


Llama 3.1'i tanımak: Meta'nın en son açık kaynaklı model ailesi

Meta'nın çok yönlü 8B, çok yönlü 70B ve bugüne kadarki en büyük ve en gelişmiş modeli olan amiral gemisi 405B'yi içeren yeni Llama 3.1 açık kaynak model ailesini keşfedin.

Meta'nın çok yönlü 8B, çok yönlü 70B ve bugüne kadarki en büyük ve en gelişmiş modeli olan amiral gemisi 405B'yi içeren yeni Llama 3.1 açık kaynak model ailesini keşfedin.
23 Temmuz 2024'te Meta, çok yönlü 8B, yetenekli 70B ve bugüne kadarki en büyük açık kaynaklı büyük dil modeli (LLM) olarak öne çıkan Llama 3.1 405B modellerini içeren yeni Llama 3.1 açık kaynaklı model ailesini yayınladı.
Bu yeni modelleri öncekilerden ayıran şeyin ne olduğunu merak ediyor olabilirsiniz. Bu makaleye derinlemesine daldıkça, Llama 3.1 modellerinin yayınlanmasının yapay zeka teknolojisinde önemli bir kilometre taşı olduğunu keşfedeceksiniz. Yeni yayınlanan modeller, doğal dil işlemede önemli iyileştirmeler sunuyor; dahası, önceki sürümlerde bulunmayan yeni özellikler ve geliştirmeler sunuyorlar. Bu sürüm, karmaşık görevler için yapay zekadan yararlanma şeklimizi değiştirmeyi vaat ediyor ve hem araştırmacılar hem de geliştiriciler için güçlü bir araç seti sağlıyor.
Bu makalede, Llama 3.1 model ailesini, mimarilerini, temel iyileştirmelerini, pratik kullanımlarını ve performanslarının ayrıntılı bir karşılaştırmasını inceleyeceğiz.
Meta'nın en yeni Büyük Dil Modeli Llama 3.1, OpenAI'nin Chat GPT-4o ve Anthropic'in Claude 3. 5 Sonnet gibi üst düzey modellerin yeteneklerine rakip olarak yapay zeka alanında önemli adımlar atıyor.
Önceki Llama 3 modelinde küçük bir güncelleme olarak kabul edilse de, Meta, yeni model ailesine bazı önemli iyileştirmeler getirerek bir adım daha ileri gitti ve şunları sunuyor:
Yukarıdakilerin hepsine ek olarak, yeni Llama 3.1 model ailesi etkileyici 405 milyar parametreli modeliyle büyük bir ilerlemeyi vurgulamaktadır. Bu önemli parametre sayısı, yapay zeka gelişiminde önemli bir sıçramayı temsil ediyor ve modelin karmaşık metinleri anlama ve üretme kapasitesini büyük ölçüde artırıyor. 405B modeli, her bir parametrenin modelin eğitim sırasında öğrendiği sinir ağındaki weights and biases atıfta bulunduğu kapsamlı bir parametre dizisi içerir. Bu, modelin daha karmaşık dil kalıplarını yakalamasına olanak tanıyarak büyük dil modelleri için yeni bir standart oluşturuyor ve yapay zeka teknolojisinin gelecekteki potansiyelini sergiliyor. Bu büyük ölçekli model, yalnızca çok çeşitli görevlerde performansı artırmakla kalmıyor, aynı zamanda yapay zekanın metin oluşturma ve anlama açısından başarabileceklerinin sınırlarını da zorluyor.
Llama 3.1, modern büyük dil modellerinin temel taşı olan yalnızca kod çözücü transformer model mimarisinden yararlanır. Bu mimari, karmaşık dil görevlerini işlemedeki verimliliği ve etkinliği ile ünlüdür. Transformer'ların kullanımı, Llama 3.1'in insan benzeri metni anlama ve oluşturmada mükemmel olmasını sağlayarak, LSTM'ler ve GRU'lar gibi daha eski mimarileri kullanan modellere göre önemli bir avantaj sağlar.
Ek olarak, Llama 3.1 model ailesi, eğitim verimliliğini ve kararlılığını artıran Uzmanlar Karışımı (MoE) mimarisini kullanır. MoE mimarisinden kaçınmak, daha tutarlı ve güvenilir bir eğitim süreci sağlar, çünkü MoE bazen model kararlılığını ve performansını etkileyebilecek karmaşıklıklar getirebilir.
