Cliccando su “Accetta tutti i cookie”, l'utente accetta di memorizzare i cookie sul proprio dispositivo per migliorare la navigazione del sito, analizzare l'utilizzo del sito e assistere le nostre attività di marketing. Maggiori informazioni
Impostazioni dei cookie
Cliccando su “Accetta tutti i cookie”, l'utente accetta di memorizzare i cookie sul proprio dispositivo per migliorare la navigazione del sito, analizzare l'utilizzo del sito e assistere le nostre attività di marketing. Maggiori informazioni
Unisciti a noi per dare uno sguardo all'evoluzione del rilevamento degli oggetti. Ci concentreremo sul modo in cui i modelli YOLO (You Only Look Once) sono progrediti negli ultimi anni.
La computer vision è un sottocampo dell'intelligenza artificiale (AI) che si concentra sull'insegnamento alle macchine di vedere e comprendere immagini e video, in modo simile a come gli umani percepiscono il mondo reale. Mentre riconoscere oggetti o identificare azioni è naturale per gli esseri umani, queste attività richiedono tecniche di computer vision specifiche e specializzate quando si tratta di macchine. Ad esempio, un'attività chiave nella computer vision è il rilevamento oggetti, che implica l'identificazione e la localizzazione di oggetti all'interno di immagini o video.
Fin dagli anni '60, i ricercatori hanno lavorato per migliorare il modo in cui i computer possono detect gli oggetti. I primi metodi, come la corrispondenza dei modelli, consistevano nel far scorrere un modello predefinito su un'immagine per trovare le corrispondenze. Pur essendo innovativi, questi approcci si scontravano con le variazioni di dimensioni, orientamento e illuminazione degli oggetti. Oggi disponiamo di modelli avanzati come Ultralytics YOLO11 in grado di detect anche oggetti piccoli e parzialmente nascosti, noti come oggetti occlusi, con una precisione impressionante.
Prima di immergerci nel rilevamento degli oggetti, diamo un'occhiata a come è nata la computer vision. Le origini della computer vision risalgono alla fine degli anni Cinquanta e all'inizio degli anni Sessanta, quando gli scienziati iniziarono a esplorare il modo in cui il cervello elabora le informazioni visive. In esperimenti con i gatti, i ricercatori David Hubel e Torsten Wiesel scoprirono che il cervello reagisce a modelli semplici come bordi e linee. Da qui è nata l'idea dell'estrazione delle caratteristiche, ovvero il concetto che i sistemi visivi detect e riconoscono le caratteristiche di base delle immagini, come i bordi, prima di passare a modelli più complessi.
Fig 1. Imparare come il cervello di un gatto reagisce alle barre luminose ha aiutato a sviluppare l'estrazione di feature nella computer vision.
Nello stesso periodo, è emersa una nuova tecnologia in grado di trasformare le immagini fisiche in formati digitali, suscitando interesse su come le macchine potessero elaborare le informazioni visive. Nel 1966, il Summer Vision Project del Massachusetts Institute of Technology (MIT) ha spinto ulteriormente le cose. Sebbene il progetto non sia riuscito completamente, mirava a creare un sistema in grado di separare il primo piano dallo sfondo nelle immagini. Per molti nella comunità Vision AI, questo progetto segna l'inizio ufficiale della computer vision come campo scientifico.
