



Mask R-CNNを使用して、画像やビデオ内のオブジェクトを正確にsegment し、さまざまな分野で活用する方法をご紹介します。

Mask R-CNNを使用して、画像やビデオ内のオブジェクトを正確にsegment し、さまざまな分野で活用する方法をご紹介します。
倉庫におけるロボット、交通量の多い道路を安全に走行する自動運転車、作物をチェックするドローン、工場で製品を検査するAIシステムなどのイノベーションは、AIの導入が進むにつれてますます一般的になっています。これらのイノベーションを推進する重要な技術がコンピュータビジョンです。これは、機械が視覚データを理解し、解釈することを可能にするAIの一分野です。
例えば、物体検出は、バウンディングボックスを使用して画像内の物体を識別し、位置を特定するコンピュータビジョンのタスクです。バウンディングボックスは役立つ情報を提供しますが、物体の位置を大まかに推定するだけで、正確な形状や境界を捉えることはできません。そのため、正確な識別が必要なアプリケーションでは効果が低くなります。
この問題を解決するために、研究者たちは物体の正確な輪郭を捉え、より正確な検出と分析のためにピクセルレベルの詳細を提供するセグメンテーションモデルを開発しました。
Mask R-CNNはこれらのモデルの1つである。Facebook AI Research(FAIR)によって2017年に導入されたこのモデルは、R-CNN、Fast R-CNN、Faster R-CNNといった以前のモデルをベースにしている。コンピュータビジョンの歴史における重要なマイルストーンとして、Mask R-CNNは以下のようなより高度なモデルへの道を開いた。 Ultralytics YOLO11.
この記事では、マスクR-CNNとは何か、どのように機能するのか、その応用例、そしてYOLO11至るまでにどのような改良が加えられたのかを探る。
Mask R-CNN(Mask Region-based Convolutional Neural Networkの略)は、物体検出やインスタンスセグメンテーションなどのコンピュータビジョンタスク向けに設計された深層学習モデルです。