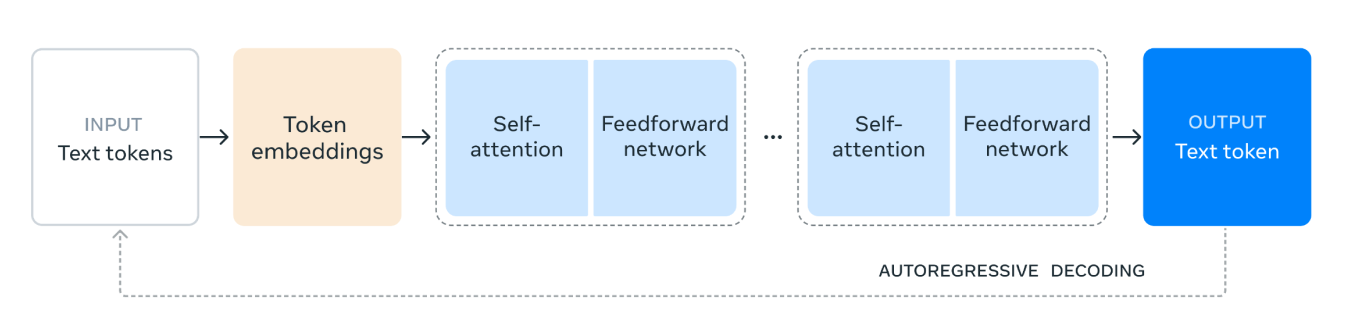
Llama 3.1 model mimarisi şu şekilde çalışır:
1. Girdi Metin Belirteçleri: Süreç, metin belirteçlerinden oluşan girdi ile başlar. Bu belirteçler, modelin işleyeceği kelimeler veya alt kelimeler gibi metnin bireysel birimleridir.
2. Token Gömme (Token Embeddings): Metin token'ları daha sonra token gömmelere dönüştürülür. Gömme, token'ların metin içindeki semantik anlamlarını ve ilişkilerini yakalayan yoğun vektör gösterimleridir. Bu dönüşüm, modelin sayısal verilerle çalışmasını sağladığı için çok önemlidir.
3. Kendiliğinden Dikkat Mekanizması (Self-Attention Mechanism): Kendiliğinden dikkat, modelin her bir token'ı kodlarken girdi dizisindeki farklı token'ların önemini tartmasına olanak tanır. Bu mekanizma, modelin dizideki konumlarından bağımsız olarak token'lar arasındaki bağlamı ve ilişkileri anlamasına yardımcı olur. Kendiliğinden dikkat mekanizmasında, girdi dizisindeki her bir token, bir sayı vektörü olarak temsil edilir. Bu vektörler, üç farklı türde gösterim oluşturmak için kullanılır: sorgular, anahtarlar ve değerler.
Model, sorgu vektörlerini anahtar vektörleriyle karşılaştırarak her bir belirtecin diğer belirteçlere ne kadar dikkat etmesi gerektiğini hesaplar. Bu karşılaştırma, her bir belirtecin diğerleriyle ilişkili olarak alaka düzeyini gösteren puanlarla sonuçlanır.
4. İleri Besleme Ağı: Öz dikkat sürecinden sonra veriler ileri beslemeli bir ağdan geçer. Bu ağ, verilere doğrusal olmayan dönüşümler uygulayan ve modelin karmaşık örüntüleri tanımasına ve öğrenmesine yardımcı olan tam bağlantılı bir sinir ağıdır.
5. Tekrarlanan Katmanlar (Repeated Layers): Kendiliğinden dikkat ve ileri beslemeli ağ katmanları birden çok kez üst üste yığılır. Bu tekrarlanan uygulama, modelin verilerdeki daha karmaşık bağımlılıkları ve kalıpları yakalamasına olanak tanır.
6. Çıktı Metin Token'ı (Output Text Token): Son olarak, işlenen veriler çıktı metin token'ını oluşturmak için kullanılır. Bu token, modelin girdi bağlamına göre dizideki bir sonraki kelime veya alt kelime için yaptığı tahmindir.
