



انضم إلينا بينما نلقي نظرة على تطور اكتشاف الأجسام. سنركز على كيفية تطور نماذج YOLO (أنت تنظر مرة واحدة فقط) في السنوات الأخيرة.

انضم إلينا بينما نلقي نظرة على تطور اكتشاف الأجسام. سنركز على كيفية تطور نماذج YOLO (أنت تنظر مرة واحدة فقط) في السنوات الأخيرة.
الرؤية الحاسوبية هي فرع من فروع الذكاء الاصطناعي (AI) يركز على تعليم الآلات رؤية وفهم الصور ومقاطع الفيديو، على غرار كيفية إدراك البشر للعالم الحقيقي. في حين أن التعرف على الكائنات أو تحديد الإجراءات هو أمر طبيعي بالنسبة للبشر، إلا أن هذه المهام تتطلب تقنيات رؤية حاسوبية محددة ومتخصصة عندما يتعلق الأمر بالآلات. على سبيل المثال، إحدى المهام الرئيسية في الرؤية الحاسوبية هي اكتشاف الكائنات، والتي تتضمن تحديد وتحديد موقع الكائنات داخل الصور أو مقاطع الفيديو.
منذ ستينيات القرن العشرين، يعمل الباحثون على تحسين كيفية detect أجهزة الكمبيوتر للأشياء. تضمنت الأساليب المبكرة، مثل مطابقة القوالب، تمرير قالب محدد مسبقاً عبر الصورة للعثور على التطابق. وعلى الرغم من أن هذه الأساليب كانت مبتكرة، إلا أنها واجهت صعوبات في التعامل مع التغيرات في حجم الجسم واتجاهه وإضاءته. اليوم، لدينا نماذج متقدمة مثل Ultralytics YOLO11 التي يمكنها detect حتى الأجسام الصغيرة والمخفية جزئيًا، والمعروفة باسم الأجسام المحجوبة، بدقة مذهلة.
مع استمرار تطور الرؤية الحاسوبية، من المهم إلقاء نظرة على كيفية تطور هذه التقنيات. في هذه المقالة، سنستكشف تطور اكتشاف الأجسام وسنسلط الضوء على تطور نماذجYOLO (أنت تنظر مرة واحدة فقط). لنبدأ!
قبل الغوص في اكتشاف الأجسام، دعونا نلقي نظرة على كيفية بدء الرؤية الحاسوبية. تعود أصول الرؤية الحاسوبية إلى أواخر الخمسينيات وأوائل الستينيات عندما بدأ العلماء في استكشاف كيفية معالجة الدماغ للمعلومات البصرية. في التجارب التي أجريت على القطط، اكتشف الباحثان ديفيد هابل وتورستن فيزل أن الدماغ يتفاعل مع الأنماط البسيطة مثل الحواف والخطوط. وقد شكل ذلك الأساس للفكرة الكامنة وراء استخراج الملامح - وهو المفهوم الذي يقوم على أن الأنظمة البصرية detect وتتعرف على الملامح الأساسية في الصور، مثل الحواف، قبل الانتقال إلى أنماط أكثر تعقيداً.

في نفس الوقت تقريبًا، ظهرت تقنية جديدة يمكنها تحويل الصور المادية إلى تنسيقات رقمية، مما أثار الاهتمام بكيفية معالجة الآلات للمعلومات المرئية. في عام 1966، دفع مشروع الرؤية الصيفي لمعهد ماساتشوستس للتكنولوجيا (MIT) الأمور إلى الأمام. على الرغم من أن المشروع لم ينجح تمامًا، إلا أنه كان يهدف إلى إنشاء نظام يمكنه فصل المقدمة عن الخلفية في الصور. بالنسبة للكثيرين في مجتمع الذكاء الاصطناعي البصري، يمثل هذا المشروع البداية الرسمية لـ رؤية الحاسوب كمجال علمي.
مع تقدم الرؤية الحاسوبية في أواخر التسعينيات وأوائل العقد الأول من القرن الحادي والعشرين، تحولت أساليب اكتشاف الأجسام من التقنيات الأساسية مثل مطابقة القوالب إلى أساليب أكثر تقدمًا. كانت إحدى الطرق الشائعة هي Haar Cascade، والتي أصبحت تُستخدم على نطاق واسع في مهام مثل اكتشاف الوجوه. تعمل هذه الطريقة من خلال مسح الصور باستخدام نافذة منزلقة، والتحقق من وجود ميزات محددة مثل الحواف أو القوام في كل قسم من الصورة، ثم دمج هذه الميزات detect الأجسام مثل الوجوه. كانت Haar Cascade أسرع بكثير من الطرق السابقة.