インスタンスセグメンテーションは、画像内の物体を識別するだけでなく、各物体を正確にアウトライン化することで、従来の物体検出を超えています。検出されたすべての物体に一意のラベルを割り当て、ピクセルレベルで正確な形状を捉えます。この詳細なアプローチにより、重なり合う物体を明確に区別し、複雑な形状を正確に処理することが可能になります。
Mask R-CNNは、物体を検出してラベル付けしますが、正確な形状を定義しないFaster R-CNNを基に構築されています。Mask R-CNNは、各物体を構成する正確なピクセルを識別することでこれを改善し、より詳細で正確な画像分析を可能にします。

Mask R-CNN は、段階的なアプローチで物体を正確にdetect し、segment する。ディープニューラルネットワーク(データから学習する多層モデル)を使用して主要な特徴を抽出することから始め、次に領域提案ネットワーク(オブジェクトの可能性が高い領域を提案するコンポーネント)を使用して潜在的なオブジェクト領域を特定し、最後に各オブジェクトの正確な形状をキャプチャする詳細なセグメンテーションマスク(オブジェクトの正確な輪郭)を作成することによって、これらの領域を絞り込む。
次に、Mask R-CNNの仕組みをより深く理解するために、各ステップを順を追って説明します。
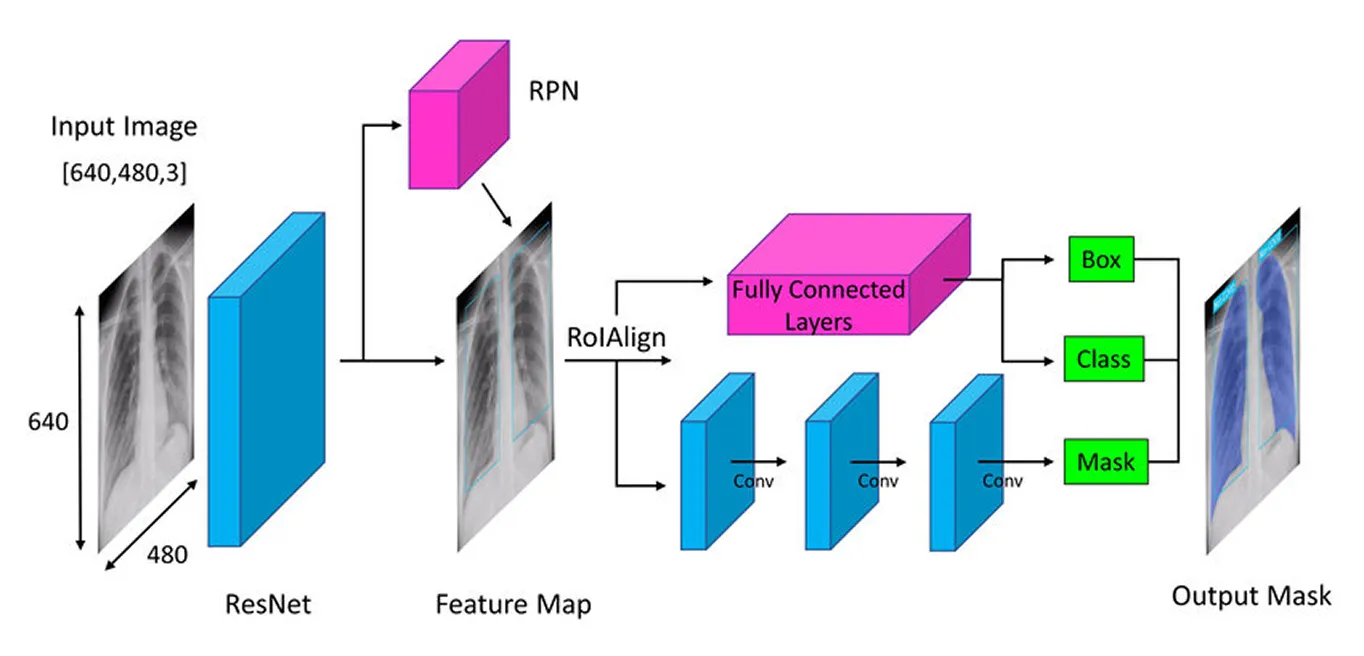
Mask R-CNNのアーキテクチャにおける最初のステップは、モデルが画像の内容を理解できるように、画像を主要な要素に分解することです。これは、写真を見たときに、形状、色、エッジなどの詳細に自然に気づくのと同じです。モデルは、「バックボーン」(通常はResNet-50またはResNet-101)と呼ばれる深層ニューラルネットワークを使用して同様の処理を行います。これは、画像全体をスキャンして主要な詳細を拾い上げる目のような役割を果たします。
画像内の物体は非常に小さい場合もあれば、非常に大きい場合もあるため、Mask R-CNNはFeature Pyramid Networkを使用します。これは、モデルが細部と全体像の両方を確認できるさまざまな拡大鏡を持っているようなもので、あらゆるサイズの物体が確実に認識されるようにします。
