Cliccando su “Accetta tutti i cookie”, l'utente accetta di memorizzare i cookie sul proprio dispositivo per migliorare la navigazione del sito, analizzare l'utilizzo del sito e assistere le nostre attività di marketing. Maggiori informazioni
Impostazioni dei cookie
Cliccando su “Accetta tutti i cookie”, l'utente accetta di memorizzare i cookie sul proprio dispositivo per migliorare la navigazione del sito, analizzare l'utilizzo del sito e assistere le nostre attività di marketing. Maggiori informazioni
Unisciti a noi mentre esploriamo come i modelli di diffusione possono essere utilizzati per creare contenuti realistici e ridefinire campi come il design, la musica e il cinema con varie applicazioni.
L'utilizzo di strumenti di AI generativa come Midjourney e Sora per creare contenuti sta diventando sempre più comune e c'è un crescente interesse nell'esaminare il funzionamento interno di questi strumenti. Infatti, un recente studio dimostra che il 94% degli individui è disposto ad apprendere nuove competenze per lavorare con l'AI generativa. Comprendere come funzionano i modelli di AI generativa può aiutarti a utilizzare questi strumenti in modo più efficace e a ottenere il massimo da essi.
Al centro di strumenti come Midjourney e Sora ci sono modelli di diffusione avanzati: modelli di IA generativa in grado di creare immagini, video, testo e audio per varie applicazioni. Ad esempio, i modelli di diffusione sono un'ottima opzione per produrre brevi video di marketing per piattaforme di social media come TikTok e YouTube Shorts. In questo articolo esploreremo come funzionano i modelli di diffusione e dove possono essere utilizzati. Iniziamo!
L'ispirazione alla base dei modelli di diffusione avanzati
In fisica, la diffusione è il processo mediante il quale le molecole si espandono da aree ad alta concentrazione ad aree a bassa concentrazione. Il concetto di diffusione è strettamente correlato al moto browniano, in cui le particelle si muovono in modo casuale mentre collidono con le molecole in un fluido e si diffondono gradualmente nel tempo.
Questi concetti hanno ispirato lo sviluppo di modelli di diffusione nell'AI generativa. I modelli di diffusione funzionano aggiungendo gradualmente rumore ai dati e quindi imparando a invertire tale processo per generare nuovi dati di alta qualità come testo, immagini o suoni. È simile all'idea di diffusione inversa nella fisica. Teoricamente, la diffusione può essere tracciata a ritroso per riportare le particelle al loro stato originale. Allo stesso modo, i modelli di diffusione imparano a invertire il rumore aggiunto per creare nuovi dati realistici da input rumorosi.
Uno sguardo sotto il cofano dei modelli di diffusione
Generalmente, l'architettura di un modello di diffusione prevede due passaggi principali. Innanzitutto, il modello impara ad aggiungere gradualmente rumore al dataset. Quindi, viene addestrato per invertire questo processo e riportare i dati al loro stato originale. Diamo un'occhiata più da vicino a come funziona.
Pre-elaborazione dei dati
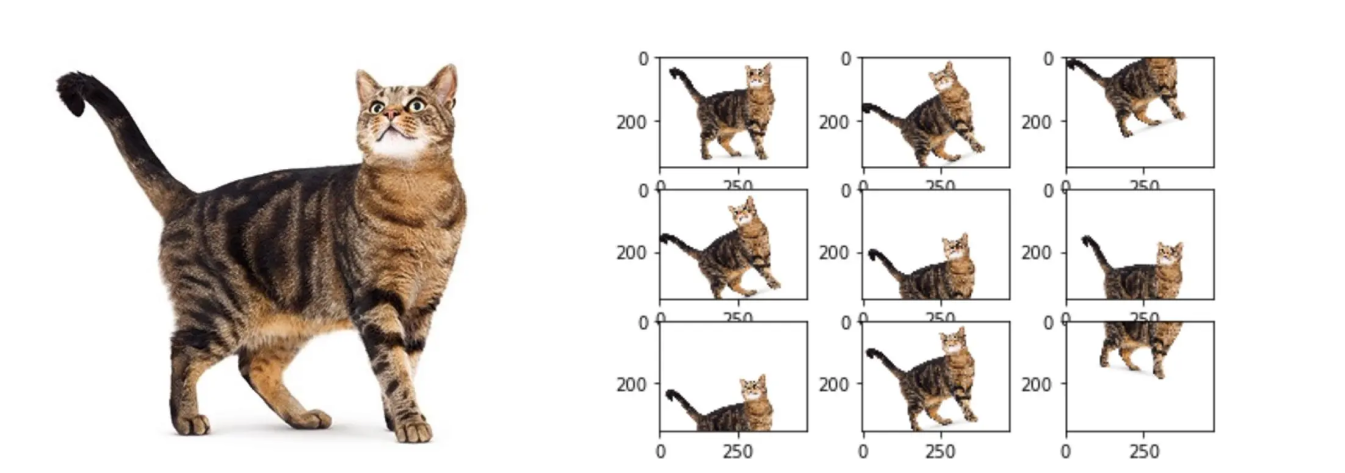
Prima di addentrarci nel cuore di un modello di diffusione, è importante ricordare che tutti i dati su cui il modello viene addestrato devono essere preelaborati. Ad esempio, se si sta addestrando un modello di diffusione per generare immagini, il dataset di immagini di addestramento deve essere prima ripulito. La preelaborazione dei dati delle immagini può comportare la rimozione di eventuali outlier che potrebbero influire sui risultati, la normalizzazione dei valori dei pixel in modo che tutte le immagini siano sulla stessa scala e l'utilizzo dell'aumento dei dati per introdurre più varietà. I passaggi di preelaborazione dei dati aiutano a garantire la qualità dei dati di addestramento, e questo vale non solo per i modelli di diffusione ma per qualsiasi modello di AI.