Kıyaslama testleri, Llama 3.1'in yalnızca bu son teknoloji modellere karşı kendini kanıtlamakla kalmayıp, aynı zamanda belirli görevlerde onlardan daha iyi performans gösterdiğini ve üstün performansını sergilediğini ortaya koyuyor.
Llama 3.1 modeli, 150'den fazla kıyaslama veri kümesi üzerinde kapsamlı bir değerlendirmeye tabi tutulmuştur ve burada diğer önde gelen büyük dil modelleriyle titizlikle karşılaştırılmıştır. Yeni yayınlanan serideki en yetenekli model olarak kabul edilen Llama 3.1 405B modeli, OpenAI'ın GPT-4'ü ve Claude 3.5 Sonnet gibi sektör devlerine karşı kıyaslanmıştır. Bu karşılaştırmalardan elde edilen sonuçlar, Llama 3.1'in çeşitli görevlerde üstün performans ve yeteneklerini sergileyerek rekabetçi bir avantaja sahip olduğunu ortaya koymaktadır.
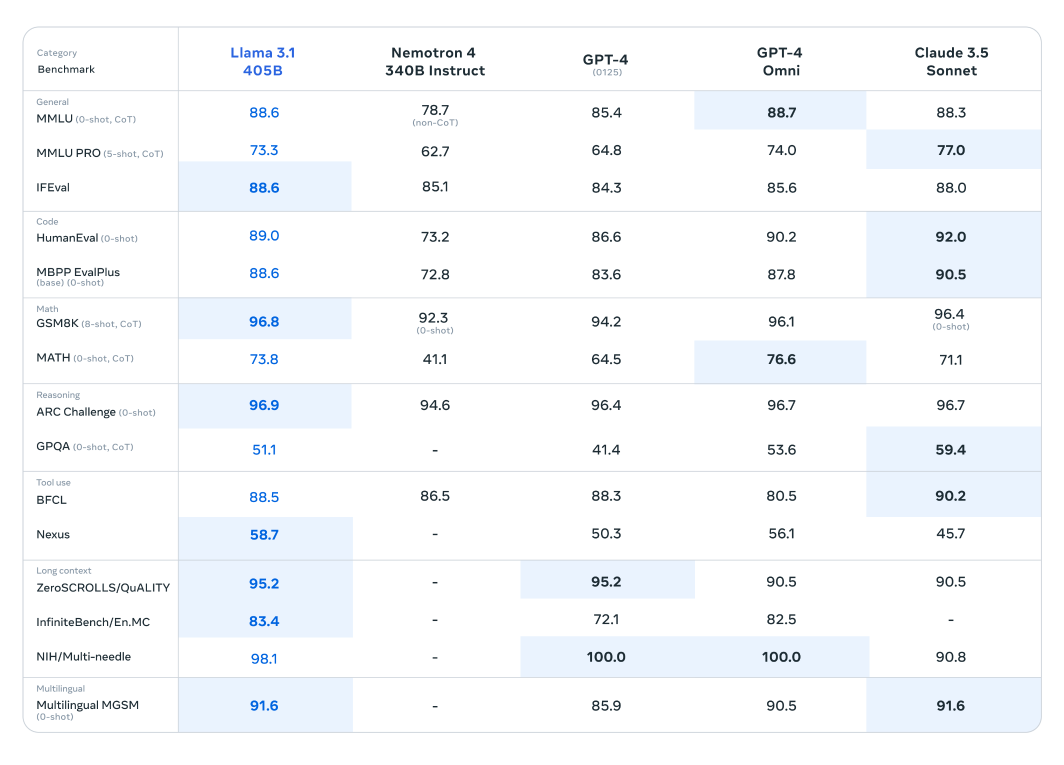
Bu modelin etkileyici parametre sayısı ve gelişmiş mimarisi, karmaşık anlama ve metin oluşturma konularında üstün performans göstermesini sağlar ve genellikle belirli kıyaslamalarda rakiplerini geride bırakır. Bu değerlendirmeler, Llama 3.1'in büyük dil modelleri alanında yeni standartlar belirleme potansiyelini vurgulayarak, araştırmacılara ve geliştiricilere çeşitli uygulamalar için güçlü bir araç sunar.
