


Explorando la tarjeta del modelo Claude 3: Lo que significa para la visión artificial

Descubra la ficha del modelo Claude 3 y su impacto en el desarrollo de la IA de visión.

Descubra la ficha del modelo Claude 3 y su impacto en el desarrollo de la IA de visión.
En los últimos años, la Visión Artificial ha logrado avances significativos, revolucionando varias industrias, desde la atención médica hasta el comercio minorista. Comprender los modelos subyacentes y su documentación es crucial para aprovechar estos avances de manera efectiva. Una herramienta esencial en el arsenal del desarrollador de Inteligencia Artificial (IA) es la tarjeta de modelo, que ofrece una visión general completa de las características y el rendimiento de un modelo de IA.
En este artículo exploraremos la tarjeta modelo Claude 3, desarrollada por Anthropic, y sus implicaciones para el desarrollo de Vision AI. Claude 3 es una nueva familia de grandes modelos multimodales que consta de tres variantes: Claude 3 Opus, el modelo más capaz; Claude 3 Sonnet, que equilibra rendimiento y velocidad; y Claude 3 Haiku, la opción más rápida y rentable. Todos los modelos están dotados de nuevas funciones de visión que les permiten procesar y analizar datos de imagen.
¿Qué es exactamente una "model card"? Una "model card" es un documento detallado que proporciona información sobre el desarrollo, el entrenamiento y la evaluación de un modelo de aprendizaje automático. Su objetivo es promover la transparencia, la responsabilidad y el uso ético de la IA presentando información clara sobre la funcionalidad del modelo, los casos de uso previstos y las posibles limitaciones. Esto puede lograrse proporcionando datos más detallados sobre el modelo, como sus métricas de evaluación y su comparación con modelos anteriores y otros competidores.
Las métricas de evaluación son fundamentales para valorar el rendimiento del modelo. La ficha del modelo Claude 3 enumera métricas como la precisión (accuracy), la exactitud (precision), la exhaustividad (recall) y la puntuación F1, lo que proporciona una imagen clara de los puntos fuertes del modelo y de las áreas de mejora. Estas métricas se comparan con los estándares del sector, lo que demuestra el rendimiento competitivo de Claude 3.
Además, Claude 3 se basa en los puntos fuertes de sus predecesores, incorporando avances en la arquitectura y las técnicas de entrenamiento. La ficha del modelo compara Claude 3 con versiones anteriores, destacando las mejoras en precisión, eficiencia y aplicabilidad a nuevos casos de uso.
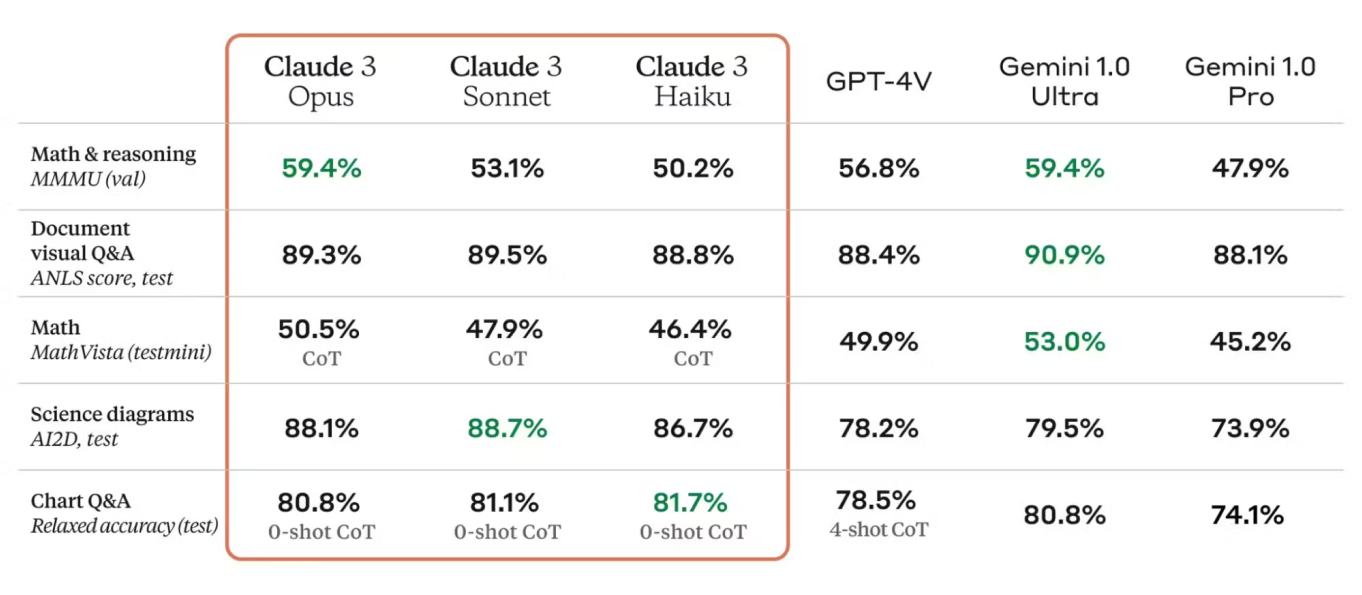
La arquitectura y el proceso de entrenamiento de Claude 3 dan como resultado un rendimiento fiable en diversas tareas de procesamiento del lenguaje natural (PNL) y visuales. Consistentemente logra resultados sólidos en los puntos de referencia, lo que demuestra su capacidad para realizar análisis de lenguaje complejos de manera efectiva.
El entrenamiento de Claude 3 en diversos conjuntos de datos y el uso de técnicas de aumento de datos garantizan su solidez y capacidad para generalizar en diferentes escenarios. Esto hace que el modelo sea versátil y eficaz en una amplia gama de aplicaciones.
Aunque sus resultados son dignos de mención, Claude 3 es fundamentalmente un Large Language Model (LLM). Aunque los LLM como Claude 3 pueden realizar varias tareas de visión por ordenador, no se diseñaron específicamente para tareas como la detección de objetos, la creación de recuadros delimitadores y la segmentación de imágenes. Por ello, su precisión en estas áreas puede no igualar la de los modelos creados específicamente para la visión por ordenador, como Ultralytics YOLOv8. No obstante, los LLM sobresalen en otros ámbitos, sobre todo en el Procesamiento del Lenguaje Natural (PLN), donde Claude 3 demuestra una fuerza significativa al fusionar tareas visuales sencillas con el razonamiento humano.

