



憲法AIが、モデルが倫理的なルールに従い、より安全な意思決定を行い、言語およびコンピュータビジョンシステムにおける公平性をどのように支援するかを学びます。

憲法AIが、モデルが倫理的なルールに従い、より安全な意思決定を行い、言語およびコンピュータビジョンシステムにおける公平性をどのように支援するかを学びます。
人工知能(AI)は急速に私たちの日常生活に欠かせないものとなりつつあります。ヘルスケア、採用、金融、公共の安全などの分野で使用されるツールに組み込まれています。これらのシステムが拡大するにつれて、その倫理と信頼性に対する懸念も高まっています。
たとえば、公平性や安全性を考慮せずに構築されたAIシステムは、偏った、または信頼できない結果を生み出すことがあります。これは、多くのモデルが依然として人間の価値観を明確に反映し、整合させる方法を持っていないためです。
これらの課題に対処するために、研究者たちは現在、憲法AIとして知られるアプローチを模索しています。簡単に言うと、モデルのトレーニングプロセスに書かれた一連の原則を導入します。これらの原則は、モデルが自身の行動を判断し、人間のフィードバックへの依存を減らし、応答をより安全で理解しやすいものにするのに役立ちます。
これまでのところ、このアプローチは主に大規模言語モデル(LLM)に関して使用されてきました。ただし、同じ構造が、コンピュータビジョンシステムが視覚データを分析する際に倫理的な意思決定を行うのを支援する可能性があります。
この記事では、憲法AIの仕組みを探り、実際の例を見て、コンピュータビジョンシステムにおける潜在的な応用について説明します。
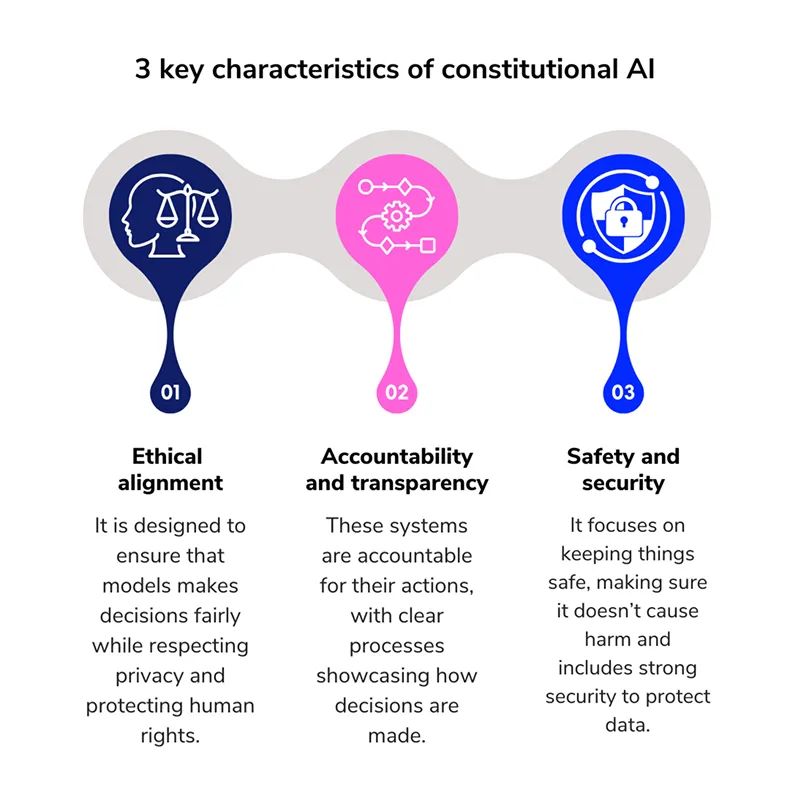
憲法AIは、明確な倫理規則のセットを提供することにより、AIモデルの動作を導くモデルトレーニング手法です。これらの規則は、行動規範として機能します。モデルが何が許容されるかを推測するのではなく、トレーニング中にその応答を形作る書かれた一連の原則に従います。