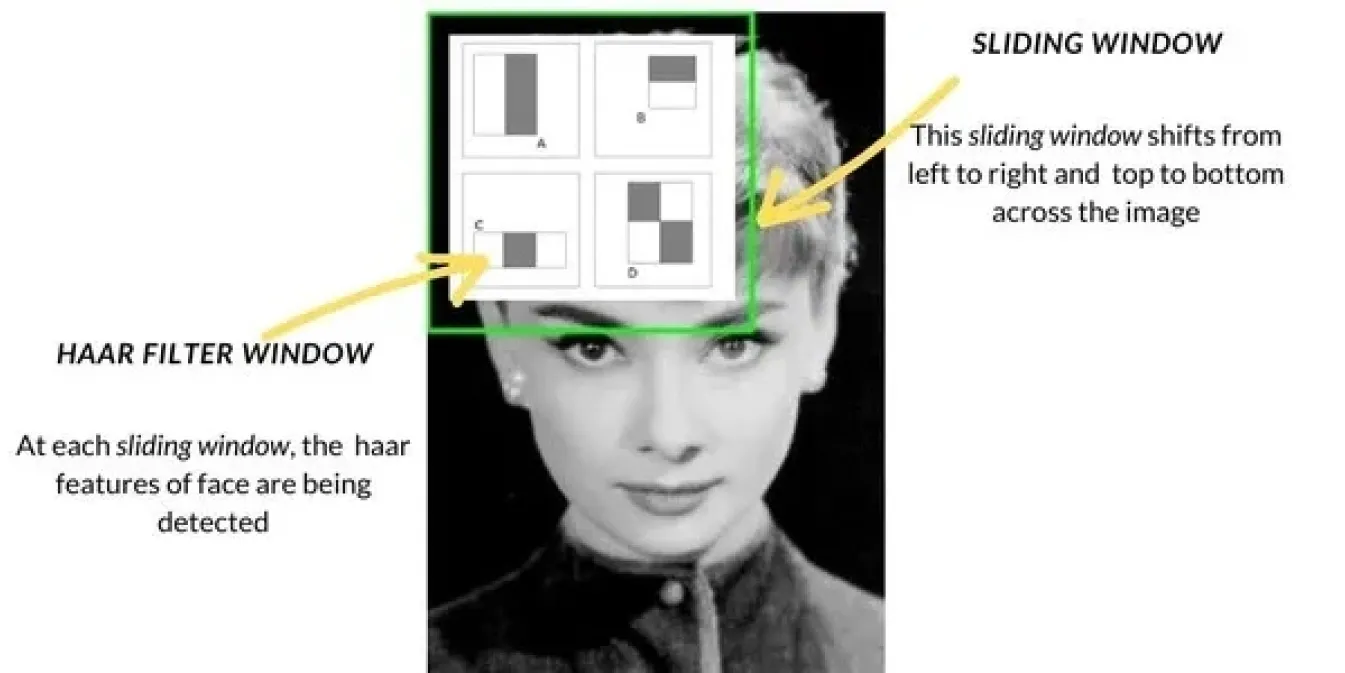
إلى جانب ذلك، تم أيضًا تقديم طرق مثل Histogram of Oriented Gradients (HOG) و Support Vector Machines (SVMs). استخدمت HOG تقنية النافذة المنزلقة لتحليل كيفية تغير الضوء والظلال في أقسام صغيرة من الصورة، مما يساعد على تحديد الكائنات بناءً على أشكالها. ثم قامت SVMs بـ تصنيف هذه الميزات لتحديد هوية الكائن. هذه الطرق حسّنت الدقة ولكنها لا تزال تعاني في البيئات الواقعية وكانت أبطأ مقارنة بتقنيات اليوم.
في عام 2010، أدى ظهور التعلم العميق و الشبكات العصبونية الالتفافية (CNNs) إلى تحول كبير في اكتشاف الكائنات. مكّنت CNNs أجهزة الحاسوب من تعلم الميزات المهمة تلقائيًا من كميات كبيرة من البيانات، مما جعل الاكتشاف أكثر دقة.
