



اكتشف عائلة نماذج Llama 3.1 مفتوحة المصدر الجديدة من Meta، والتي تتميز بالنموذج متعدد الاستخدامات 8B، والنموذج الشامل 70B، والنموذج الرائد 405B، وهو أكبر نماذجها وأكثرها تقدمًا حتى الآن.

اكتشف عائلة نماذج Llama 3.1 مفتوحة المصدر الجديدة من Meta، والتي تتميز بالنموذج متعدد الاستخدامات 8B، والنموذج الشامل 70B، والنموذج الرائد 405B، وهو أكبر نماذجها وأكثرها تقدمًا حتى الآن.
في 23 يوليو 2024، أصدرت Meta عائلة Llama 3.1 الجديدة مفتوحة المصدر من النماذج، والتي تتميز بـ 8B متعددة الاستخدامات، و 70B القادرة، ونماذج Llama 3.1 405B، مع كون الأحدث هو الأكبر من بين نماذج اللغة الكبيرة مفتوحة المصدر (LLM) حتى الآن.
قد تتساءل عما يميز هذه النماذج الجديدة عن سابقاتها. حسنًا، بينما نتعمق في هذه المقالة، ستكتشف أن إصدار نماذج Llama 3.1 يمثل علامة فارقة مهمة في تكنولوجيا الذكاء الاصطناعي. تقدم النماذج التي تم إصدارها حديثًا تحسينات كبيرة في معالجة اللغة الطبيعية؛ علاوة على ذلك، فإنها تقدم ميزات وتحسينات جديدة غير موجودة في الإصدارات السابقة. يعد هذا الإصدار بتغيير الطريقة التي نستفيد بها من الذكاء الاصطناعي للمهام المعقدة، مما يوفر مجموعة أدوات قوية للباحثين والمطورين على حد سواء.
في هذه المقالة، سوف نستكشف عائلة نماذج Llama 3.1، ونتعمق في بنيتها وتحسيناتها الرئيسية واستخداماتها العملية ومقارنة مفصلة لأدائها.
يحقق أحدث نماذج اللغات الكبيرة من Meta، وهو Llama 3.1، خطوات كبيرة في مجال الذكاء الاصطناعي، حيث ينافس قدرات النماذج من الدرجة الأولى مثل OpenAI's Chat GPT-4o وClaude 3.5 Sonnet من Anthropic.
على الرغم من أنه قد يعتبر تحديثًا طفيفًا على نموذج Llama 3 السابق، فقد اتخذت Meta خطوة أخرى إلى الأمام من خلال تقديم بعض التحسينات الرئيسية على عائلة النماذج الجديدة، حيث قدمت:
بالإضافة إلى كل ما سبق، تبرز عائلة نماذج Llama 3.1 الجديدة تقدماً كبيراً من خلال نموذجها المثير للإعجاب الذي يبلغ 405 مليار معلمة. ويمثل هذا العدد الكبير من المعلمات قفزة كبيرة إلى الأمام في تطوير الذكاء الاصطناعي، مما يعزز بشكل كبير من قدرة النموذج على فهم النص المعقد وتوليد نصوص معقدة. يتضمن نموذج 405 مليار معلمة مجموعة واسعة من المعلمات مع كل معلمة تشير إلى weights and biases في الشبكة العصبية التي يتعلمها النموذج أثناء التدريب. يسمح ذلك للنموذج بالتقاط أنماط لغوية أكثر تعقيداً، مما يضع معياراً جديداً للنماذج اللغوية الكبيرة ويعرض الإمكانات المستقبلية لتكنولوجيا الذكاء الاصطناعي. لا يحسّن هذا النموذج واسع النطاق الأداء في مجموعة واسعة من المهام فحسب، بل يدفع أيضًا حدود ما يمكن أن يحققه الذكاء الاصطناعي من حيث توليد النصوص وفهمها.
تستفيد Llama 3.1 من بنية نموذج المحول فك التشفير فقط، وهي حجر الزاوية لنماذج اللغة الكبيرة الحديثة. تشتهر هذه البنية بكفاءتها وفعاليتها في التعامل مع مهام اللغة المعقدة. يُمكّن استخدام المحولات Llama 3.1 من التفوق في فهم وإنشاء نص شبيه بالنص البشري، مما يوفر ميزة كبيرة على النماذج التي تستخدم بنيات أقدم مثل LSTMs و GRUs.