この概念は Anthropicによって導入されたもので、AIシステムの意思決定をより自己監視的にする方法としてクロードLLMファミリーを開発した。
人間のフィードバックだけに頼るのではなく、モデルは事前に定義された一連の原則に基づいて、自身の応答を批判し、改善することを学習します。このアプローチは、裁判官が判決を下す前に憲法を参照する法制度に似ています。
この場合、モデルは審査員であると同時に生徒となり、同じルールセットを使って自らの行動を見直し、改良する。このプロセスは、AIモデルのアライメントを強化し、安全で責任あるAIシステムの開発をサポートする。
コンスティチューショナルAIの目標は、明確に定められた一連のルールに従うことで、AIモデルが安全かつ公正な判断を下せるように学習させることです。以下に、このプロセスの簡単な内訳を示します。
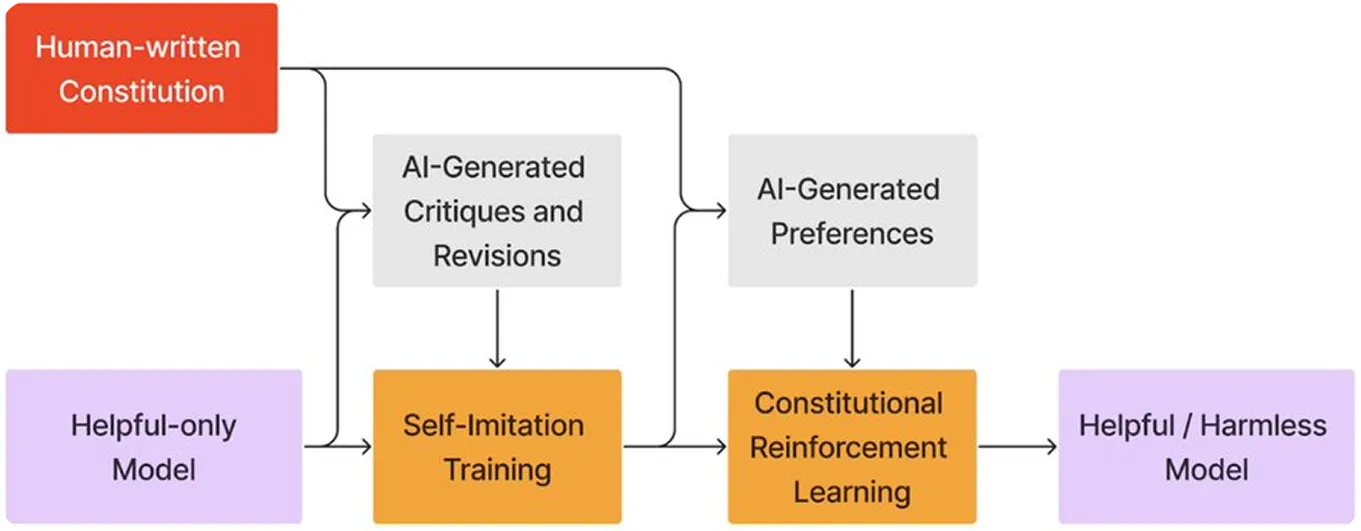
AIモデルが倫理的なルールに従うためには、まずそれらのルールを明確に定義する必要があります。コンスティチューショナルAIの場合、これらのルールは一連の中核原則に基づいています。
たとえば、効果的なAI憲法の基礎となる4つの原則を以下に示します。
コンスティテューショナルAIは理論から実践へと移行し、現在では数百万人のユーザーと対話する大規模なモデルで徐々に使われるようになっている。最も一般的な2つの例は、OpenAIと AnthropicLLMである。
どちらの組織も、より倫理的なAIシステムを作成するために異なるアプローチを採用していますが、共通の考え方を共有しています。それは、モデルに一連の書かれた指針原則に従うように教えることです。これらの例を詳しく見てみましょう。
OpenAIはChatGPT モデルのトレーニングプロセスの一環として、Model Specと呼ばれる文書を導入した。この文書は憲法のような役割を果たします。親切、誠実、安全といった価値観を含め、モデルが応答において何を目指すべきかを概説しています。また、有害な出力や誤解を招く出力として何がカウントされるかを定義しています。