Las capacidades de PNL se refieren a la capacidad de un modelo de IA para comprender y responder al lenguaje humano. Esta capacidad se aprovecha enormemente en las aplicaciones de Claude 3 dentro del campo visual, lo que le permite proporcionar descripciones contextualmente ricas, interpretar datos visuales complejos y mejorar el rendimiento general en las tareas de Vision AI.
Una de las capacidades más impresionantes de Claude 3, especialmente cuando se aprovecha para tareas de Vision AI, es su capacidad para procesar y convertir imágenes de baja calidad con escritura a mano difícil de leer en texto. Esta característica muestra el poder de procesamiento avanzado del modelo y sus capacidades de razonamiento multimodal. En esta sección, exploraremos cómo Claude 3 lleva a cabo esta tarea, destacando los mecanismos subyacentes y las implicaciones para el desarrollo de Vision AI.
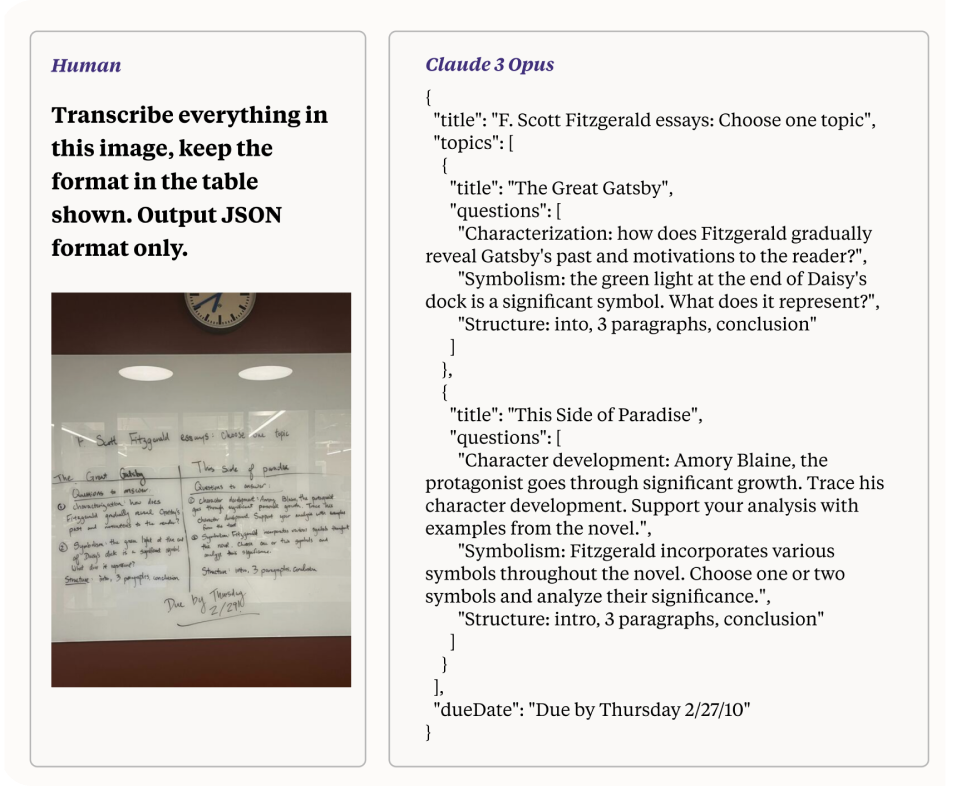
Convertir una foto de baja calidad con escritura a mano difícil de leer en texto es una tarea compleja que implica varios desafíos:
Como se mencionó anteriormente, los modelos Claude 3 abordan estos desafíos a través de una combinación de técnicas avanzadas en visión artificial y procesamiento del lenguaje natural (PNL).
La arquitectura de Claude 3 le permite realizar tareas de razonamiento complejas utilizando entradas visuales. Por ejemplo, como se muestra en la Figura 1, el modelo puede interpretar gráficos y diagramas, como identificar países del G7 en un gráfico sobre el uso de Internet, extraer datos relevantes y realizar cálculos para analizar tendencias. Este razonamiento de varios pasos, como calcular las diferencias estadísticas en el uso de Internet entre grupos de edad, mejora la precisión y la utilidad del modelo en aplicaciones del mundo real.

