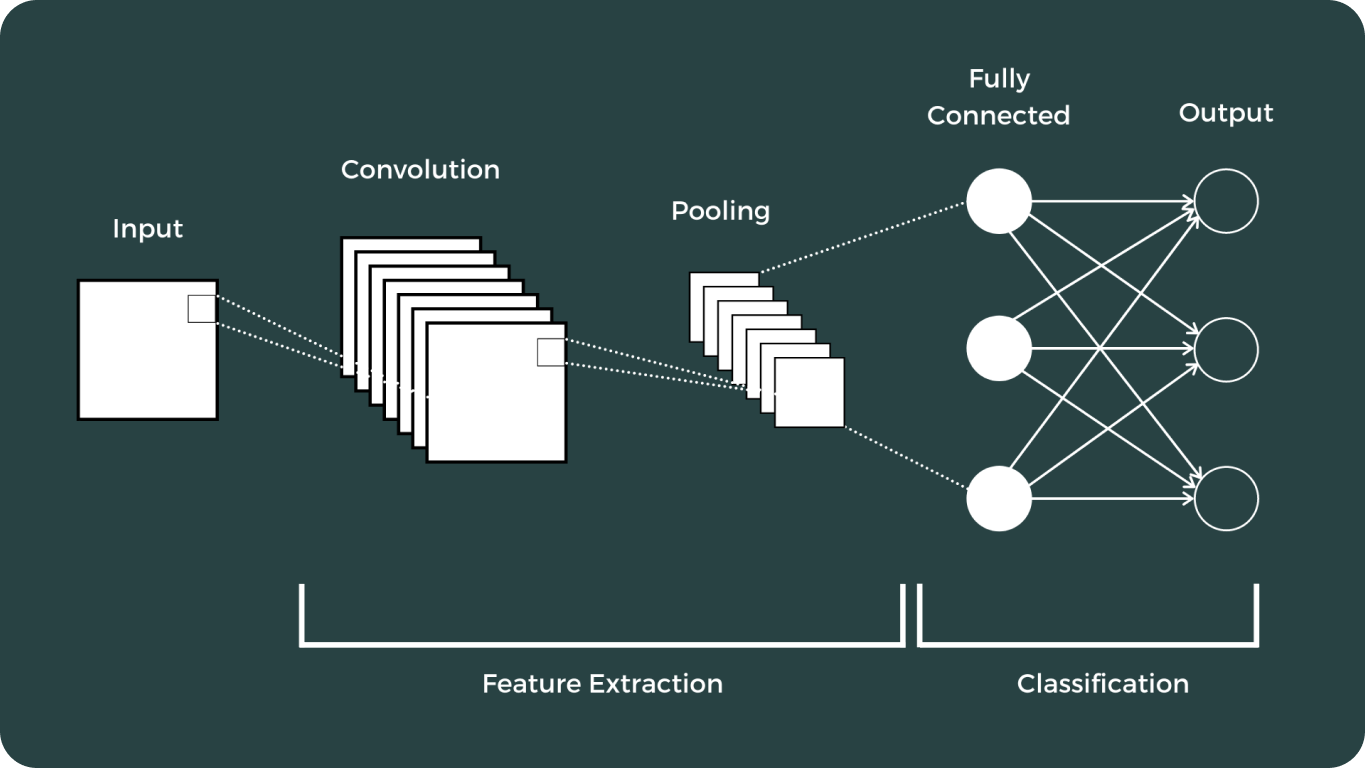
Il percorso dei modelli di visione è stato ampio, caratterizzato da alcuni dei più importanti:
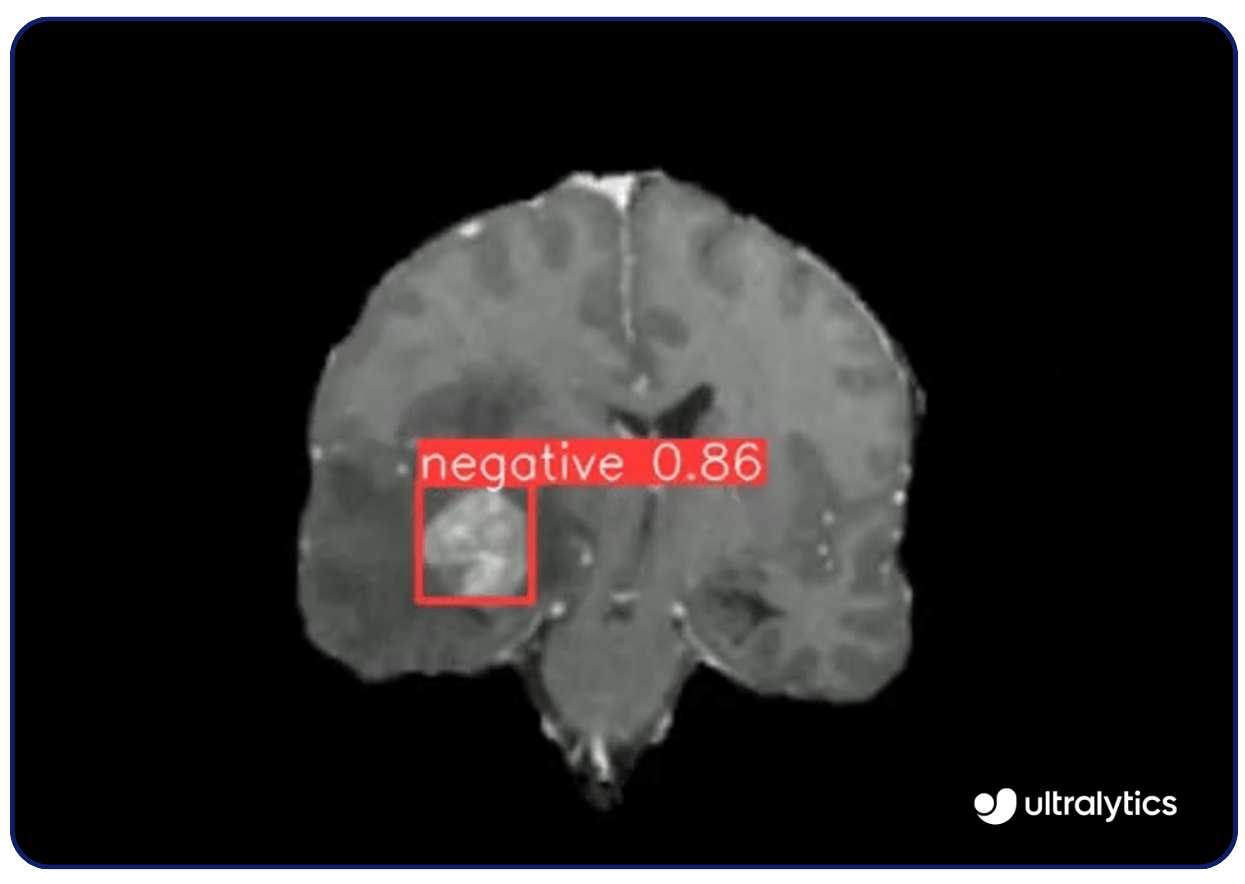
Gliusi della computer vision sono numerosi. Ad esempio, modelli di visione come Ultralytics YOLOv8 sono utilizzati nell'imaging medico per detect malattie come il cancro e la retinopatia diabetica. Analizzano radiografie, risonanze magnetiche e scansioni TC con grande precisione, identificando precocemente le anomalie. Questa capacità di rilevamento precoce consente di intervenire tempestivamente e di migliorare i risultati dei pazienti.
I modelli di visione computerizzata aiutano a monitorare e proteggere le specie in pericolo analizzando immagini e video degli habitat della fauna selvatica. Identificano e track comportamento degli animali, fornendo dati sulla loro popolazione e sui loro movimenti. Questa tecnologia informa le strategie di conservazione e le decisioni politiche per proteggere specie come tigri ed elefanti.
Con l'aiuto della vision AI, è possibile monitorare altre minacce ambientali come gli incendi boschivi e la deforestazione, garantendo tempi di risposta rapidi da parte delle autorità locali.

Anche se hanno già ottenuto risultati significativi, a causa della loro estrema complessità e della natura impegnativa del loro sviluppo, i modelli di visione devono affrontare numerose sfide che richiedono una ricerca continua e progressi futuri.
I modelli di visione, specialmente quelli di deep learning, sono spesso visti come "scatole nere" con trasparenza limitata. Ciò è dovuto alla loro incredibile complessità. La mancanza di interpretabilità ostacola la fiducia e la responsabilità, specialmente in applicazioni critiche come l'assistenza sanitaria, ad esempio.
