



Conozca la RCNN y su impacto en la detección de objetos. Trataremos sus componentes clave, sus aplicaciones y su papel en el avance de técnicas como Fast RCNN y YOLO.

Conozca la RCNN y su impacto en la detección de objetos. Trataremos sus componentes clave, sus aplicaciones y su papel en el avance de técnicas como Fast RCNN y YOLO.
La detección de objetos es una tarea de visión por ordenador que permite reconocer y localizar objetos en imágenes o vídeos para aplicaciones como la conducción autónoma, la vigilancia y la obtención de imágenes médicas. Los primeros métodos de detección de objetos, como el detector de Viola-Jones y el histograma de gradientes orientados (HOG) con máquinas de vectores de soporte (SVM), se basaban en características elaboradas a mano y ventanas deslizantes. Estos métodos solían tener dificultades para detect con precisión objetos en escenas complejas con múltiples objetos de distintas formas y tamaños.
Las redes neuronales convolucionales basadas en regiones (R-CNN) han cambiado la forma de abordar la detección de objetos. Se trata de un hito importante en la historia de la visión por ordenador. Para entender cómo funcionan modelos como YOLOv8 necesitamos entender primero modelos como R-CNN.
Creado por Ross Girshick y su equipo, la arquitectura del modelo R-CNN genera propuestas de regiones, extrae características con una red neuronal convolucional (CNN) preentrenada, clasifica objetos y refina los cuadros delimitadores. Si bien eso puede parecer desalentador, al final de este artículo, tendrá una comprensión clara de cómo funciona R-CNN y por qué es tan impactante. ¡Echemos un vistazo!
El proceso de detección de objetos del modelo R-CNN implica tres pasos principales: generar propuestas de regiones, extraer características y clasificar objetos, a la vez que se refinan sus áreas delimitadoras. Analicemos cada paso.
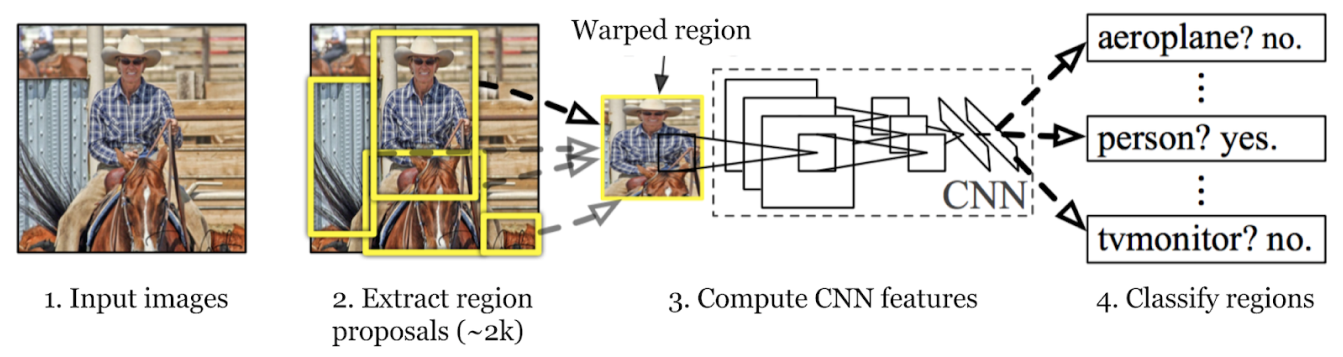
En el primer paso, el modelo R-CNN escanea la imagen para crear numerosas propuestas de regiones. Las propuestas de regiones son áreas potenciales que podrían contener objetos. Se utilizan métodos como la Búsqueda Selectiva para analizar varios aspectos de la imagen, como el color, la textura y la forma, dividiéndola en diferentes partes. La Búsqueda Selectiva comienza dividiendo la imagen en partes más pequeñas y, a continuación, fusionando las similares para formar áreas de interés más grandes. Este proceso continúa hasta que se generan unas 2.000 propuestas de regiones.
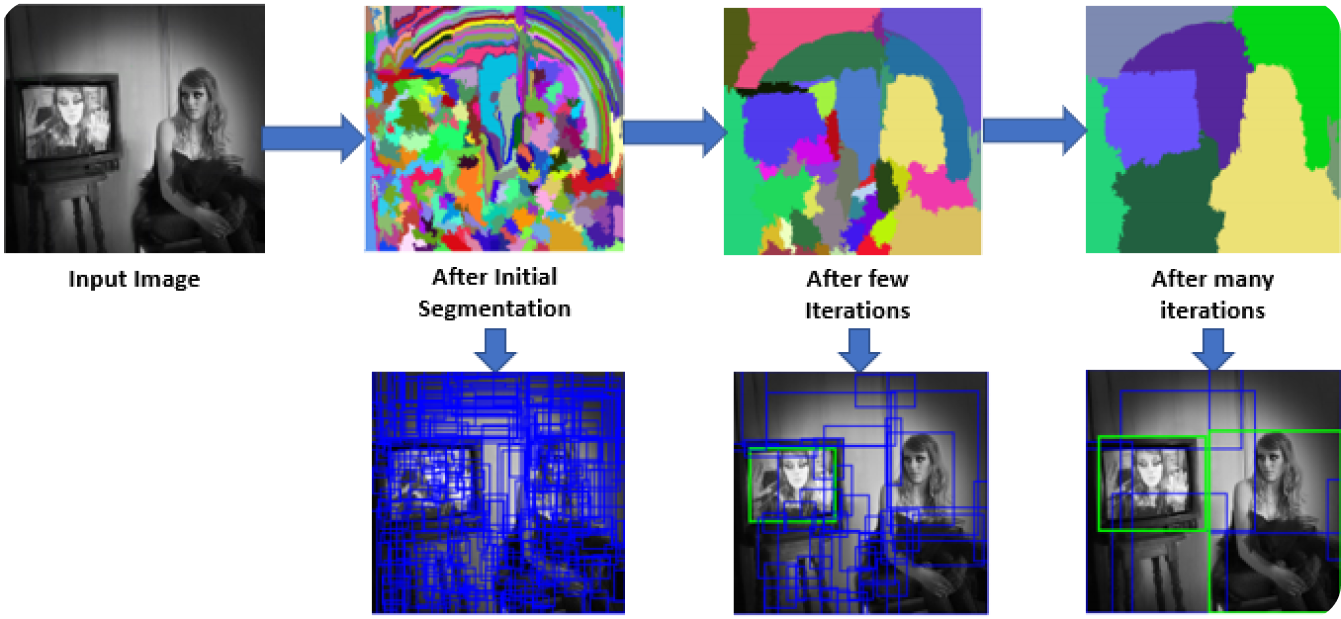
Estas propuestas de regiones ayudan a identificar todos los posibles lugares donde podría haber un objeto. En los siguientes pasos, el modelo puede procesar eficientemente las áreas más relevantes centrándose en estas áreas específicas en lugar de en toda la imagen. El uso de propuestas de regiones equilibra la minuciosidad con la eficiencia computacional.