بالإضافة إلى ذلك، تستخدم عائلة نماذج Llama 3.1 هندسة Mixture of Experts (MoE)، مما يعزز كفاءة التدريب واستقراره. تجنب هندسة MoE يضمن عملية تدريب أكثر اتساقًا وموثوقية، حيث يمكن أن تقدم MoE أحيانًا تعقيدات قد تؤثر على استقرار النموذج وأدائه.
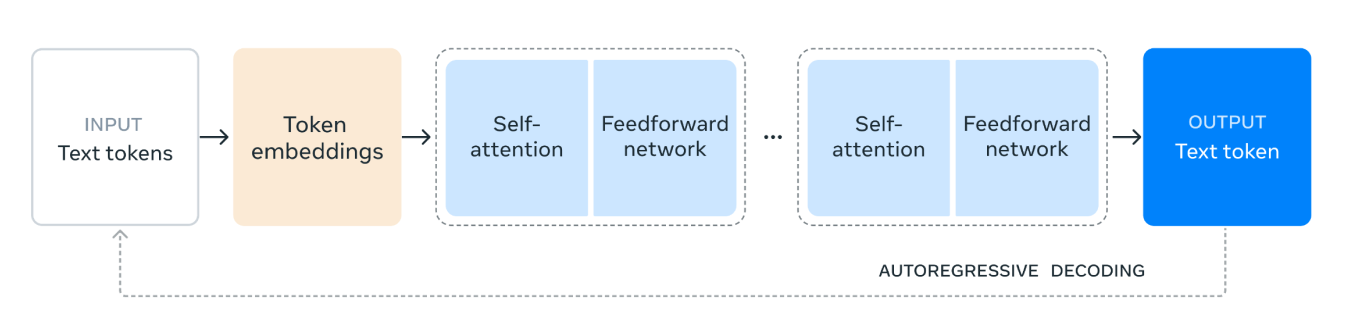
تعمل بنية نموذج Llama 3.1 على النحو التالي:
1. رموز نص الإدخال: تبدأ العملية بالإدخال، الذي يتكون من رموز نصية. هذه الرموز هي وحدات فردية من النص، مثل الكلمات أو أجزاء الكلمات، التي سيعالجها النموذج.
2. تضمين الرموز (Token Embeddings): يتم بعد ذلك تحويل الرموز النصية إلى تضمينات للرموز. التضمينات هي تمثيلات متجهة كثيفة للرموز التي تلتقط معناها الدلالي وعلاقاتها داخل النص. هذا التحويل ضروري لأنه يسمح للنموذج بالعمل مع البيانات الرقمية.
3. آلية الانتباه الذاتي (Self-Attention Mechanism): يسمح الانتباه الذاتي للنموذج بتقدير أهمية الرموز المختلفة في تسلسل الإدخال عند ترميز كل رمز. تساعد هذه الآلية النموذج على فهم السياق والعلاقات بين الرموز، بغض النظر عن مواقعها في التسلسل. في آلية الانتباه الذاتي، يتم تمثيل كل رمز في تسلسل الإدخال كمتجه من الأرقام. تُستخدم هذه المتجهات لإنشاء ثلاثة أنواع مختلفة من التمثيلات: الاستعلامات والمفاتيح والقيم.
يحسب النموذج مقدار الانتباه الذي يجب أن توليه كل وحدة (token) للوحدات الأخرى عن طريق مقارنة متجهات الاستعلام بمتجهات المفتاح. تؤدي هذه المقارنة إلى نتائج تشير إلى مدى أهمية كل وحدة بالنسبة للآخرين.
4. شبكة تغذية أمامية: بعد عملية الانتباه الذاتي، تمر البيانات من خلال شبكة تغذية أمامية. هذه الشبكة هي شبكة عصبية متصلة بالكامل تطبق تحويلات غير خطية على البيانات، مما يساعد النموذج على التعرف على الأنماط المعقدة وتعلمها.
5. طبقات متكررة (Repeated Layers): يتم تكديس طبقات الانتباه الذاتي وشبكة التغذية الأمامية عدة مرات. يسمح هذا التطبيق المتكرر للنموذج بالتقاط المزيد من التبعيات والأنماط المعقدة في البيانات.
6. رمز نص الإخراج (Output Text Token): أخيرًا، تُستخدم البيانات المعالجة لإنشاء رمز نص الإخراج. هذا الرمز هو تنبؤ النموذج للكلمة التالية أو الكلمة الفرعية في التسلسل، بناءً على سياق الإدخال.