重要な特徴が抽出されると、モデルは画像中の潜在的なオブジェクトの特定に進み、さらなる分析の準備を整えます。
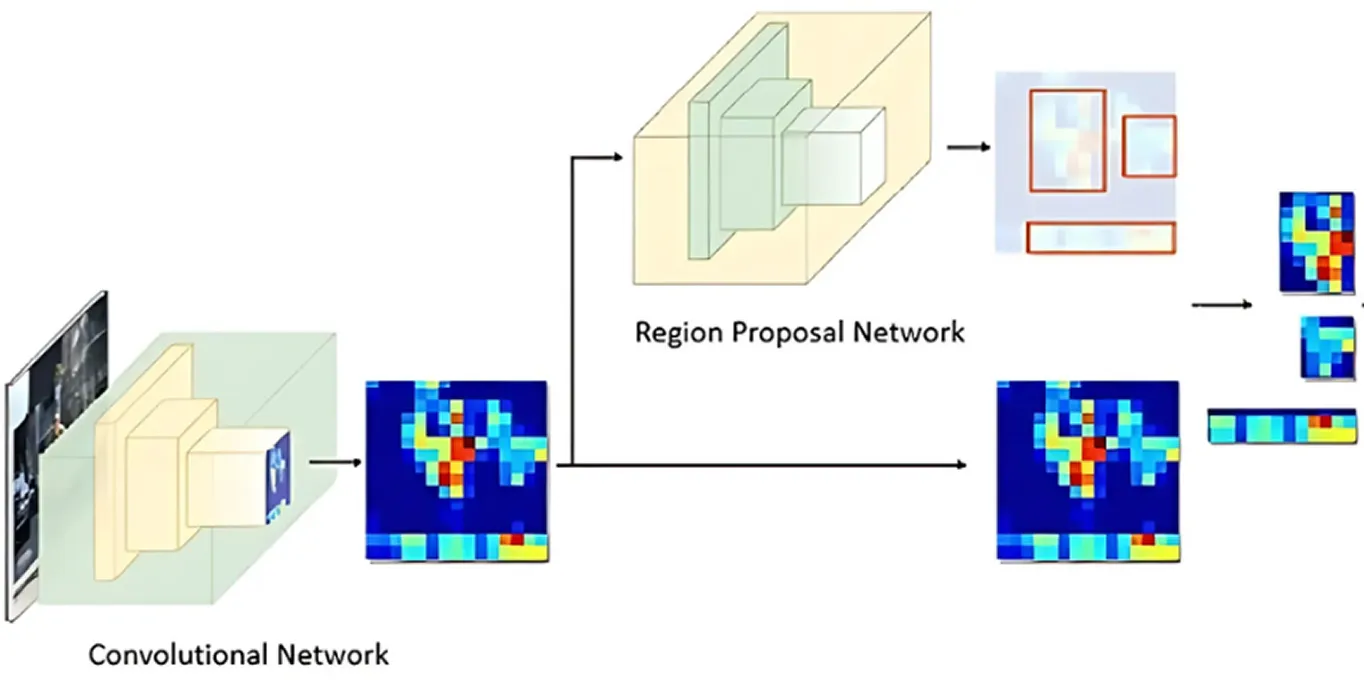
画像からキーとなる特徴が処理された後、Region Proposal Network(領域提案ネットワーク)が処理を引き継ぎます。モデルのこの部分は画像を見て、オブジェクトが含まれている可能性の高い領域を提案します。
これは、アンカーと呼ばれる複数のオブジェクトの候補位置を生成することによって行われます。次に、ネットワークはこれらのアンカーを評価し、さらなる分析のために最も有望なものを選択します。このようにして、モデルは画像内のすべての場所をチェックするのではなく、最も関心のある可能性の高い領域のみに焦点を当てます。
キーとなる領域が特定されたら、次のステップは、これらの領域から抽出された詳細を洗練することです。以前のモデルでは、ROI Pooling(Region of Interest Pooling)と呼ばれる手法を使用して各領域から特徴を取得していましたが、この手法では、領域のサイズを変更する際にわずかなずれが生じることがあり、特に小さいオブジェクトや重複するオブジェクトの場合には効果が低下していました。
Mask R-CNNは、ROI Align(Region of Interest Align)と呼ばれる手法を使用することで、これを改善しています。ROI Poolingのように座標を丸める代わりに、ROI Alignは双線形補間を使用してピクセル値をより正確に推定します。双線形補間は、4つの最も近い隣接ピクセルの値を平均して新しいピクセル値を計算し、より滑らかなトランジションを作成する方法です。これにより、特徴が元の画像と適切に整列された状態に保たれ、より正確なオブジェクト検出とセグメンテーションが実現します。
たとえば、サッカーの試合では、2人のプレーヤーが互いに接近して立っている場合、それらのバウンディングボックスが重複しているため、互いに間違われる可能性があります。ROI Alignは、それらの形状を明確に保つことによって、それらを分離するのに役立ちます。
