


Claude 3 model kartını keşfetme: Vizyon yapay zekası için ne anlama geliyor

Claude 3 model kartını ve bunun Görüntü İşleme Yapay Zeka geliştirme üzerindeki etkisini keşfedin.

Claude 3 model kartını ve bunun Görüntü İşleme Yapay Zeka geliştirme üzerindeki etkisini keşfedin.
Son yıllarda, Vision AI, sağlık hizmetlerinden perakendeye kadar çeşitli sektörlerde devrim yaratarak önemli adımlar attı. Bu gelişmeleri etkili bir şekilde kullanmak için temel modelleri ve belgelerini anlamak çok önemlidir. Yapay Zeka (AI) geliştiricisinin cephaneliğindeki bu tür temel araçlardan biri, bir AI modelinin özellikleri ve performansı hakkında kapsamlı bir genel bakış sunan model kartıdır.
Bu makalede, Anthropic tarafından geliştirilen Claude 3 model kartını ve bunun Vision AI gelişimi üzerindeki etkilerini inceleyeceğiz. Claude 3, üç varyanttan oluşan yeni bir büyük multimodal model ailesidir: En yetenekli model olan Claude 3 Opus; performans ve hızı dengeleyen Claude 3 Sonnet; ve en hızlı ve en uygun maliyetli seçenek olan Claude 3 Haiku. Her model, görüntü verilerini işlemelerini ve analiz etmelerini sağlayan yeni görüş özellikleriyle donatılmıştır.
Model kartı tam olarak nedir? Model kartı, bir makine öğrenimi modelinin geliştirilmesi, eğitilmesi ve değerlendirilmesi hakkında ayrıntılı bilgiler sağlayan bir belgedir. Modelin işlevselliği, amaçlanan kullanım durumları ve potansiyel sınırlamaları hakkında net bilgiler sunarak şeffaflığı, hesap verebilirliği ve yapay zekanın etik kullanımını teşvik etmeyi amaçlar. Bu, model hakkında değerlendirme metrikleri, önceki modellerle ve diğer rakiplerle karşılaştırması gibi daha ayrıntılı veriler sağlanarak elde edilebilir.
Değerlendirme metrikleri, model performansını değerlendirmek için kritik öneme sahiptir. Claude 3 model kartı, doğruluk, kesinlik, geri çağırma ve F1 skoru gibi metrikleri listeleyerek modelin güçlü yönlerinin ve geliştirilmesi gereken alanların net bir resmini sunar. Bu metrikler, Claude 3'ün rekabetçi performansını sergileyerek endüstri standartlarına göre kıyaslanmıştır.
Dahası, Claude 3, mimari ve eğitim tekniklerindeki gelişmeleri bir araya getirerek seleflerinin güçlü yönleri üzerine inşa edilmiştir. Model kartı, Claude 3'ü önceki sürümlerle karşılaştırarak doğruluk, verimlilik ve yeni kullanım alanlarına uygulanabilirlik alanlarındaki iyileştirmeleri vurgulamaktadır.