Daha küçük ve daha hafif Llama modelleri de benzerlerine kıyasla dikkat çekici bir performans sergilemektedir. Llama 3.1 70B modeli, Mistral 8x22B ve GPT-3.5 Turbo gibi daha büyük modellere karşı değerlendirilmiştir. Örneğin, Llama 3.1 70B modeli, ARC Challenge veri kümesi gibi akıl yürütme veri kümelerinde ve HumanEval veri kümeleri gibi kodlama veri kümelerinde sürekli olarak üstün performans göstermektedir. Bu sonuçlar, Llama 3.1 serisinin farklı model boyutlarındaki çok yönlülüğünü ve sağlamlığını vurgulayarak, onu çok çeşitli uygulamalar için değerli bir araç haline getirmektedir.
Ek olarak, Llama 3.1 8B modeli, Gemma 2 9B ve Mistral 7B dahil olmak üzere benzer boyuttaki modellere karşı kıyaslanmıştır. Bu karşılaştırmalar, Llama 3.1 8B modelinin, akıl yürütme için GPQA veri kümesi ve kodlama için MBPP EvalPlus gibi farklı türlerdeki çeşitli kıyaslama veri kümelerinde rakiplerinden daha iyi performans gösterdiğini ve daha küçük parametre sayısına rağmen verimliliğini ve yeteneğini sergilediğini ortaya koymaktadır.

Meta, yeni modellerin kullanıcılar için çeşitli pratik ve faydalı şekillerde uygulanmasını sağladı:
Kullanıcılar artık belirli kullanım durumları için en son Llama 3.1 modellerini ince ayar yapabilirler. Bu işlem, modelin daha önce maruz kalmadığı yeni harici veriler üzerinde eğitilmesini içerir ve böylece hedeflenen uygulamalar için performansı ve uyarlanabilirliği artırılır. İnce ayar, modelin belirli alanlarla veya görevlerle ilgili içeriği daha iyi anlamasını ve oluşturmasını sağlayarak önemli bir avantaj sağlar.
Llama 3.1 modelleri artık Retrieval-Augmented Generation (RAG) sistemlerine sorunsuz bir şekilde entegre edilebilir. Bu entegrasyon, modelin harici veri kaynaklarından dinamik olarak yararlanmasını sağlayarak, doğru ve bağlamsal olarak alakalı yanıtlar verme yeteneğini geliştirir. Llama 3.1, büyük veri kümelerinden bilgi alıp üretim sürecine dahil ederek, bilgi yoğun görevlerdeki performansını önemli ölçüde artırır ve kullanıcılara daha kesin ve bilgilendirilmiş çıktılar sunar.
Ayrıca, belirli kullanım durumları için özel modellerin performansını artırarak, yüksek kaliteli sentetik veri oluşturmak için 405 milyar parametreli modeli de kullanabilirsiniz. Bu yaklaşım, hedeflenmiş ve alakalı veriler üretmek için Llama 3.1'in kapsamlı yeteneklerinden yararlanarak, uyarlanmış yapay zeka uygulamalarının doğruluğunu ve verimliliğini artırır.
Llama 3.1 sürümü, Meta'nın yapay zeka teknolojisini geliştirme taahhüdünü sergileyerek büyük dil modelleri alanında önemli bir sıçramayı temsil etmektedir.
Llama 3.1, önemli parametre sayısı, çeşitli veri kümeleri üzerinde kapsamlı eğitimi ve sağlam ve istikrarlı eğitim süreçlerine odaklanmasıyla, doğal dil işlemede performans ve yetenek için yeni ölçütler belirlemektedir. İster metin oluşturma, özetleme veya karmaşık konuşma görevlerinde olsun, Llama 3.1 diğer önde gelen modellere göre rekabetçi bir avantaj göstermektedir. Bu model sadece yapay zekanın bugün başarabileceklerinin sınırlarını zorlamakla kalmıyor, aynı zamanda sürekli gelişen yapay zeka ortamında gelecekteki yenilikler için de zemin hazırlıyor.
Ultralytics olarak, kendimizi yapay zeka teknolojisinin sınırlarını zorlamaya adadık. Son teknoloji yapay zeka çözümlerimizi keşfetmek ve en son yeniliklerimizi takip etmek için GitHub depomuza göz atın. Discord 'daki canlı topluluğumuza katılın ve sürücüsüz otomobiller ve üretim gibi sektörlerde nasıl devrim yarattığımızı görün! 🚀