Claude 3 sobresale en la transformación de imágenes en descripciones detalladas, mostrando sus potentes capacidades tanto en visión artificial como en procesamiento del lenguaje natural. Cuando se le da una imagen, Claude 3 primero emplea redes neuronales convolucionales (CNN) para extraer características clave e identificar objetos, patrones y elementos contextuales dentro de los datos visuales.
A continuación, las capas Transformer analizan estas características, aprovechando los mecanismos de atención para comprender las relaciones y el contexto entre los diferentes elementos de la imagen. Este enfoque multimodal permite a Claude 3 generar descripciones precisas y contextualmente ricas, no solo identificando objetos, sino también comprendiendo sus interacciones y su significado dentro de la escena.

Los grandes modelos lingüísticos (LLM) como Claude 3 destacan en el procesamiento del lenguaje natural, no en la visión por ordenador. Aunque pueden describir imágenes, tareas como la detección de objetos y la segmentación de imágenes se realizan mejor con modelos orientados a la visión, como YOLOv8. Estos modelos especializados están optimizados para tareas visuales y ofrecen un mejor rendimiento en el análisis de imágenes. Además, el modelo no puede realizar tareas como la creación de cuadros delimitadores.
La combinación de Claude 3 con sistemas de visión artificial puede ser compleja y puede requerir pasos de procesamiento adicionales para cerrar la brecha entre el texto y los datos visuales.
Claude 3 se entrena principalmente con grandes cantidades de datos textuales, lo que significa que carece de los extensos conjuntos de datos visuales necesarios para lograr un alto rendimiento en tareas de visión artificial. Como resultado, si bien Claude 3 sobresale en la comprensión y generación de texto, no tiene la capacidad de procesar o analizar imágenes con el mismo nivel de competencia que se encuentra en los modelos diseñados específicamente para datos visuales. Esta limitación lo hace menos efectivo para aplicaciones que requieren interpretar o generar contenido visual.
Al igual que otros modelos de lenguaje grandes, Claude 3 está diseñado para una mejora continua. Las futuras mejoras probablemente se centrarán en tareas visuales más avanzadas, como la detección de imágenes y el reconocimiento de objetos, así como en los avances en las tareas de procesamiento del lenguaje natural. Esto permitirá descripciones más precisas y detalladas de objetos y escenas, entre otras tareas similares.
Por último, la investigación en curso sobre Claude 3 priorizará la mejora de la interpretabilidad, la reducción de sesgos y la mejora de la generalización en diversos conjuntos de datos. Estos esfuerzos garantizarán el sólido rendimiento del modelo en diversas aplicaciones y fomentarán la confianza y la fiabilidad en sus resultados.
La ficha del modelo Claude 3 es un recurso valioso para los desarrolladores y las partes interesadas en Vision AI, ya que proporciona información detallada sobre la arquitectura, el rendimiento y las consideraciones éticas del modelo. Al promover la transparencia y la rendición de cuentas, ayuda a garantizar el uso responsable y eficaz de las tecnologías de IA. A medida que Vision AI continúa evolucionando, el papel de las fichas de modelos como la de Claude 3 será crucial para guiar el desarrollo y fomentar la confianza en los sistemas de IA.
En Ultralytics, nos apasiona el avance de la tecnología de IA. Para explorar nuestras soluciones de IA y estar al día de nuestras últimas innovaciones, visite nuestro repositorio de GitHub. Únete a nuestra comunidad en Discord y descubre cómo estamos transformando sectores como el de los coches autónomos y la fabricación. 🚀