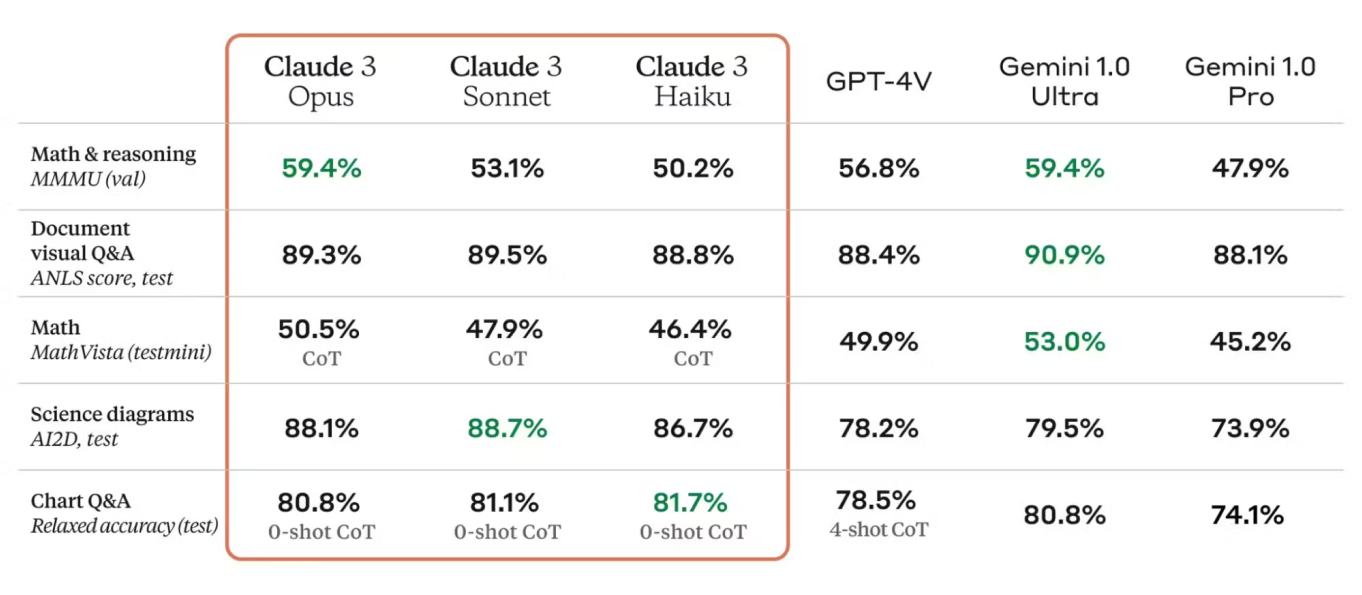
Claude 3'ün mimarisi ve eğitim süreci, çeşitli Doğal Dil İşleme (NLP) ve görsel görevlerde güvenilir performans sağlar. Karmaşık dil analizlerini etkili bir şekilde gerçekleştirme yeteneğini göstererek, kıyaslama testlerinde sürekli olarak güçlü sonuçlar elde eder.
Claude 3'ün çeşitli veri kümeleri üzerinde eğitilmesi ve veri artırma tekniklerinin kullanılması, modelin farklı senaryolarda genelleme yapabilme yeteneğini ve sağlamlığını garanti eder. Bu, modeli çok yönlü ve geniş bir uygulama yelpazesinde etkili kılar.
Elde ettiği sonuçlar dikkate değer olsa da Claude 3 temelde bir Büyük Dil Modelidir (LLM). Claude 3 gibi LLM'ler çeşitli bilgisayarla görme görevlerini yerine getirebilseler de nesne algılama, sınır kutusu oluşturma ve görüntü segmentasyonu gibi görevler için özel olarak tasarlanmamışlardır. Sonuç olarak, bu alanlardaki doğrulukları, bilgisayarla görme için özel olarak oluşturulmuş modellerle eşleşmeyebilir, örneğin Ultralytics YOLOv8. Bununla birlikte, LLM'ler diğer alanlarda, özellikle de Claude 3'ün basit görsel görevleri insan muhakemesi ile birleştirerek önemli bir güç sergilediği Doğal Dil İşleme (NLP) alanında mükemmeldir.

NLP yetenekleri, bir yapay zeka modelinin insan dilini anlama ve yanıt verme yeteneğini ifade eder. Bu yetenek, Claude 3'ün görsel alandaki uygulamalarında büyük ölçüde kullanılmakta olup, bağlamsal olarak zengin açıklamalar sunmasını, karmaşık görsel verileri yorumlamasını ve Vision AI görevlerindeki genel performansı artırmasını sağlamaktadır.
Claude 3'ün, özellikle Görüntü İşleme Yapay Zeka görevleri için kullanıldığında, etkileyici yeteneklerinden biri, okunması zor el yazısı olan düşük kaliteli görüntüleri işleme ve metne dönüştürme yeteneğidir. Bu özellik, modelin gelişmiş işleme gücünü ve çok modlu akıl yürütme yeteneklerini sergiliyor. Bu bölümde, Claude 3'ün bu görevi nasıl başardığını, altta yatan mekanizmaları ve Görüntü İşleme Yapay Zeka geliştirme üzerindeki etkilerini inceleyeceğiz.
