



YOLO、テキストプロンプトからオブジェクトを識別できる革新的なオブジェクト検出モデルです。YOLOどのように機能し、どのように応用されるのか、簡単なコード例を使って実際に体験してみましょう。

YOLO、テキストプロンプトからオブジェクトを識別できる革新的なオブジェクト検出モデルです。YOLOどのように機能し、どのように応用されるのか、簡単なコード例を使って実際に体験してみましょう。
コンピューター・ビジョンのプロジェクトでは、データの注釈付けや物体検出モデルのトレーニングに多くの時間を費やすことが多い。しかし、それはすぐに過去のものになるかもしれない。テンセントのAIラボは2024年1月31日、リアルタイムのオープン語彙オブジェクト検出モデル「YOLOリリースした。YOLOゼロショット・モデルであり、つまり、訓練することなく画像上で物体検出推論を実行することができる。
ゼロショット・モデルは、コンピュータ・ビジョン・アプリケーションへのアプローチ方法を変える可能性を秘めています。このブログでは、YOLOどのように機能するのか、その潜在的な用途を探り、実践的なコード例を紹介します。
YOLOモデルを通して、画像と、探しているオブジェクトを説明するテキストプロンプトを渡すことができます。例えば、写真の中から「赤いシャツを着た人」を探したい場合、YOLOこの入力を受け取り、作業に取り掛かる。
このモデルのユニークなアーキテクチャは、主に次の3つの要素を組み合わせています。
YOLO ディテクターは、入力画像をスキャンして潜在的なオブジェクトを識別します。テキストエンコーダは、入力された説明をモデルが理解できる形式に変換します。これら2つの情報の流れは、マルチレベルのクロスモダリティフュージョンを使用して、RepVL-PANを介してマージされます。これにより、YOLO画像内のプロンプトに記述されたオブジェクトを正確にdetect し、位置を特定します。

YOLO使う最大の利点のひとつは、特定のクラスに対してモデルを訓練する必要がないことだ。YOLO-Worldはすでに画像とテキストのペアから学習しているため、説明に基づいてオブジェクトを見つける方法を知っている。データの収集、データのアノテーション、高価なGPUでのトレーニングなどに何時間も費やす必要がありません。
YOLO利用するその他の利点は以下の通り:
YOLOモデルは様々な用途に使用できます。そのいくつかを探ってみよう。
組み立てラインで製造された製品は、梱包前に目視で欠陥がないかチェックされます。欠陥検出は手作業で行われることが多く、時間がかかり、間違いにつながる可能性があります。これらの間違いは、コストの増加や修理・リコールの必要性などの問題を引き起こす可能性があります。これを支援するために、これらのチェックを実行するための特別なマシンビジョンカメラとAIシステムが作成されています。
YOLOモデルはこの分野で大きな進歩を遂げた。YOLO-Worldモデルは、そのゼロ・ショット能力を使って、特定の問題のために訓練されていなくても、製品の欠陥を見つけることができる。例えば、水筒を製造している工場では、YOLO使うことで、ボトルキャップで適切に密封されたボトルと、キャップが外れていたり欠陥のあるボトルを簡単に識別することができる。