このフレームワークは、OpenAIのモデルを微調整するために使用されている。時間をかけて、これは ChatGPTを形成するのに役立っています。

Anthropicモデルであるクロードが従う憲法は、世界人権宣言のような情報源からの倫理原則、アップルの利用規約のようなプラットフォームのガイドライン、そして他のAI研究所の研究に基づいている。これらの原則は、クロードの反応が安全で公正で、人間の重要な価値観に沿ったものであることを保証するのに役立つ。
Claudeは、人間のフィードバックに頼るのではなく、AIフィードバックからの強化学習(RLAIF)も使用します。ここでは、これらの倫理ガイドラインに基づいて自身の応答をレビューおよび調整します。このプロセスにより、Claudeは時間の経過とともに改善し、トリッキーな状況でも、よりスケーラブルになり、役立つ、倫理的、および無害な回答を提供できるようになります。
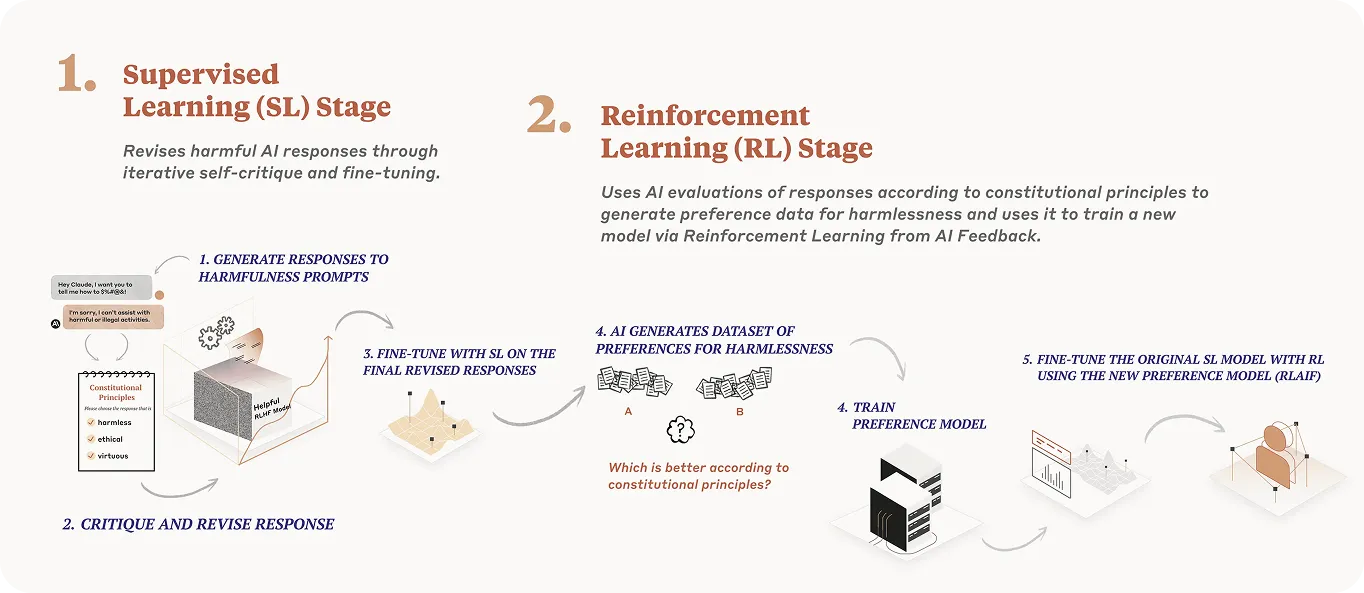
コンスティチューショナルAIが言語モデルの挙動に良い影響を与えていることから、同様のアプローチが、画像に基づくシステムがより公平かつ安全に対応するのに役立つのではないかという疑問が生じるのは自然な流れです。
コンピュータビジョンモデルはテキストではなく画像を扱うものですが、倫理的な指針の必要性は同様に重要です。例えば、公平性とバイアスは考慮すべき重要な要素であり、これらのシステムは、すべての人を平等に扱い、視覚データを分析する際に有害または不当な結果を避けるように訓練される必要があります。
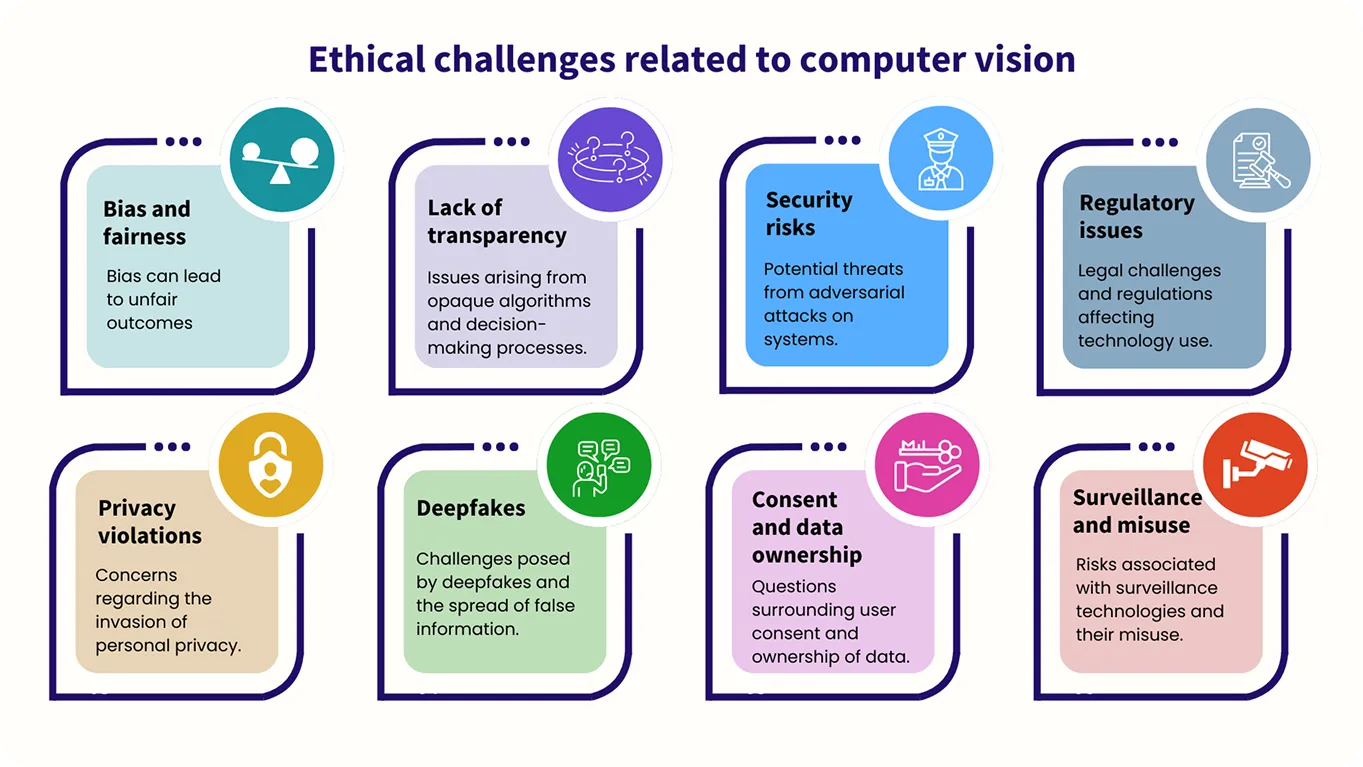
現時点では、コンピュータビジョンにおけるコンスティチューショナルAIの利用はまだ研究段階であり、この分野では継続的な研究が行われています。
