



教師あり学習から転移学習まで、コンピュータビジョンアプリケーションで使用されるさまざまな種類の機械学習および深層学習技術について解説します。

教師あり学習から転移学習まで、コンピュータビジョンアプリケーションで使用されるさまざまな種類の機械学習および深層学習技術について解説します。
機械学習は、人工知能(AI)の一種であり、コンピュータがデータから学習して、タスクごとに詳細なプログラミングを必要とせずに、独自に意思決定できるようにします。これには、データ内のパターンを識別できるアルゴリズムモデルの作成が含まれます。データ内のパターンを識別し、それらから学習することにより、これらのアルゴリズムは時間の経過とともにパフォーマンスを徐々に向上させることができます。
機械学習が重要な役割を果たしている分野のひとつに、視覚データに焦点を当てたAIの分野であるコンピューター・ビジョンがある。コンピューター・ビジョンは、コンピューターが画像や映像のパターンをdetect ・認識するために機械学習を利用する。機械学習の進歩に後押しされ、コンピューター・ビジョンの世界市場価値は2032年までに約1757億2000万ドルになると推定されている。
この記事では、コンピュータビジョンで使用される様々な種類の機械学習(教師あり学習、教師なし学習、強化学習、転移学習など)と、それぞれの学習方法が様々なアプリケーションでどのように役割を果たしているかを見ていきます。それでは始めましょう!
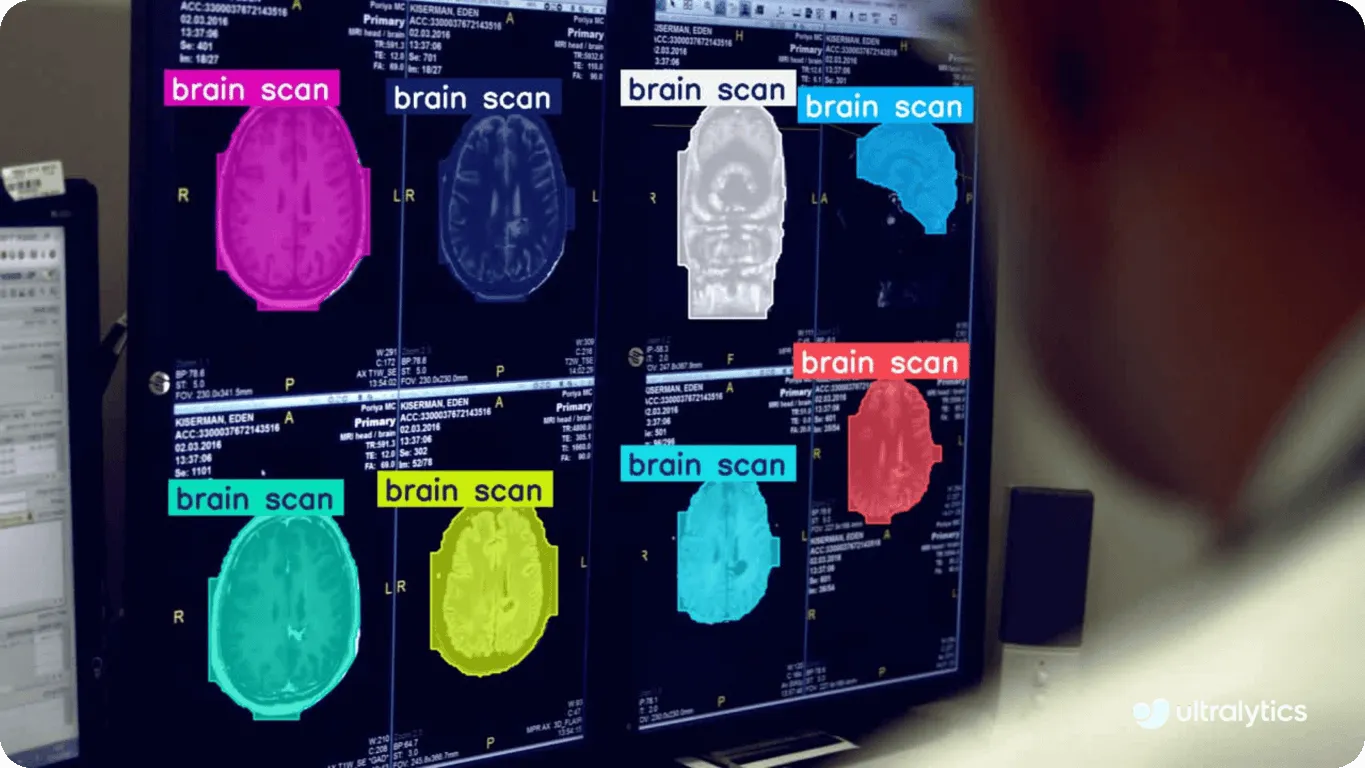
コンピュータ・ビジョンは、機械学習、特にディープ・ラーニングや ニューラルネットワークのような技術に依存して、視覚情報を解釈・分析する。これらの手法により、コンピュータは画像中の物体の検出、画像のカテゴリー分類、顔の認識といった コンピュータ・ビジョンのタスクを実行できるようになる。また、機械学習は、製造業における 品質管理や医療における 医療画像のようなリアルタイムのコンピュータ・ビジョン・アプリケーションにも不可欠である。このような場合、ニューラルネットワークは、腫瘍をdetect するための脳スキャンの分析など、コンピュータが複雑な視覚データを解釈するのに役立つ。
実際、次のような多くの高度なコンピュータビジョンモデルがあります。 Ultralytics YOLO11のように、多くの先進的なコンピュータ・ビジョン・モデルは、ニューラルネットワークに基づいて構築されている。