كانت النماذج المبكرة مثل R-CNN (الشبكات العصبونية الالتفافية القائمة على المناطق) بمثابة تحسن كبير في الدقة، مما ساعد على تحديد الكائنات بدقة أكبر من الطرق القديمة.
ومع ذلك، كانت هذه النماذج بطيئة لأنها عالجت الصور على مراحل متعددة، مما جعلها غير عملية للتطبيقات في الوقت الفعلي في مجالات مثل السيارات ذاتية القيادة أو المراقبة بالفيديو.
مع التركيز على تسريع الأمور، تم تطوير نماذج أكثر كفاءة. ساعدت نماذج مثل Fast R-CNN و Faster R-CNN من خلال تحسين كيفية اختيار مناطق الاهتمام وتقليل عدد الخطوات اللازمة للاكتشاف. في حين أن هذا جعل اكتشاف الكائنات أسرع، إلا أنه لم يكن سريعًا بما يكفي للعديد من التطبيقات الواقعية التي تحتاج إلى نتائج فورية. دفع الطلب المتزايد على الاكتشاف في الوقت الفعلي إلى تطوير حلول أسرع وأكثر كفاءة يمكنها تحقيق التوازن بين السرعة والدقة.

YOLO هو نموذج للكشف عن الأجسام أعاد تعريف الرؤية الحاسوبية من خلال تمكين الكشف عن الأجسام المتعددة في الصور ومقاطع الفيديو في الوقت الحقيقي، مما يجعله فريدًا تمامًا عن طرق الكشف السابقة. بدلاً من تحليل كل كائن تم اكتشافه على حدة، تتعامل بنيةYOLO مع اكتشاف الأجسام كمهمة واحدة، حيث تتنبأ بكل من موقع وفئة الأجسام دفعة واحدة باستخدام شبكات CNN.
يعمل النموذج عن طريق تقسيم الصورة إلى شبكة، مع تحمل كل جزء مسؤولية اكتشاف الكائنات في منطقته الخاصة. يقدم تنبؤات متعددة لكل قسم و يقوم بتصفية النتائج الأقل ثقة، مع الاحتفاظ فقط بالنتائج الدقيقة.

أدى إدخال YOLO في تطبيقات الرؤية الحاسوبية إلى جعل اكتشاف الأجسام أسرع بكثير وأكثر كفاءة من النماذج السابقة. وبسبب سرعته ودقته، سرعان ما أصبح YOLO خيارًا شائعًا لحلول الوقت الحقيقي في صناعات مثل التصنيع والرعاية الصحية والروبوتات.
من النقاط المهمة الأخرى التي تجدر الإشارة إليها هي أنه نظرًا لأن YOLO كان مفتوح المصدر، فقد تمكن المطورون والباحثون من تحسينه باستمرار، مما أدى إلى إصدارات أكثر تقدمًا.
لقد تحسنت نماذج YOLO بشكل مطرد مع مرور الوقت، مع الاستفادة من التطورات التي طرأت على كل إصدار. إلى جانب تحسين الأداء، جعلت هذه التحسينات النماذج أسهل استخدامًا للأشخاص ذوي المستويات المختلفة من الخبرة التقنية.
على سبيل المثال، عندما Ultralytics YOLOv5 أصبح نشر النماذج أكثر بساطةً باستخدام PyTorchمما سمح لمجموعة أكبر من المستخدمين بالعمل مع الذكاء الاصطناعي المتقدم. لقد جمع بين الدقة وسهولة الاستخدام، مما منح المزيد من الأشخاص القدرة على تنفيذ اكتشاف الكائنات دون الحاجة إلى أن يكونوا خبراء في البرمجة.
Ultralytics YOLOv8 واصل هذا التقدم بإضافة دعم لمهام مثل تجزئة النماذج وجعل النماذج أكثر مرونة. أصبح من الأسهل استخدام YOLO للتطبيقات الأساسية والأكثر تعقيدًا على حد سواء، مما يجعله مفيدًا عبر مجموعة من السيناريوهات.
