



MetaのLlama 3が最近リリースされ、AIコミュニティから大きな興奮をもって迎えられました。Meta AIの最新の進歩であるLlama 3について、さらに詳しく学びましょう。

MetaのLlama 3が最近リリースされ、AIコミュニティから大きな興奮をもって迎えられました。Meta AIの最新の進歩であるLlama 3について、さらに詳しく学びましょう。
2024年第1四半期の人工知能(AI)イノベーションをまとめた際、LLM(大規模言語モデル)がさまざまな組織から次々とリリースされていることがわかりました。この傾向は続き、2024年4月18日、Metaは次世代の最先端オープンソースLLMであるLlama 3をリリースしました。
あなたはこう思っているかもしれません。また別のLLMか。なぜAIコミュニティはこんなに興奮しているんだ?
GPT-3やGeminiのようなモデルをファインチューニングして、カスタマイズされた応答を得ることはできますが、トレーニングデータ、モデルパラメータ、アルゴリズムなど、内部の仕組みに関する完全な透明性は提供されていません。対照的に、MetaのLlama 3はより透明性が高く、そのアーキテクチャと重みはダウンロード可能です。AIコミュニティにとって、これは実験の自由度が高まることを意味します。
この記事では、Llama 3が何ができるのか、どのようにして生まれたのか、そしてAI分野への影響について学びます。早速始めましょう!
Llama 3に飛び込む前に、以前のバージョンを振り返ってみましょう。
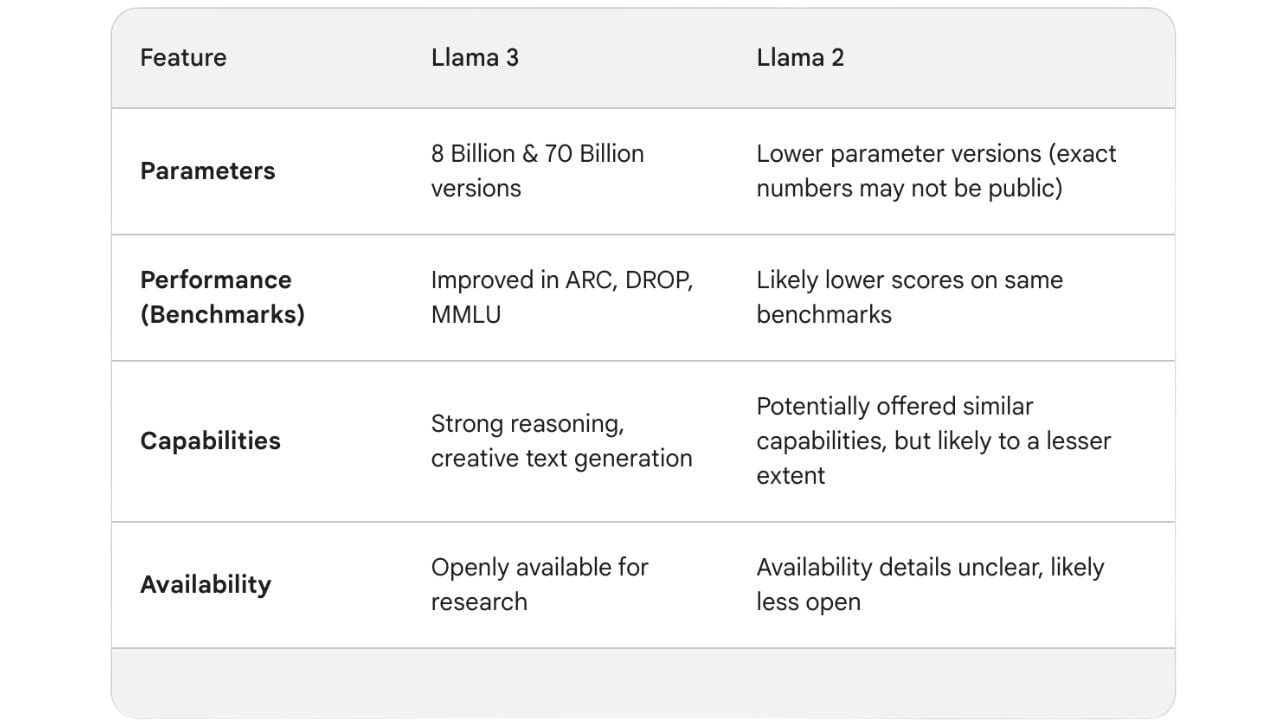
Metaは2023年2月にLlama 1をローンチしました。これは70億から640億のパラメータを持つ4つのバリエーションで提供されました。機械学習において、「パラメータ」とは、トレーニングデータから学習されるモデルの要素を指します。パラメータ数が少ないため、Llama 1はニュアンスのある理解に苦労し、一貫性のない応答をすることがありました。
Llama 1の直後、Metaは2023年7月にLlama 2をローンチしました。これは2兆のトークンでトレーニングされました。トークンとは、単語や単語の一部など、テキストの一部を表し、モデルでの処理の基本的なデータ単位として使用されます。このモデルは、より長い文章を理解するための4096トークンのコンテキストウィンドウの倍増や、エラーを減らすための100万人以上の人間によるアノテーションなどの機能強化も特徴としていました。これらの改善にもかかわらず、Llama 2は依然として多くの計算能力を必要としており、MetaはLlama 3でこれを修正することを目指しました。
Llama 3には4つのバリエーションがあり、15兆という膨大なトークンに対してトレーニングされています。そのトレーニングデータの5%以上(約8億トークン)が、30の異なる言語のデータを表しています。Llama 3のすべてのバリエーションは、さまざまな種類のコンシューマーハードウェアで実行でき、8kトークンのコンテキスト長を持っています。