Comprendere la storia del rilevamento oggetti
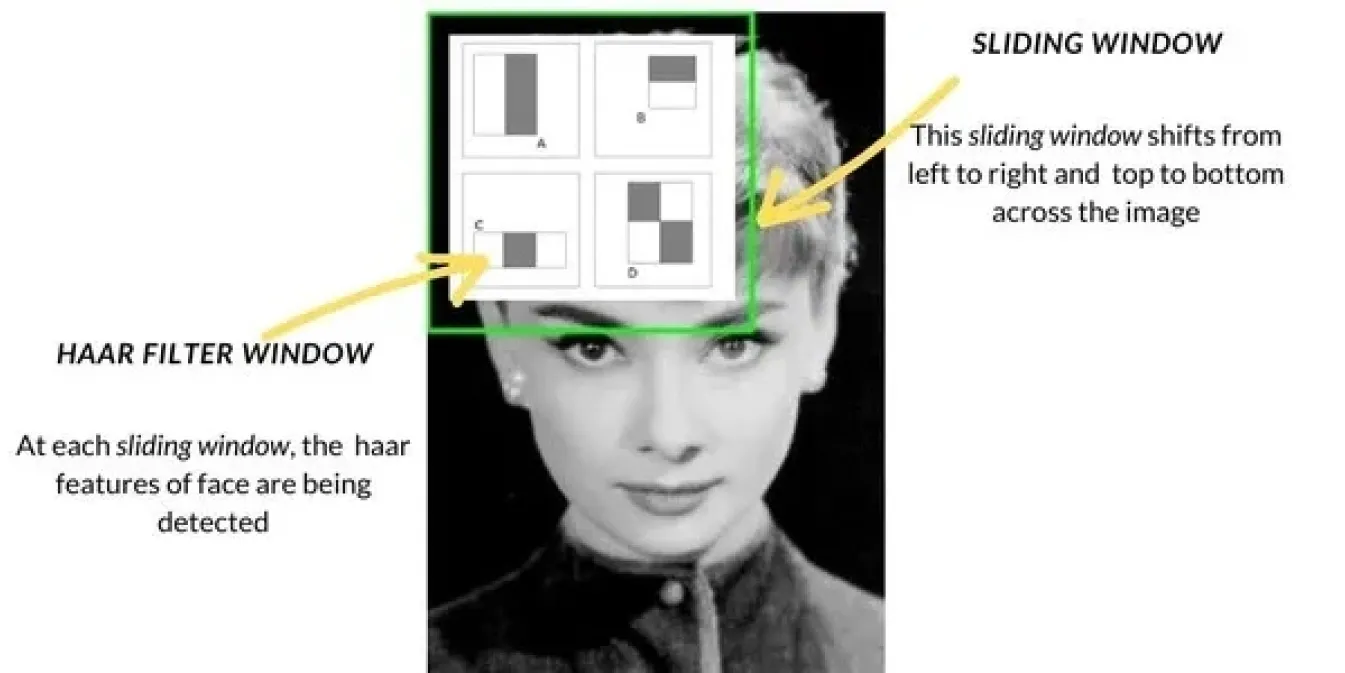
Con il progredire della computer vision tra la fine degli anni Novanta e l'inizio degli anni Duemila, i metodi di rilevamento degli oggetti sono passati da tecniche di base come la corrispondenza dei modelli ad approcci più avanzati. Uno dei metodi più diffusi è stato Haar Cascade, che è stato ampiamente utilizzato per compiti come il rilevamento dei volti. Funziona scansionando le immagini con una finestra scorrevole, verificando la presenza di caratteristiche specifiche come bordi o texture in ogni sezione dell'immagine e quindi combinando queste caratteristiche per detect oggetti come i volti. Haar Cascade era molto più veloce dei metodi precedenti.
Fig 2. Utilizzo di Haar Cascade per il rilevamento dei volti.
Accanto a questi, sono stati introdotti anche metodi come l'Histogram of Oriented Gradients (HOG) e le Support Vector Machines (SVM). HOG utilizzava la tecnica della finestra scorrevole per analizzare come la luce e le ombre cambiavano in piccole sezioni di un'immagine, aiutando a identificare oggetti in base alle loro forme. Le SVM hanno quindi classificato queste caratteristiche per determinare l'identità dell'oggetto. Questi metodi hanno migliorato la precisione, ma hanno comunque avuto difficoltà negli ambienti del mondo reale ed erano più lenti rispetto alle tecniche odierne.
La necessità di rilevamento oggetti in tempo reale
Negli anni 2010, l'ascesa del deep learning e delle reti neurali convoluzionali (CNN) ha portato a un importante cambiamento nel rilevamento oggetti. Le CNN hanno reso possibile ai computer apprendere automaticamente caratteristiche importanti da grandi quantità di dati, il che ha reso il rilevamento molto più accurato.
Tuttavia, questi modelli erano lenti perché elaboravano le immagini in più fasi, rendendoli impraticabili per applicazioni in tempo reale in aree come le auto a guida autonoma o la videosorveglianza.
Con l'obiettivo di accelerare le cose, sono stati sviluppati modelli più efficienti. Modelli come Fast R-CNN e Faster R-CNN hanno aiutato a perfezionare il modo in cui venivano scelte le regioni di interesse e a ridurre il numero di passaggi necessari per il rilevamento. Sebbene ciò abbia reso più veloce il rilevamento oggetti, non era ancora abbastanza rapido per molte applicazioni del mondo reale che necessitavano di risultati immediati. La crescente domanda di rilevamento in tempo reale ha spinto lo sviluppo di soluzioni ancora più veloci ed efficienti in grado di bilanciare velocità e precisione.
Fig. 3. Confronto delle velocità di R-CNN, Fast R-CNN e Faster R-CNN.