Fig. 2. Esempi di data augmentation delle immagini.
Processo di diffusione in avanti
Dopo la pre-elaborazione dei dati, il passo successivo è il processo di diffusione in avanti. Concentriamoci sull'addestramento di un modello di diffusione per generare immagini. Il processo inizia campionando da una distribuzione semplice, come una distribuzione gaussiana. In altre parole, viene selezionato del rumore casuale. Come mostrato nell'immagine sottostante, il modello trasforma gradualmente l'immagine in una serie di passaggi. L'immagine inizia chiara e diventa sempre più rumorosa man mano che avanza attraverso ogni passaggio, trasformandosi infine in rumore quasi completo alla fine.
Ogni passaggio si basa sul precedente e il rumore viene aggiunto in modo controllato e incrementale utilizzando una catena di Markov. Una catena di Markov è un modello matematico in cui la probabilità dello stato successivo dipende solo dallo stato attuale. Viene utilizzato per prevedere i risultati futuri in base alle condizioni presenti. Man mano che ogni passaggio aggiunge complessità ai dati, possiamo catturare i modelli e i dettagli più intricati della distribuzione dei dati dell'immagine originale. L'aggiunta di rumore gaussiano genera anche campioni diversi e realistici man mano che la diffusione si sviluppa.
Processo di diffusione inversa
Il processo di diffusione inversa inizia una volta che il processo di diffusione in avanti ha trasformato un campione in uno stato rumoroso e complesso. Mappa gradualmente il campione rumoroso al suo stato originale utilizzando una serie di trasformazioni inverse. I passaggi che invertono il processo di aggiunta del rumore sono guidati da una catena di Markov inversa.
Durante il processo inverso, i modelli di diffusione imparano a generare nuovi dati partendo da un campione di rumore casuale e affinandolo gradualmente in un output chiaro e dettagliato. I dati generati finiscono per assomigliare molto al set di dati originale. Questa capacità è ciò che rende i modelli di diffusione ottimi per attività come la sintesi di immagini, il completamento dei dati e la riduzione del rumore. Nella prossima sezione, esploreremo altre applicazioni dei modelli di diffusione.
Le applicazioni dei modelli di diffusione
Il processo di diffusione graduale consente al modello di diffusione di generare in modo efficiente distribuzioni di dati complesse senza essere sopraffatto dall'elevata dimensionalità dei dati. Diamo un'occhiata ad alcune applicazioni in cui i modelli di diffusione eccellono.
Grafica
I modelli di diffusione possono essere utilizzati per generare rapidamente contenuti visivi grafici. Designer e artisti possono fornire schizzi, layout o anche alcune semplici idee di massima di ciò che vogliono, e i modelli possono dare vita a queste idee. Questo può accelerare l'intero processo di progettazione, offrire una vasta gamma di nuove possibilità dal concetto iniziale al prodotto finale e risparmiare molto tempo prezioso per i designer.
Fig. 5. Progetti grafici creati tramite modelli di diffusione.
Musica e sound design
I modelli di diffusione possono anche essere adattati per generare paesaggi sonori o note musicali uniche. Offrono nuovi modi per musicisti e artisti di visualizzare e creare esperienze uditive. Ecco alcuni dei casi d'uso dei modelli di diffusione nel campo della creazione di suoni e musica:
Trasferimento vocale: I modelli di diffusione possono essere utilizzati per trasformare un suono in un altro, come convertire un campione di cassa in un suono di rullante per combinazioni sonore uniche.