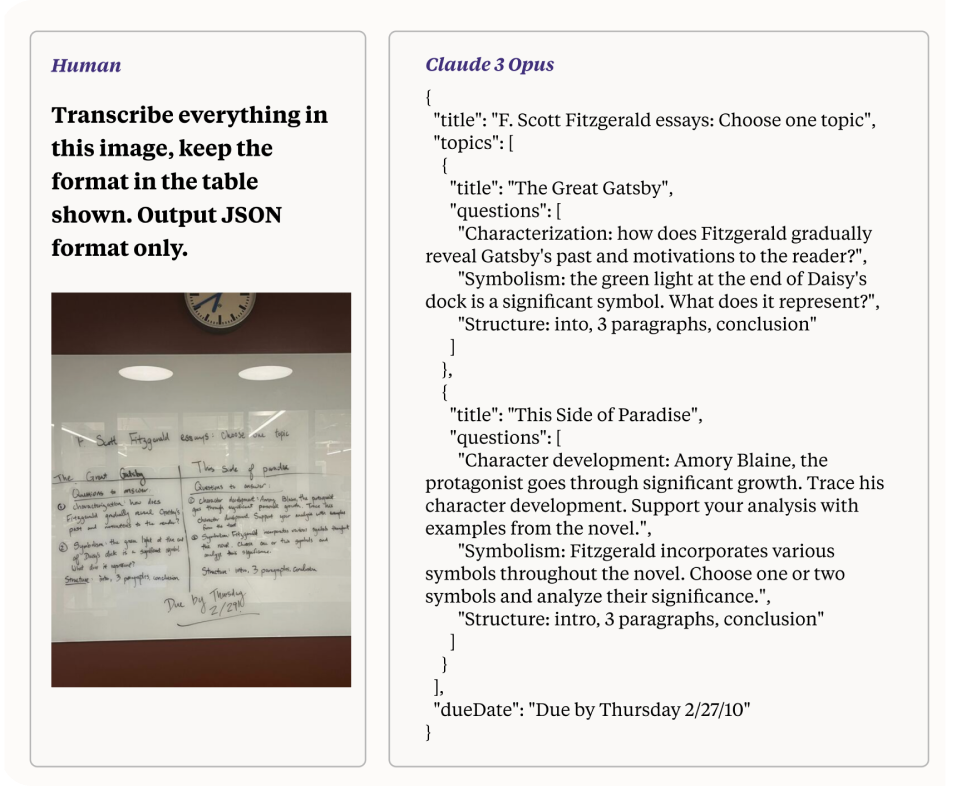
Okunması zor el yazısıyla yazılmış düşük kaliteli bir fotoğrafı metne dönüştürmek, çeşitli zorluklar içeren karmaşık bir iştir:
Daha önce belirtildiği gibi, Claude 3 modelleri, bilgisayarlı görme ve doğal dil işleme (NLP) alanlarındaki gelişmiş tekniklerin bir kombinasyonu yoluyla bu zorlukların üstesinden gelir.
Claude 3'ün mimarisi, görsel girdileri kullanarak karmaşık akıl yürütme görevlerini gerçekleştirmesini sağlar. Örneğin, Şekil 1'de gösterildiği gibi, model internet kullanımı hakkında bir grafikteki G7 ülkelerini belirleme, ilgili verileri çıkarma ve eğilimleri analiz etmek için hesaplamalar yapma gibi grafik ve çizelgeleri yorumlayabilir. Yaş grupları arasındaki internet kullanımındaki istatistiksel farklılıkları hesaplamak gibi bu çok adımlı akıl yürütme, modelin gerçek dünya uygulamalarındaki doğruluğunu ve kullanışlılığını artırır.

Claude 3, görüntüleri detaylı açıklamalara dönüştürmede üstün performans göstererek hem bilgisayar görüşü hem de doğal dil işleme alanlarındaki güçlü yeteneklerini sergiler. Bir görüntü verildiğinde, Claude 3 öncelikle evrişimsel sinir ağlarını (CNN'ler) kullanarak görsel veriler içindeki temel özellikleri çıkarmak ve nesneleri, desenleri ve bağlamsal öğeleri belirlemek için kullanır.