教師あり学習、教師なし学習、転移学習、強化学習など、機械学習にはいくつかの種類の学習方法があり、コンピュータビジョンで可能なことの限界を押し広げています。次のセクションでは、これらの各タイプを調べて、それらがコンピュータビジョンにどのように貢献するかを理解します。
教師あり学習は、最も一般的に使用される機械学習の種類です。教師あり学習では、モデルはラベル付きデータを使用してトレーニングされます。各入力には正しい出力がタグ付けされており、モデルの学習に役立ちます。生徒が先生から学ぶのと同じように、このラベル付きデータはガイドまたは監督者として機能します。
トレーニング中、モデルには入力データ(処理に必要な情報)と出力データ(正解)の両方が与えられます。この設定は、モデルが入力と出力の間のつながりを学習するのに役立ちます。教師あり学習の主な目標は、モデルが各入力を正しい出力に正確に関連付けるルールまたはパターンを発見することです。このマッピングにより、モデルは新しいデータに遭遇したときに正確な予測を行うことができます。たとえば、コンピュータビジョンにおける顔認識は、これらの学習されたパターンに基づいて顔を識別するために教師あり学習に依存しています。
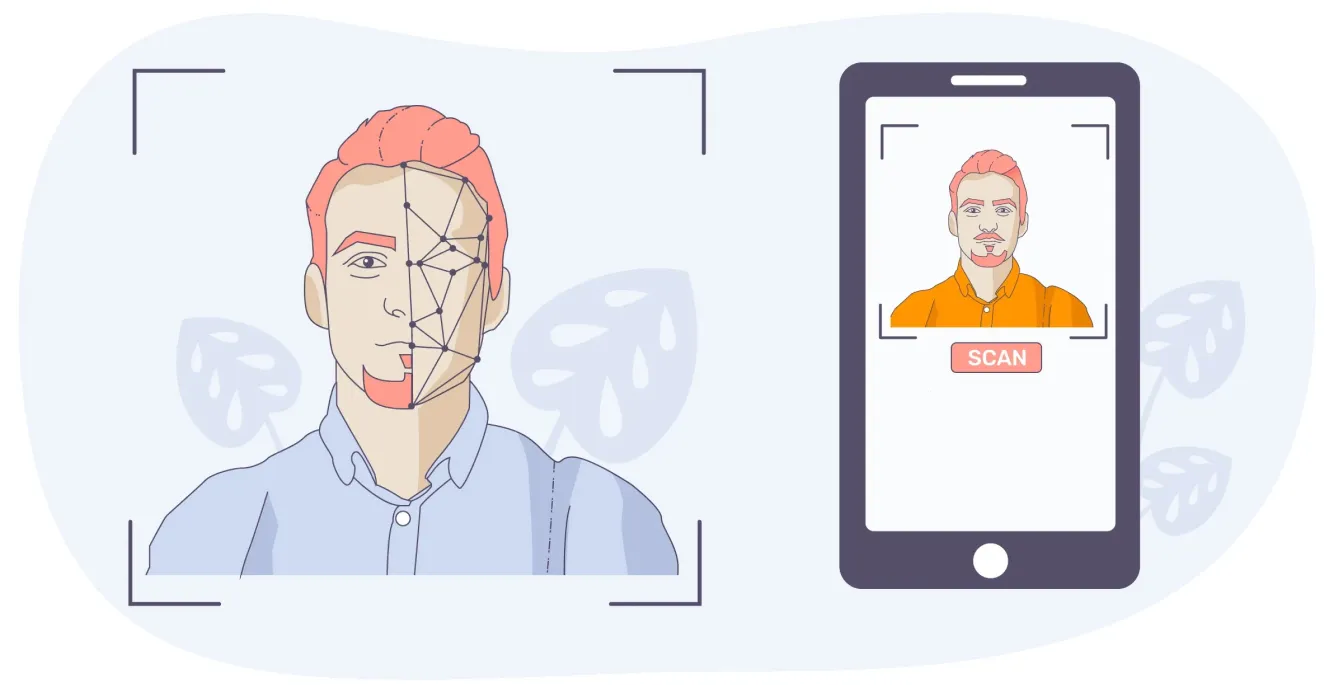
一般的な使用例は、顔認識でスマートフォンのロックを解除することです。モデルはあなたの顔のラベル付き画像でトレーニングされているため、電話のロックを解除するときに、ライブ画像を学習した内容と比較します。一致が検出されると、電話のロックが解除されます。
教師なし学習は、ラベルなしデータを使用する機械学習の一種です。モデルは、トレーニング中にガイダンスや正解を与えられません。代わりに、パターンと洞察を独自に発見することを学習します。
教師なし学習では、主に次の3つの方法を使用してパターンを識別します。
教師なし学習の重要な応用例は画像圧縮であり、k-meansクラスタリングなどの手法を使用して、画質に影響を与えることなく画像サイズを縮小します。ピクセルはクラスターにグループ化され、各クラスターは平均色で表され、色の数が少なく、ファイルサイズが小さくなります。

ただし、教師なし学習には、いくつかの制限があります。定義済みの答えがないため、精度とパフォーマンスの評価に苦労する可能性があります。結果を解釈してグループにラベルを付けるには、多くの場合、手作業が必要であり、欠損値やノイズなどの問題に敏感であり、結果の品質に影響を与える可能性があります。