Variabilità del suono e umanizzazione: La diffusione audio può apportare leggere variazioni ai suoni per aggiungere un elemento umano all'audio digitale simulando le performance di strumenti dal vivo.
Regolazioni del sound design: Questi modelli possono essere utilizzati per alterare sottilmente un suono (come migliorare un campione di una porta che sbatte) per modificarne le caratteristiche a un livello più profondo rispetto all'EQ o al filtraggio tradizionali.
Generazione di melodie: Possono anche aiutare a generare nuove melodie e ispirare gli artisti in un modo simile alla navigazione tra pacchetti di sample.
Fig. 6. Una visualizzazione della diffusione audio.
Film e animazione
Un altro caso d'uso interessante dei modelli di diffusione è nella creazione di clip cinematografiche e di animazione. Possono essere utilizzati per generare personaggi, sfondi realistici e persino elementi dinamici all'interno delle scene. L'utilizzo di modelli di diffusione può essere un grande vantaggio per le società di produzione. Semplifica il flusso di lavoro complessivo e apre la strada a una maggiore sperimentazione e creatività nella narrazione visiva. Alcune delle clip realizzate con questi modelli sono paragonabili a clip animate o cinematografiche reali. È anche possibile utilizzare questi modelli per creare interi film.
Fig. 7. Una scena dal cortometraggio Seasons creato utilizzando modelli di diffusione.
Modelli di diffusione popolari
Ora che abbiamo imparato alcune delle applicazioni dei modelli di diffusione, diamo un'occhiata ad alcuni modelli di diffusione popolari che puoi provare a utilizzare.
Diffusione stabile: Creato da Stability AI, Stable Diffusion è un modello efficiente noto per la conversione di messaggi di testo in immagini realistiche. Ha una solida reputazione per la generazione di immagini di alta qualità. Può anche essere modificato per film e animazioni.
DALL-E 3: DALL-E 3 è l'ultima versione del modello di generazione di immagini di OpenAI. È integrato in ChatGPTe offre molti miglioramenti nella qualità della generazione di immagini rispetto alla versione precedente, DALL-E 2.
Sora: Sora è il modello text-to-video di OpenAI in grado di generare video a 1080p altamente realistici della durata massima di un minuto. Alcune delle clip video realizzate con Sora possono essere facilmente scambiate per filmati reali.
Immagine: Sviluppato da Google, Imagen è un modello di diffusione da testo a immagine riconosciuto per il suo fotorealismo e la comprensione avanzata del linguaggio.
Sfide e limitazioni relative ai modelli di diffusione
Sebbene i modelli di diffusione offrano vantaggi in molti settori, è necessario tenere presenti alcune delle sfide che comportano. Una sfida è che il processo di training richiede molte risorse. Sebbene i progressi nell'accelerazione hardware possano essere d'aiuto, possono essere costosi. Un altro problema è la limitata capacità dei modelli di diffusione di generalizzare a dati non visti. Adattarli a domini specifici può richiedere molto fine-tuning o un nuovo training.
L'integrazione di questi modelli in attività del mondo reale comporta una serie di sfide. È fondamentale che ciò che l'IA genera corrisponda effettivamente a ciò che intendono gli umani. Ci sono anche preoccupazioni etiche, come il rischio che questi modelli acquisiscano e riflettano i pregiudizi dai dati su cui sono addestrati. Inoltre, la gestione delle aspettative degli utenti e il costante perfezionamento dei modelli in base al feedback possono diventare uno sforzo continuo per garantire che questi strumenti siano il più efficaci e affidabili possibile.
Il futuro dei modelli di diffusione
I modelli di diffusione sono un concetto affascinante nell'IA generativa che aiuta a creare immagini, video e suoni di alta qualità in molti campi diversi. Sebbene possano presentare alcune sfide di implementazione, come le esigenze computazionali e le preoccupazioni etiche, la comunità dell'IA lavora costantemente per migliorare la loro efficienza e il loro impatto. I modelli di diffusione sono pronti a trasformare settori come il cinema, la produzione musicale e la creazione di contenuti digitali man mano che continuano a evolversi.
Impariamo ed esploriamo insieme! Dai un'occhiata al nostro repository GitHub per vedere i nostri contributi all'IA. Scopri come stiamo ridefinendo settori come il manufacturing e l'healthcare con una tecnologia AI all'avanguardia.







.png)