Modelli YOLO (You Only Look Once): Un'importante pietra miliare
YOLO è un modello di rilevamento degli oggetti che ha ridefinito la computer vision consentendo il rilevamento in tempo reale di più oggetti in immagini e video, rendendolo unico rispetto ai metodi di rilevamento precedenti. Invece di analizzare ogni singolo oggetto rilevato, l'architettura diYOLO tratta il rilevamento degli oggetti come un'unica attività, prevedendo sia la posizione che la classe degli oggetti in un'unica soluzione utilizzando le CNN.
Il modello funziona dividendo un'immagine in una griglia, con ogni parte responsabile del rilevamento degli oggetti nella sua rispettiva area. Effettua più previsioni per ogni sezione e filtra i risultati meno attendibili, mantenendo solo quelli accurati.
L'introduzione di YOLO nelle applicazioni di computer vision ha reso il rilevamento degli oggetti molto più veloce ed efficiente rispetto ai modelli precedenti. Grazie alla sua velocità e precisione, YOLO è diventato rapidamente una scelta popolare per le soluzioni in tempo reale in settori come la produzione, la sanità e la robotica.
Un altro aspetto importante da sottolineare è che, essendo YOLO open-source, gli sviluppatori e i ricercatori hanno potuto migliorarlo continuamente, portando a versioni ancora più avanzate.
Il percorso da YOLO a YOLO11
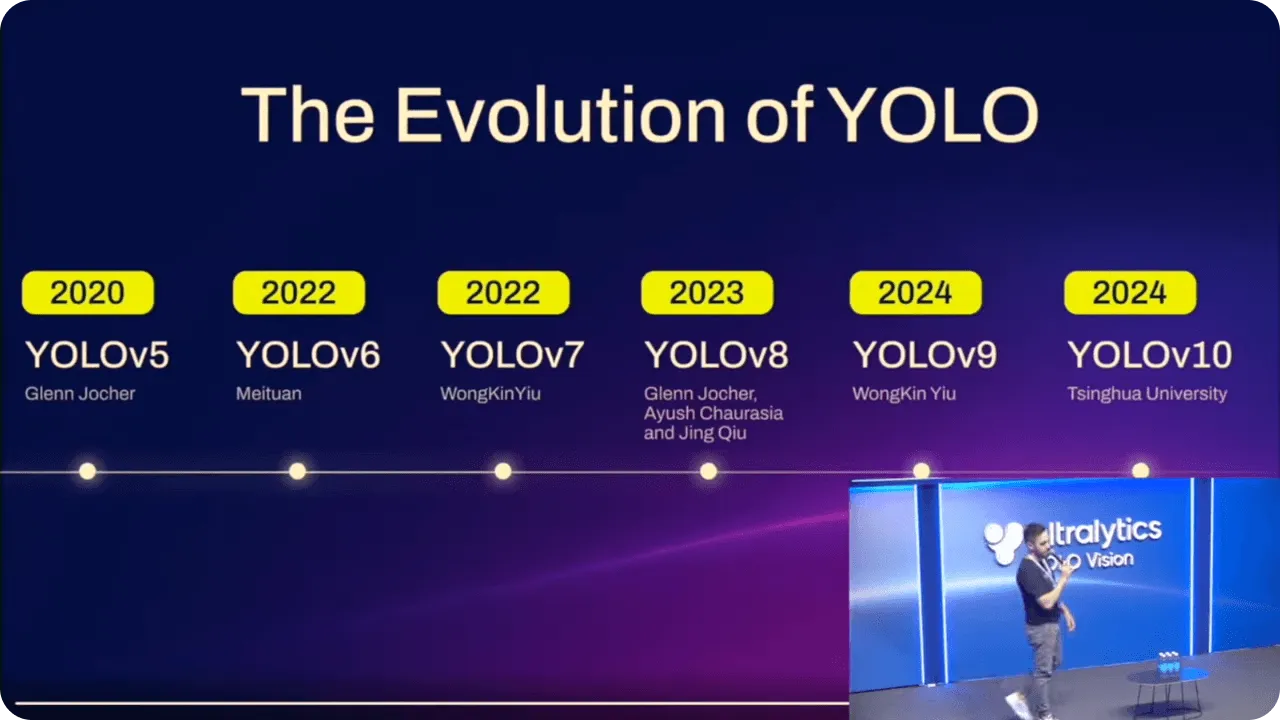
I modelli YOLO sono stati costantemente migliorati nel corso del tempo, sfruttando i progressi di ogni versione. Oltre a migliorare le prestazioni, questi miglioramenti hanno reso i modelli più facili da usare per persone con diversi livelli di esperienza tecnica.