教師あり学習や教師なし学習とは異なり、強化学習はトレーニングデータに依存しません。代わりに、特定の目標を達成するために、ニューラルネットワークエージェントを使用して環境と相互作用します。
このプロセスには、主に3つのコンポーネントが含まれます。
エージェントがアクションを実行すると、環境に影響を与え、環境はフィードバックで応答します。フィードバックは、エージェントが自分の選択を評価し、行動を調整するのに役立ちます。報酬シグナルは、エージェントがどの行動が目標の達成に近づくかを理解するのに役立ちます。
強化学習は、自律走行や ロボット工学などのユースケースで重要な役割を果たす。自律走行では、車両制御、物体検知、回避などのタスクがフィードバックに基づいて学習される。歩行者や他の物体をdetect し、衝突を回避するために適切な行動を取るために、ニューラルネットワーク・エージェントを使ってモデルが学習される。同様に、ロボット工学では、強化学習が物体操作や動作制御などのタスクを可能にする。
強化学習の良い例としては、OpenAIによるプロジェクトがあります。そこでは、研究者たちが人気のあるマルチプレイヤービデオゲームであるDota 2をプレイするためにAIエージェントを訓練しました。ニューラルネットワークを使用して、これらのエージェントはゲーム環境から大量の情報を処理し、迅速かつ戦略的な意思決定を行いました。継続的なフィードバックを通じて、エージェントは学習し、時間の経過とともに改善され、最終的にはゲームのトッププレイヤーの何人かを打ち負かすのに十分なスキルレベルに達しました。
転移学習は、他のタイプの学習とは異なります。ゼロからモデルをトレーニングする代わりに、大規模なデータセットで事前トレーニングされたモデルを使用し、新しい、ただし関連するタスクのために微調整します。最初のトレーニングで得られた知識は、新しいタスクのパフォーマンスを向上させるために使用されます。転移学習は、複雑さに応じて、新しいタスクのトレーニングに必要な時間を短縮します。これは、一般的な特徴を捉えるモデルの初期レイヤーを保持し、最後のレイヤーを新しい特定のタスクのレイヤーに置き換えることによって機能します。