YOLOモデルは、ロボットが不慣れな環境と相互作用することを可能にする。部屋にある特定の物体について訓練されなくても、どのような物体が存在するかを識別することができる。例えば、ロボットが入ったことのない部屋に入ったとしよう。YOLOモデルがあれば、椅子、テーブル、ランプなどのオブジェクトを認識し、識別することができる。
YOLO、物体検出に加えて、「detect」機能により、それらの物体の状態を判断することもできる。例えば、農業 ロボット工学の分野では、熟した果実と熟していない果実を識別するために、ロボットにdetect するようプログラミングすることで使用できる。
自動車産業には多くの可動部分があり、YOLOさまざまな自動車アプリケーションに使用できます。例えば、車のメンテナンスに関して言えば、手作業によるタグ付けや大規模な事前学習なしに多種多様な物体を認識できるYOLO能力は非常に有用です。YOLO、交換が必要な車の部品を特定するために使うことができる。品質チェックのような作業を自動化し、新車の欠陥や欠落を発見することもできるだろう。
もう一つのアプリケーションは、自動運転車におけるゼロショット物体検出である。YOLOゼロショット検出機能は、歩行者、交通標識、他の車両など、道路上の物体をリアルタイムでdetect ・classify する自律走行車の能力を向上させることができる。そうすることで、より安全な走行のために障害物をdetect し、事故を防ぐことができる。
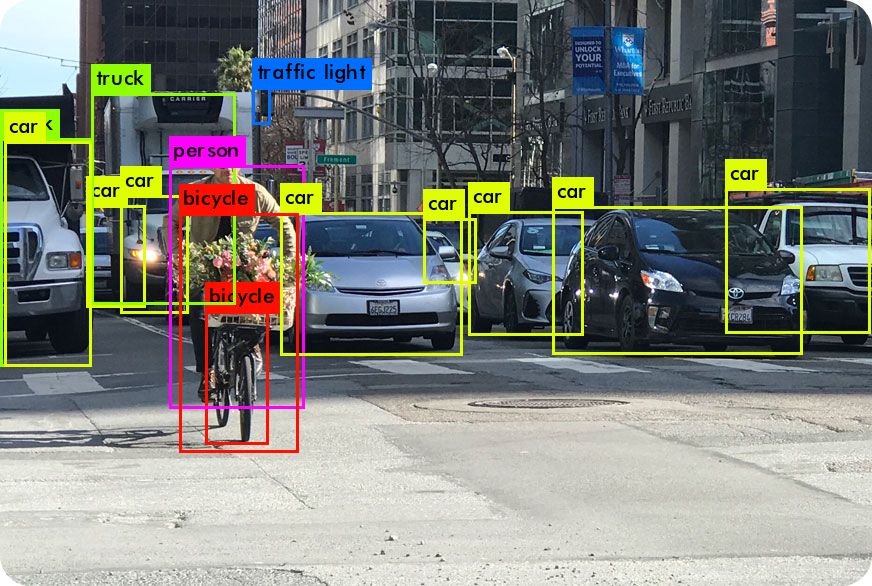
小売店の棚に陳列された対象物を識別することは、在庫の追跡、在庫の管理、プロセスの自動化において重要な役割を果たします。Ultralytics YOLO能力は、手作業によるタグ付けや大規模な事前トレーニングなしに様々な対象物を認識することができるため、在庫管理に非常に役立ちます。
例えば、在庫管理では、YOLO、異なるブランドのエナジードリンクなど、棚にある商品を素早く見つけ、分類することができる。小売店は正確な在庫を管理し、在庫レベルを効率的に管理し、サプライチェーン業務を円滑に行うことができる。
どのアプリケーションもユニークで、YOLOいかに幅広く使えるかを示している。次に、YOLO実際に使って、コーディングの例を見てみよう。
前にも述べたように、YOLO、メンテナンスのために車のさまざまな部分をdetect するために使用することができる。修理が必要な箇所を検出するコンピューター・ビジョン・アプリケーションは、車の写真を撮り、車の部品を特定し、車の各部分の損傷を調べ、修理を推奨する。このシステムの各部分は、異なるAI技術とアプローチを使用することになる。このコードのウォークスルーでは、車の部品を検出する部分に焦点を当てます。
YOLO使えば、5分もかからずに画像内のさまざまな車の部品を識別することができます。このコードを拡張して、YOLOさまざまなアプリケーションを試すこともできる!始めるには、以下のようにUltralytics パッケージをpipでインストールする必要がある。
インストールプロセスに関する詳しい説明とベストプラクティスについては、Ultralytics インストールガイドをご覧ください。YOLOv88に必要なパッケージのインストール中に、何らかの問題が発生した場合は、解決策とヒントに関する「よくある問題」ガイドをご覧ください。
必要なパッケージをインストールしたら、インターネットから画像をダウンロードして推論を実行できます。ここでは、以下の画像を使用します。

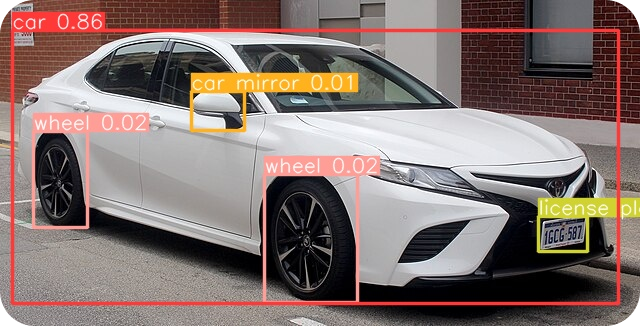
次に、必要なパッケージをインポートし、モデルを初期化して、入力画像で探しているクラスを設定します。ここでは、car(車)、wheel(ホイール)、car door(車のドア)、car mirror(車のミラー)、license plate(ナンバープレート)のクラスに関心があります。
次にpredictメソッドを使い、画像のパスと、最大検出数、intersection over unionIoU)とconfidence (conf)のしきい値をパラメータとして与え、画像に対して推論を実行する。最後に、検出されたオブジェクトは'result.jpg'という名前のファイルに保存される。
次の出力画像がファイルに保存されます。
コーディングなしでYOLO機能をご覧になりたい方は、YOLOデモページにアクセスして、入力画像をアップロードし、カスタムクラスを入力してください。
YOLOドキュメントページを読んで、カスタムクラスと一緒にモデルを保存し、カスタムクラスを何度も入力することなく後で直接使えるようにする方法を学んでください。
出力画像をもう一度見てみると、カスタムクラス「車のドア」が検出されていないことに気づくだろう。YOLO、その偉大な功績にもかかわらず、一定の限界があります。これらの制限と戦い、YOLOモデルを効果的に使うには、正しいタイプのテキストプロンプトを使うことが重要です。
以下にいくつかのヒントを示します。
全体として、YOLOモデルは、その高度な物体検出機能により、強力なツールにすることができる。 それは、非常に効率的で正確であり、実践的に説明した車の部品の識別の例のように、様々なアプリケーションにわたって様々なタスクを自動化するのに役立つ。
当社のGitHubリポジトリで、コンピュータビジョンとAIへの貢献の詳細をご覧ください。AIがヘルスケア・ テクノロジーなどの分野をどのように再構築しているかに興味がある方は、当社のソリューション・ページをご覧ください。YOLOようなイノベーションの可能性は無限大です!
.webp)

.webp)