例えば、Metaは最近、コンスティチューショナルAIのような推論を画像安全タスクに適用するフレームワークであるCLUEを発表しました。これは、広範な安全ルールを、マルチモーダルAI(複数の種類のデータを処理および理解するAIシステム)が従うことができる正確なステップに変換します。これにより、システムはより明確に推論し、有害な結果を減らすことができます。
また、CLUEは複雑なルールを簡素化することで、画像安全性の判断をより効率的にし、AIモデルが広範な人的入力を必要とせずに、迅速かつ正確に行動できるようにします。一連の指針となる原則を使用することで、CLUEは画像モデレーションシステムをよりスケーラブルにすると同時に、高品質の結果を保証します。
AIシステムがより多くの責任を担うようになるにつれて、焦点は単に何ができるかから、何をすべきかに移行しています。この移行は、これらのシステムが医療、法執行、教育など、人々の生活に直接影響を与える分野で使用されているため、非常に重要です。
AIシステムが適切かつ倫理的に行動することを保証するためには、強固で一貫性のある基盤が必要です。この基盤は、公平性、安全性、信頼性を優先する必要があります。
書かれた憲章は、トレーニング中にその基盤を提供し、システムの意思決定プロセスを導くことができます。また、開発者に対して、展開後にシステムの挙動をレビューおよび調整するためのフレームワークを提供し、システムが当初意図した価値観に沿い続け、新たな課題が発生した場合にも適応しやすくすることができます。
成長を続けるコミュニティに今すぐ参加しましょう!GitHubリポジトリを探索して、AIについてさらに深く掘り下げてください。独自のコンピュータビジョンプロジェクトを構築してみませんか?ライセンスオプションをご覧ください。医療におけるコンピュータビジョンがどのように効率を改善しているか、ソリューションページにアクセスして製造業におけるAIの影響について学びましょう!


.webp)