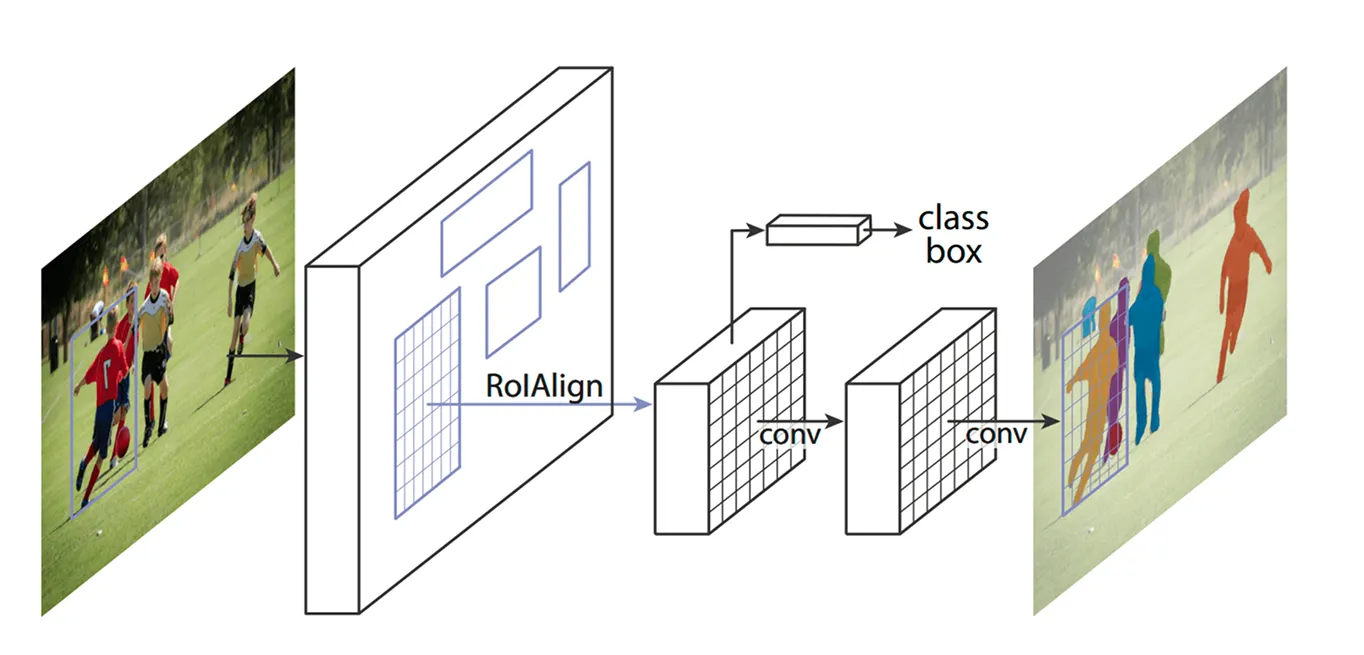
ROI Align が画像を処理すると、次のステップはオブジェクトのclassify 位置の微調整を行います。モデルは抽出された各領域を見て、それがどのオブジェクトを含むかを決定します。異なるカテゴリに確率スコアを割り当て、最もマッチするものを選びます。
同時に、バウンディングボックスを調整してオブジェクトにより適合させます。初期のボックスは理想的な位置に配置されていない可能性があるため、各ボックスが検出されたオブジェクトをしっかりと囲むようにすることで、精度が向上します。
最後に、Mask R-CNNは追加のステップとして、各オブジェクトに対して詳細なセグメンテーションマスクを並行して生成します。
このモデルが登場したとき、AIコミュニティは大きな興奮に包まれ、すぐにさまざまなアプリケーションで使用されるようになった。リアルタイムで物体をdetect し、segment するその能力は、さまざまな業界においてゲームチェンジャーとなった。
例えば、野生の絶滅危惧動物を追跡するのは困難な作業だ。多くの種は密林の中を移動するため、自然保護活動家がtrack するのは難しい。従来の方法では、カメラトラップ、ドローン、衛星画像などを使用するが、手作業でこれらのデータを整理するのは時間がかかる。誤認や見落としは保護活動の妨げになる。
マスクR-CNNは、トラの縞模様やキリンの斑点、ゾウの耳の形といったユニークな特徴を認識することで、画像や動画内の動物をより高い精度でdetect し、segment することができる。動物の一部が木に隠れていたり、近くに立っている場合でも、このモデルは動物を分離し、それぞれを個別に識別することができるため、野生動物のモニタリングがより迅速かつ信頼性の高いものになります。

物体検出とセグメンテーションにおいて歴史的に重要なMask R-CNNですが、いくつかの重要な欠点もあります。以下に、Mask R-CNNに関連する課題をいくつか示します。
マスクR-CNNはセグメンテーションタスクには最適だったが、多くの産業がスピードとリアルタイム性能を優先しながらコンピュータビジョンの導入を検討していた。この要求により、研究者は1回のパスで物体をdetect する1ステージモデルを開発し、効率を大幅に向上させた。