تكشف الاختبارات المعيارية أن Llama 3.1 لا يحتفظ بمكانته في مواجهة هذه النماذج الحديثة فحسب، بل يتفوق عليها أيضًا في مهام معينة، مما يدل على أدائه المتفوق.
خضع نموذج Llama 3.1 لتقييم مكثف عبر أكثر من 150 مجموعة بيانات معيارية، حيث تمت مقارنته بدقة مع نماذج لغوية كبيرة رائدة أخرى. تم قياس أداء نموذج Llama 3.1 405B، المعترف به باعتباره الأكثر قدرة في السلسلة التي تم إصدارها حديثًا، مقابل عمالقة الصناعة مثل GPT-4 من OpenAI و Claude 3.5 Sonnet. تكشف النتائج المستخلصة من هذه المقارنات أن Llama 3.1 يظهر ميزة تنافسية، مما يدل على أدائه وقدراته الفائقة في مختلف المهام.
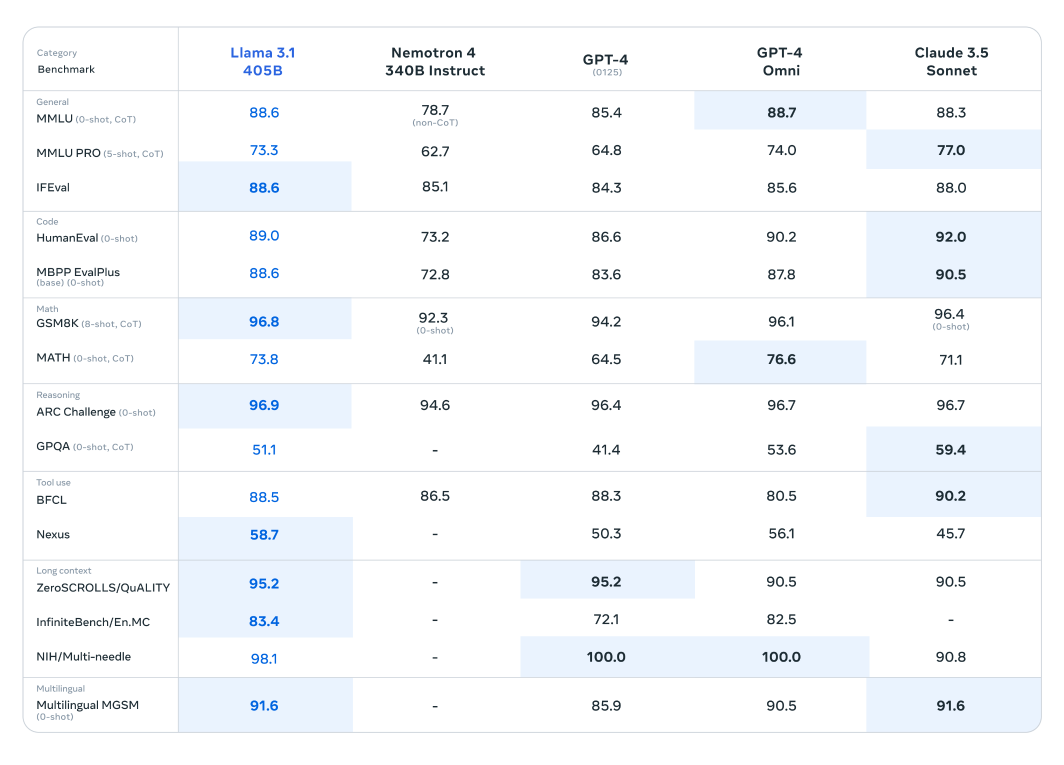
تُمكّن هذه المعلمات الرائعة للنموذج وهندسته المتقدمة من التفوق في الفهم المعقد وإنشاء النصوص، وغالبًا ما تتجاوز منافسيها في معايير محددة. تسلط هذه التقييمات الضوء على إمكانات Llama 3.1 لوضع معايير جديدة في مجال نماذج اللغة الكبيرة، وتزويد الباحثين والمطورين بأداة قوية للتطبيقات المتنوعة.