モデルのバリエーションには、8Bと70Bの2つのサイズがあり、それぞれ80億と700億のパラメータを示しています。また、baseとinstructの2つのバージョンがあります。「Base」は、標準の事前トレーニングされたバージョンを指します。「Instruct」は、関連データに対する追加のトレーニングを通じて、特定のアプリケーションまたはドメイン向けに最適化されたファインチューニングされたバージョンです。
これらがLlama 3のモデルバリエーションです。
他のMeta AIの進歩と同様に、Llama 3の開発中にデータ整合性を維持し、バイアスを最小限に抑えるために、厳格な品質管理対策が講じられました。そのため、最終製品は責任を持って作成された強力なモデルです。
Llama 3のモデルアーキテクチャは、自然言語処理タスクにおける効率とパフォーマンスに重点を置いている点で際立っています。Transformerベースのフレームワーク上に構築されており、デコーダー専用アーキテクチャを使用することで、特にテキスト生成中の計算効率を重視しています。
このモデルは、入力をエンコードするエンコーダーなしで、先行するコンテキストのみに基づいて出力を生成するため、はるかに高速です。

Llama 3モデルは、128Kトークンの語彙を持つトークナイザーを備えています。語彙が多いほど、モデルはテキストをより良く理解し、処理できます。また、モデルは推論効率を向上させるために、グループ化されたクエリ注意(GQA)を使用するようになりました。GQAは、モデルが入力データの関連部分に焦点を当てて、より高速で正確な応答を生成するのに役立つスポットライトと考えることができます。
Llama 3のモデルアーキテクチャに関する興味深い詳細をいくつかご紹介します。
最大のLlama 3モデルをトレーニングするために、データ並列処理、モデル並列処理、パイプライン並列処理の3種類の並列処理が組み合わされました。
データ並列化では、トレーニングデータを複数のGPUに分割し、モデル並列化では、GPU計算能力を利用するためにモデルアーキテクチャを分割します。パイプライン並列化では、トレーニングプロセスを連続的なステージに分割し、計算と通信を最適化します。
最も効率的な実装では、16,000個のGPUで同時に学習させた場合、GPU あたり400TFLOPSを超えるという驚くべき計算効率を達成した。これらのトレーニング実行は、それぞれ24,000 GPUで構成される2つの特注GPU クラスタで行われました。この充実した計算インフラは、大規模なLlama 3モデルを効率的に訓練するために必要なパワーを提供しました。
GPU 稼働時間を最大化するため、高度な新しいトレーニングスタックが開発され、エラーの検出、処理、メンテナンスが自動化された。ハードウェアの信頼性と検出メカニズムは、サイレントデータ破損のリスクを軽減するために大幅に改善されました。また、チェックポイントとロールバックのオーバーヘッドを削減するために、スケーラブルな新しいストレージシステムが開発されました。
これらの改善により、全体的なトレーニング時間は95%以上の有効性を達成しました。これらを組み合わせることで、Llama 3のトレーニング効率はLlama 2と比較して約3倍向上しました。この効率は印象的なだけでなく、AIトレーニング方法に新たな可能性を切り開いています。