Ad esempio, quando Ultralytics YOLOv5 è stato introdotto, l'implementazione dei modelli è diventata più semplice con PyTorchconsentendo a una gamma più ampia di utenti di lavorare con l'IA avanzata. Ha unito precisione e usabilità, offrendo a un maggior numero di persone la possibilità di implementare il rilevamento degli oggetti senza dover essere esperti di codifica.
Figura 5. Evoluzione dei modelli YOLO .
Ultralytics YOLOv8 ha proseguito questi progressi aggiungendo il supporto per attività come la segmentazione delle istanze e rendendo i modelli più flessibili. È diventato più facile utilizzare YOLO sia per le applicazioni di base che per quelle più complesse, rendendolo utile in una vasta gamma di scenari.
Con l'ultimo modello, Ultralytics YOLO11sono state apportate ulteriori ottimizzazioni. Riducendo il numero di parametri e migliorando l'accuratezza, è ora più efficiente per le attività in tempo reale. Che siate sviluppatori esperti o alle prime armi con l'intelligenza artificiale, YOLO11 offre un approccio avanzato al rilevamento degli oggetti facilmente accessibile.
Conoscere YOLO11: nuove funzionalità e miglioramenti
YOLO11, lanciato in occasione dell'evento ibrido annuale di Ultralytics, YOLO Vision 2024 (YV24), supporta le stesse attività di computer vision di YOLOv8, come il rilevamento degli oggetti, la segmentazione delle istanze, la classificazione delle immagini e la stima della posa. Gli utenti possono quindi passare facilmente a questo nuovo modello senza dover modificare i propri flussi di lavoro. Inoltre, l'architettura aggiornata di YOLO11rende le previsioni ancora più precise. Infatti, YOLO11m raggiunge una precisione media superioremAP) sul set di datiCOCO con il 22% di parametri in meno rispetto a YOLOv8m.
YOLO11 è inoltre costruito per funzionare in modo efficiente su una serie di piattaforme, dagli smartphone e altri dispositivi edge ai sistemi cloud più potenti. Questa flessibilità garantisce prestazioni uniformi su diverse configurazioni hardware per le applicazioni in tempo reale. Inoltre, YOLO11 è più veloce ed efficiente, riducendo i costi di calcolo e accelerando i tempi di inferenza. Sia che si utilizzi il pacchettoUltralytics Python o l' Ultralytics HUB senza codice, è facile integrare YOLO11 nei flussi di lavoro esistenti.
Il futuro dei modelli YOLO e del rilevamento degli oggetti
L'impatto del rilevamento avanzato degli oggetti sulle applicazioni in tempo reale e sull'IA di frontiera si fa già sentire in tutti i settori. Poiché settori come il petrolio e il gas, la sanità e la vendita al dettaglio si affidano sempre più all'IA, la richiesta di un rilevamento rapido e preciso degli oggetti continua a crescere. YOLO11 intende rispondere a questa esigenza consentendo un rilevamento ad alte prestazioni anche su dispositivi con potenza di calcolo limitata.
Con la crescita dell'intelligenza artificiale, è probabile che i modelli di rilevamento degli oggetti come YOLO11 diventino ancora più essenziali per il processo decisionale in tempo reale in ambienti in cui velocità e precisione sono fondamentali. Con i continui miglioramenti nella progettazione e nell'adattabilità, il futuro del rilevamento degli oggetti sembra destinato a portare ancora più innovazioni in una varietà di applicazioni.
Punti chiave
Il rilevamento degli oggetti ha fatto molta strada, evolvendo da metodi semplici alle tecniche avanzate di deep-learning che vediamo oggi. I modelli YOLO sono stati al centro di questo progresso, offrendo un rilevamento in tempo reale più rapido e accurato in diversi settori. YOLO11 si basa su questa eredità, migliorando l'efficienza, riducendo i costi di calcolo e aumentando la precisione, rendendolo una scelta affidabile per una varietà di applicazioni in tempo reale. Con i continui progressi nel campo dell'intelligenza artificiale e della computer vision, il futuro del rilevamento degli oggetti appare luminoso, con spazio per ulteriori miglioramenti in termini di velocità, precisione e adattabilità.
Sei curioso sull'AI? Rimani connesso con la nostra community per continuare a imparare! Dai un'occhiata al nostro repository GitHub per scoprire come stiamo utilizzando l'AI per creare soluzioni innovative in settori come il manufacturing e l'healthcare. 🚀








.webp)

.webp)