マスクR-CNNの多段階プロセスとは異なり、YOLO (You Only Look Once)のような1段階のコンピュータビジョンモデルは、リアルタイムコンピュータビジョンタスクに焦点を当てている。検出とセグメンテーションを別々に処理する代わりに、YOLO モデルは画像を一度に分析することができます。そのため、自律走行、ヘルスケア、製造、ロボット工学など、迅速な意思決定が重要なアプリケーションに最適です。
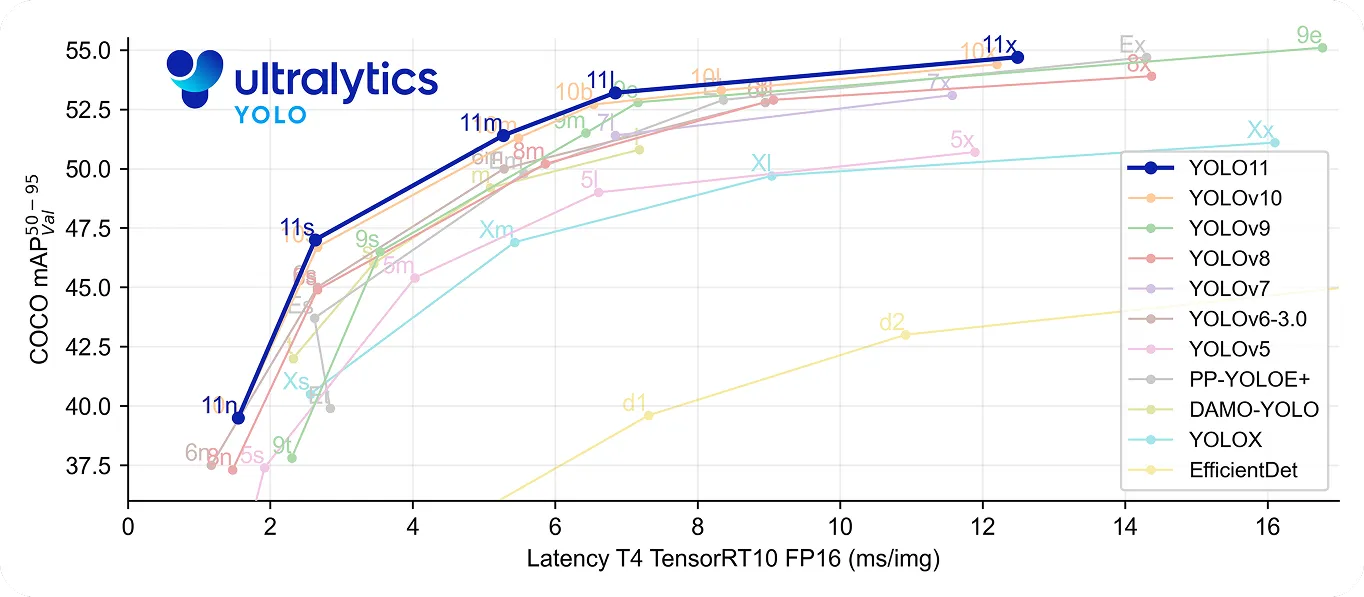
特にYOLO11 、高速かつ高精度という点でさらに一歩進んでいる。YOLOv8m 22%少ないパラメータを使用しながらも、COCO データセットの平均平均精度mAP)は高く、より正確に物体を検出します。処理速度が向上したため、ミリ秒単位が重要なリアルタイム・アプリケーションに適しています。
コンピュータビジョンの歴史を振り返ると、Mask R-CNNは、オブジェクト検出とセグメンテーションにおける大きなブレークスルーとして認識されています。詳細な多段階プロセスのおかげで、複雑な設定でも非常に正確な結果を提供します。
しかし、この同じプロセスは、YOLOようなリアルタイムモデルに比べて遅くなります。スピードと効率の必要性が高まるにつれて、多くのアプリケーションは、高速で正確な物体検出を提供するUltralytics YOLO11ような1ステージモデルを使用するようになりました。マスクR-CNNはコンピュータビジョンの進化を理解する上で重要ですが、リアルタイムソリューションへのトレンドは、より迅速で効率的なコンピュータビジョンソリューションへの需要の高まりを浮き彫りにしています。
成長を続けるコミュニティに参加しませんか? AIについてさらに学ぶには、GitHubリポジトリをご覧ください。独自のコンピュータビジョンプロジェクトを開始する準備はできましたか? ライセンスオプションをご確認ください。ソリューションページでは、農業におけるAIとヘルスケアにおけるVision AIをご紹介しています。