تُظهر نماذج Llama الأصغر حجمًا والأخف وزنًا أداءً ملحوظًا أيضًا عند مقارنتها بنظيراتها. تم تقييم نموذج Llama 3.1 70B مقابل نماذج أكبر مثل Mistral 8x22B و GPT-3.5 Turbo. على سبيل المثال، يُظهر نموذج Llama 3.1 70B باستمرار أداءً فائقًا في مجموعات بيانات الاستدلال مثل مجموعة بيانات ARC Challenge ومجموعات بيانات الترميز مثل مجموعات بيانات HumanEval. تسلط هذه النتائج الضوء على تنوع وقوة سلسلة Llama 3.1 عبر أحجام النماذج المختلفة، مما يجعلها أداة قيمة لمجموعة واسعة من التطبيقات.
بالإضافة إلى ذلك، تمت مقارنة نموذج Llama 3.1 8B بنماذج ذات حجم مماثل، بما في ذلك Gemma 2 9B و Mistral 7B. تكشف هذه المقارنات أن نموذج Llama 3.1 8B يتفوق على منافسيه في مجموعات البيانات المعيارية المختلفة في أنواع مختلفة مثل مجموعة بيانات GPQA للاستدلال و MBPP EvalPlus للترميز، مما يدل على كفاءته وقدرته على الرغم من عدد المعلمات الأصغر.

مكنت Meta النماذج الجديدة من استخدامها في مجموعة متنوعة من الطرق العملية والمفيدة للمستخدمين:
يمكن للمستخدمين الآن ضبط أحدث نماذج Llama 3.1 لحالات استخدام محددة. تتضمن هذه العملية تدريب النموذج على بيانات خارجية جديدة لم يتعرض لها سابقًا، وبالتالي تعزيز أدائه وقابليته للتكيف مع التطبيقات المستهدفة. يمنح الضبط الدقيق النموذج ميزة كبيرة من خلال تمكينه من فهم المحتوى ذي الصلة بمجالات أو مهام معينة وإنشائه بشكل أفضل.
يمكن الآن دمج نماذج Llama 3.1 بسلاسة في أنظمة الاسترجاع المعزز (RAG). يتيح هذا التكامل للنموذج الاستفادة من مصادر البيانات الخارجية ديناميكيًا، مما يعزز قدرته على تقديم استجابات دقيقة وذات صلة بالسياق. من خلال استرجاع المعلومات من مجموعات البيانات الكبيرة ودمجها في عملية الإنشاء، تحسن Llama 3.1 بشكل كبير من أدائها في المهام كثيفة المعرفة، مما يوفر للمستخدمين مخرجات أكثر دقة واستنارة.
يمكنك أيضًا الاستفادة من نموذج 405 مليار معلمة لإنشاء بيانات تركيبية عالية الجودة، مما يعزز أداء النماذج المتخصصة لحالات استخدام محددة. يعتمد هذا النهج على الإمكانات الواسعة لـ Llama 3.1 لإنتاج بيانات مستهدفة وذات صلة، وبالتالي تحسين دقة وكفاءة تطبيقات الذكاء الاصطناعي المصممة خصيصًا.
يمثل إصدار Llama 3.1 قفزة كبيرة إلى الأمام في مجال نماذج اللغة الكبيرة، مما يدل على التزام Meta بتطوير تكنولوجيا الذكاء الاصطناعي.
بفضل عدد المعلمات الكبير والتدريب المكثف على مجموعات بيانات متنوعة والتركيز على عمليات التدريب القوية والمستقرة، يضع Llama 3.1 معايير جديدة للأداء والقدرة في معالجة اللغة الطبيعية. سواء كان ذلك في إنشاء النصوص أو التلخيص أو المهام الحوارية المعقدة، يُظهر Llama 3.1 تفوقًا تنافسيًا على النماذج الرائدة الأخرى. لا يدفع هذا النموذج حدود ما يمكن أن يحققه الذكاء الاصطناعي اليوم فحسب، بل يمهد الطريق أيضًا للابتكارات المستقبلية في المشهد المتطور باستمرار للذكاء الاصطناعي.
نحن في Ultralytics ملتزمون بتخطي حدود تكنولوجيا الذكاء الاصطناعي. لاستكشاف حلولنا المتطورة في مجال الذكاء الاصطناعي ومواكبة أحدث ابتكاراتنا، اطلع على مستودع GitHub الخاص بنا. انضم إلى مجتمعنا النابض بالحياة على Discord وشاهد كيف نحدث ثورة في صناعات مثل السيارات ذاتية القيادة والتصنيع! 🚀