芸術的なスタイルの変換は、コンピュータビジョンにおける転移学習の興味深い応用です。この技術により、モデルは画像を変換して、さまざまなアートワークのスタイルに一致させることができます。これを実現するために、ニューラルネットワークは、まず画像とその芸術的なスタイルを組み合わせた大規模なデータセットでトレーニングされます。このプロセスを通じて、モデルは一般的な画像の特徴とスタイルのパターンを識別することを学習します。
モデルのトレーニングが完了すると、特定の絵画のスタイルを新しい画像に適用するように微調整できます。ネットワークは、学習したスタイルの特徴を保持しながら、新しい画像に適応し、元のコンテンツと選択した芸術的なスタイルを組み合わせたユニークな結果を作成できます。たとえば、山脈の写真を撮り、エドヴァルド・ムンクの叫びのスタイルを適用すると、シーンを捉えながら、絵画の大胆で表現力豊かなスタイルを持つ画像が得られます。

機械学習の主な種類について説明したところで、さまざまなアプリケーションに最適なものを理解するために、それぞれを詳しく見ていきましょう。

適切な機械学習タイプを選択するかどうかは、いくつかの要因によって決まります。教師あり学習は、ラベル付きデータが豊富にあり、明確なタスクがある場合に適しています。教師なし学習は、データの探索やラベル付きの例が少ない場合に役立ちます。強化学習は、段階的な意思決定を必要とする複雑なタスクに最適であり、転移学習は、データが限られている場合やリソースが制約されている場合に適しています。これらの要素を考慮することで、コンピュータビジョンプロジェクトに最適なアプローチを選択できます。
機械学習技術は、特にコンピュータビジョンのような分野で、さまざまな課題に取り組むことができます。教師あり学習、教師なし学習、強化学習、転移学習といったさまざまなタイプを理解することで、ニーズに最適なアプローチを選択できます。
教師あり学習は、高い精度とラベル付きデータを必要とするタスクに最適であり、教師なし学習は、ラベルなしデータ内のパターンを見つけるのに理想的です。強化学習は、複雑な意思決定ベースの設定でうまく機能し、転移学習は、限られたデータで事前トレーニング済みのモデルを基に構築したい場合に役立ちます。
各手法には、顔認識からロボット工学、芸術的なスタイルの変換まで、独自の強みとアプリケーションがあります。適切なタイプを選択することで、医療、自動車、エンターテインメントなどの業界全体で新たな可能性が開かれます。
詳細については、GitHubリポジトリにアクセスし、コミュニティにご参加ください。当社のソリューションページで、自動運転車や農業におけるAIアプリケーションをご覧ください。🚀