Llama 3 はオープンソースであるため、研究者や学生はそのコードを研究し、実験を行い、倫理的な懸念や偏りについて議論することができます。しかし、Llama 3 は学術的な分野だけのものではありません。実用的なアプリケーションにおいても大きな影響を与えています。Meta AI Chat Interface のバックボーンとなり、Facebook、Instagram、WhatsApp、Messenger などのプラットフォームにシームレスに統合されています。Meta AI を使用すると、ユーザーは自然言語での会話、パーソナライズされた推奨事項へのアクセス、タスクの実行、他のユーザーとの簡単なつながりなどが可能になります。

Llama 3 は、複雑な言語理解と推論能力を評価するいくつかの主要なベンチマークにおいて、非常に優れた性能を発揮します。以下は、Llama 3 のさまざまな能力をテストするベンチマークの一部です。
これらのテストにおけるラマ3の傑出した結果は、Google社のジェンマ7B、ミストラル社のミストラル7B、Anthropic社のクロード3ソネットといった競合製品と明らかに一線を画している。公表されている統計によると、特に70Bモデルでは、上記のすべてのベンチマークでラマ3がこれらのモデルを上回っている。

Meta は、一般ユーザーと開発者の両方に向けて、さまざまなプラットフォームで Llama 3 を利用できるようにすることで、そのリーチを拡大しています。一般ユーザー向けには、Llama 3 は WhatsApp、Instagram、Facebook、Messenger などの Meta の人気プラットフォームに統合されています。ユーザーは、リアルタイム検索や、これらのアプリ内で直接クリエイティブコンテンツを生成する機能などの高度な機能にアクセスできます。
Llama 3 は、インタラクティブな体験のために、Ray-Ban Meta スマートグラスや Meta Quest VR ヘッドセットなどのウェアラブルテクノロジーにも組み込まれています。
Llama 3は、AWS、Databricks、Google Cloud、Hugging Face、Kaggle、IBM WatsonX、Microsoft Azure、NVIDIA NIM、Snowflakeなど、開発者向けのさまざまなプラットフォームで利用できる。また、Metaから直接これらのモデルにアクセスすることもできます。幅広いオプションにより、開発者は、Metaと直接作業することを好むか、他の一般的なプラットフォームを通じて作業することを好むかにかかわらず、これらの高度なAIモデル機能をプロジェクトに簡単に統合することができます。
機械学習の進歩は、私たちが日々テクノロジーとどのように関わるかを変革し続けています。Meta の Llama 3 は、LLM がもはや単にテキストを生成するだけのものではないことを示しています。LLM は、複雑な問題に取り組み、複数の言語を処理しています。全体として、Llama 3 は AI をこれまで以上に適応性があり、アクセスしやすいものにしています。今後、Llama 3 の計画されているアップグレードでは、複数のモデルの処理や、より大きなコンテキストの理解など、さらに多くの機能が約束されています。
AI の詳細については、GitHub リポジトリ をチェックし、コミュニティ に参加してください。製造業 や 農業 などの分野で AI がどのように応用されているかについては、ソリューションページをご覧ください。



{kind=link}
{kind=link}
{kind=link}