Bunu takiben, transformer katmanları, görüntüdeki farklı öğeler arasındaki ilişkileri ve bağlamı anlamak için dikkat mekanizmalarından yararlanarak bu özellikleri analiz eder. Bu çok modlu yaklaşım, Claude 3'ün yalnızca nesneleri tanımlayarak değil, aynı zamanda etkileşimlerini ve sahne içindeki önemini anlayarak doğru, bağlamsal olarak zengin açıklamalar oluşturmasını sağlar.

Claude 3 gibi büyük dil modelleri (LLM'ler) bilgisayarla görmede değil, doğal dil işlemede mükemmeldir. Görüntüleri tanımlayabilseler de, nesne algılama ve görüntü segmentasyonu gibi görevler YOLOv8 gibi görüntü odaklı modeller tarafından daha iyi ele alınır. Bu özel modeller görsel görevler için optimize edilmiştir ve görüntüleri analiz etmek için daha iyi performans sağlar. Ayrıca, model sınırlayıcı kutu oluşturma gibi görevleri yerine getiremez.
Claude 3'ü bilgisayarlı görü sistemleriyle birleştirmek karmaşık olabilir ve metin ile görsel veriler arasındaki boşluğu doldurmak için ek işlem adımları gerekebilir.
Claude 3 öncelikle büyük miktarda metin verisi üzerinde eğitilmiştir, bu da bilgisayar görüşü görevlerinde yüksek performans elde etmek için gereken kapsamlı görsel veri kümelerinden yoksun olduğu anlamına gelir. Sonuç olarak, Claude 3 metni anlama ve oluşturmada başarılı olsa da, özellikle görsel veriler için tasarlanmış modellerde bulunan aynı yeterlilik düzeyinde görüntüleri işleme veya analiz etme yeteneğine sahip değildir. Bu sınırlama, görsel içeriği yorumlama veya oluşturma gerektiren uygulamalar için daha az etkili olmasını sağlar.
Diğer büyük dil modellerine benzer şekilde, Claude 3'ün sürekli olarak geliştirilmesi planlanıyor. Gelecekteki iyileştirmeler muhtemelen görüntü algılama ve nesne tanıma gibi daha iyi görsel görevlere ve doğal dil işleme görevlerindeki gelişmelere odaklanacaktır. Bu, diğer benzer görevlerin yanı sıra nesnelerin ve sahnelerin daha doğru ve ayrıntılı açıklamalarını sağlayacaktır.
Son olarak, Claude 3 üzerindeki devam eden araştırmalar, yorumlanabilirliği artırmaya, önyargıyı azaltmaya ve çeşitli veri kümelerinde genelleştirmeyi iyileştirmeye öncelik verecektir. Bu çabalar, modelin çeşitli uygulamalarda sağlam performansını sağlayacak ve çıktılarında güven ve güvenilirliği artıracaktır.
Claude 3 model kartı, modelin mimarisi, performansı ve etik hususları hakkında ayrıntılı bilgiler sağlayarak, Vision AI'daki geliştiriciler ve paydaşlar için değerli bir kaynaktır. Şeffaflığı ve hesap verebilirliği teşvik ederek, AI teknolojilerinin sorumlu ve etkili bir şekilde kullanılmasını sağlamaya yardımcı olur. Vision AI gelişmeye devam ederken, Claude 3'ünki gibi model kartlarının rolü, geliştirmeye rehberlik etmede ve AI sistemlerine olan güveni artırmada çok önemli olacaktır.
Ultralytics olarak, yapay zeka teknolojisini geliştirme konusunda tutkuluyuz. Yapay zeka çözümlerimizi keşfetmek ve en son yeniliklerimizden haberdar olmak için GitHub depomuzu ziyaret edin. Discord 'daki topluluğumuza katılın ve Sürücüsüz Otomobiller ve üretim gibi sektörleri nasıl dönüştürdüğümüzü keşfedin! 🚀