L'addestramento e il deployment di modelli di IA all'avanguardia richiedono notevoli risorse computazionali. Ciò è particolarmente vero per i modelli di visione, che spesso richiedono l'elaborazione di grandi quantità di dati di immagini e video. Le immagini e i video ad alta definizione, essendo tra gli input di addestramento più intensivi in termini di dati, aumentano il carico computazionale. Ad esempio, una singola immagine HD può occupare diversi megabyte di spazio di archiviazione, rendendo il processo di addestramento dispendioso in termini di risorse e tempo.
Ciò richiede hardware potente e algoritmi di computer vision ottimizzati per gestire gli estesi dati e i complessi calcoli coinvolti nello sviluppo di modelli di visione efficaci. La ricerca su architetture più efficienti, la compressione dei modelli e gli acceleratori hardware come GPU e TPU sono aree chiave che faranno progredire il futuro dei modelli di visione.
Questi miglioramenti mirano a ridurre i requisiti computazionali e ad aumentare l'efficienza di elaborazione. Inoltre, sfruttando modelli avanzati pre-addestrati come YOLOv8 può ridurre significativamente la necessità di un addestramento estensivo, snellendo il processo di sviluppo e migliorando l'efficienza.
Oggigiorno, le applicazioni dei modelli di visione sono ampiamente diffuse, spaziando dall'assistenza sanitaria, come il rilevamento di tumori, agli usi quotidiani come il monitoraggio del traffico. Questi modelli avanzati hanno portato innovazione a innumerevoli settori fornendo maggiore accuratezza, efficienza e capacità che prima erano inimmaginabili.
Man mano che la tecnologia continua ad avanzare, il potenziale dei modelli di visione per innovare e migliorare vari aspetti della vita e dell'industria rimane illimitato. Questa continua evoluzione sottolinea l'importanza della continua ricerca e sviluppo nel campo della computer vision.
Siete curiosi di conoscere il futuro dell'IA visiva? Per ulteriori informazioni sugli ultimi progressi, esplorate i documenti diUltralytics e controllate i progetti su Ultralytics GitHub e YOLOv8 GitHub. Inoltre, per conoscere le applicazioni dell'IA in vari settori, le pagine delle soluzioni dedicate alle auto a guida autonoma e alla produzione offrono informazioni particolarmente utili.