مع أحدث طراز Ultralytics YOLO11تم إجراء المزيد من التحسينات. من خلال تقليل عدد المعلمات مع تحسين الدقة، أصبح الآن أكثر كفاءة للمهام في الوقت الفعلي. سواءً كنت مطورًا متمرسًا أو جديدًا في مجال الذكاء الاصطناعي، فإن YOLO11 يقدم نهجًا متقدمًا لاكتشاف الكائنات يمكن الوصول إليه بسهولة.
يدعم YOLO11 الذي تم إطلاقه في الحدث السنوي الهجين الذي تنظمه Ultralytics YOLO Vision 2024 (YV24)، مهام الرؤية الحاسوبية نفسها التي يدعمها YOLOv8 مثل اكتشاف الأجسام، وتجزئة النماذج، وتصنيف الصور، وتقدير الوضعية. لذلك، يمكن للمستخدمين التبديل بسهولة إلى هذا النموذج الجديد دون الحاجة إلى تعديل سير عملهم. بالإضافة إلى ذلك، فإن بنية YOLO11المطورة تجعل التنبؤات أكثر دقة. في الواقع، يُحقق YOLO11m متوسط دقة أعلى في مجموعة بياناتCOCO بمتوسط دقة أعلىmAP) على مجموعة بياناتCOCO بمعلمات أقل بنسبة 22% من YOLOv8m.
صُمم YOLO11 أيضًا ليعمل بكفاءة على مجموعة من الأنظمة الأساسية، بدءًا من الهواتف الذكية والأجهزة المتطورة الأخرى إلى الأنظمة السحابية الأكثر قوة. تضمن هذه المرونة أداءً سلسًا عبر إعدادات الأجهزة المختلفة لتطبيقات الوقت الحقيقي. وعلاوة على ذلك، فإن YOLO11 أسرع وأكثر كفاءة، مما يقلل من التكاليف الحسابية ويسرّع من أوقات الاستدلال. سواءً كنت تستخدم حزمةUltralytics Python أو Ultralytics HUB بدون رموز، فمن السهل دمج YOLO11 في سير عملك الحالي.
إن تأثير الاكتشاف المتقدم للأجسام على التطبيقات في الوقت الفعلي والذكاء الاصطناعي المتطور أصبح ملموساً بالفعل في مختلف القطاعات. فمع تزايد اعتماد قطاعات مثل النفط والغاز والرعاية الصحية وتجارة التجزئة على الذكاء الاصطناعي، يتزايد الطلب على الكشف السريع والدقيق عن الأجسام. يهدف YOLO11 إلى تلبية هذا الطلب من خلال تمكين الاكتشاف عالي الأداء حتى على الأجهزة ذات القدرة الحاسوبية المحدودة.
مع نمو الذكاء الاصطناعي المتطور، من المرجح أن تصبح نماذج اكتشاف الكائنات مثل YOLO11 أكثر أهمية لاتخاذ القرارات في الوقت الحقيقي في البيئات التي تكون فيها السرعة والدقة أمرًا بالغ الأهمية. مع التحسينات المستمرة في التصميم والقدرة على التكيف، يبدو أن مستقبل اكتشاف الكائنات سيجلب المزيد من الابتكارات عبر مجموعة متنوعة من التطبيقات.
لقد قطع اكتشاف الأجسام شوطًا طويلاً، حيث تطور من الأساليب البسيطة إلى تقنيات التعلم العميق المتقدمة التي نراها اليوم. كانت نماذج YOLO في قلب هذا التقدم، حيث قدمت اكتشافًا أسرع وأكثر دقة في الوقت الحقيقي في مختلف الصناعات. يبني YOLO11 على هذا الإرث القديم، حيث يعمل على تحسين الكفاءة وخفض التكاليف الحسابية وتعزيز الدقة، مما يجعله خيارًا موثوقًا لمجموعة متنوعة من التطبيقات في الوقت الفعلي. مع التطورات المستمرة في مجال الذكاء الاصطناعي والرؤية الحاسوبية، يبدو مستقبل اكتشاف الأجسام مشرقًا، مع وجود مجال لمزيد من التحسينات في السرعة والدقة والقدرة على التكيف.
هل أنت مهتم بالذكاء الاصطناعي؟ ابق على اتصال مع مجتمعنا لمواصلة التعلم! تحقق من مستودع GitHub الخاص بنا لاكتشاف كيف نستخدم الذكاء الاصطناعي لإنشاء حلول مبتكرة في صناعات مثل التصنيع و الرعاية الصحية. 🚀
.webp)

.webp)