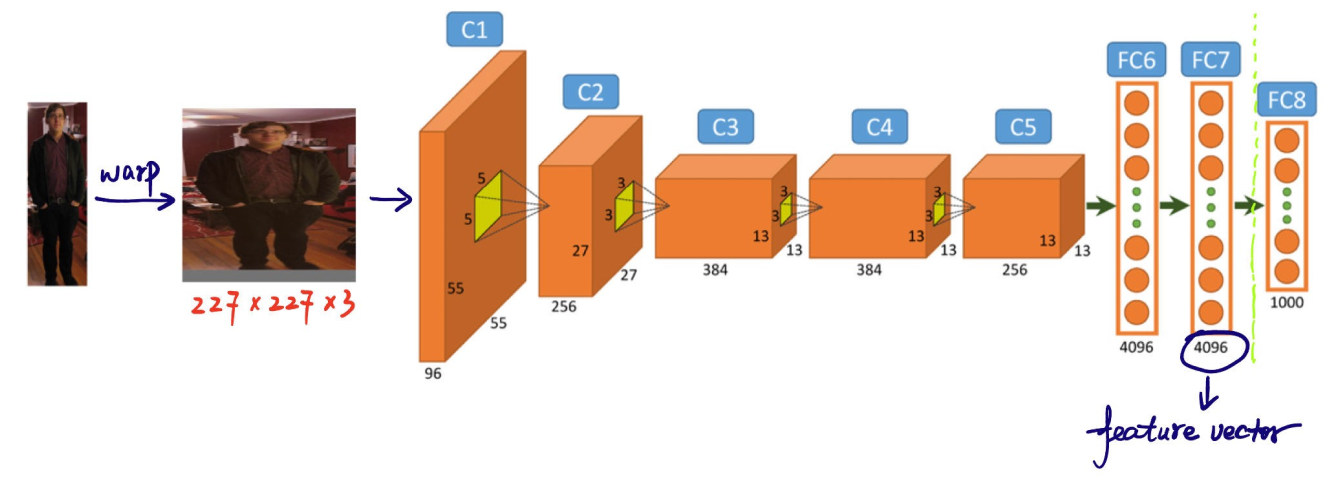
El siguiente paso en el proceso de detección de objetos del modelo R-CNN es extraer características de las propuestas de regiones. Cada propuesta de región se redimensiona a un tamaño consistente que la CNN espera (por ejemplo, 224x224 píxeles). El cambio de tamaño ayuda a la CNN a procesar cada propuesta de manera eficiente. Antes de deformar, el tamaño de cada propuesta de región se expande ligeramente para incluir 16 píxeles de contexto adicional alrededor de la región para proporcionar más información circundante para una mejor extracción de características.
Una vez redimensionadas, estas propuestas de regiones se introducen en una CNN como AlexNet, que suele estar preentrenada en un gran conjunto de datos como ImageNet. La CNN procesa cada región para extraer vectores de características de alta dimensión que capturan detalles importantes como bordes, texturas y patrones. Estos vectores condensan la información esencial de las regiones. Transforman los datos brutos de la imagen en un formato que el modelo puede utilizar para análisis posteriores. La precisión en la clasificación y localización de objetos en las etapas siguientes depende de esta conversión crucial de la información visual en datos significativos.
El tercer paso consiste en classify los objetos dentro de estas regiones. Esto significa determinar la categoría o clase de cada objeto encontrado dentro de las propuestas. A continuación, los vectores de características extraídos se pasan por un clasificador de aprendizaje automático.
En el caso de R-CNN, las Máquinas de Vectores de Soporte (SVM) se utilizan comúnmente para este propósito. Cada SVM está entrenada para reconocer una clase de objeto específica analizando los vectores de características y decidiendo si una región en particular contiene una instancia de esa clase. Esencialmente, para cada categoría de objeto, hay un clasificador dedicado que comprueba cada propuesta de región para ese objeto específico.
Durante el entrenamiento, los clasificadores reciben datos etiquetados con muestras positivas y negativas:
Los clasificadores aprenden a distinguir entre estas muestras. La regresión del área delimitadora refina aún más la posición y el tamaño de los objetos detectados ajustando las áreas delimitadoras propuestas inicialmente para que coincidan mejor con los límites reales del objeto. El modelo R-CNN puede identificar y localizar con precisión los objetos combinando la clasificación y la regresión del área delimitadora.
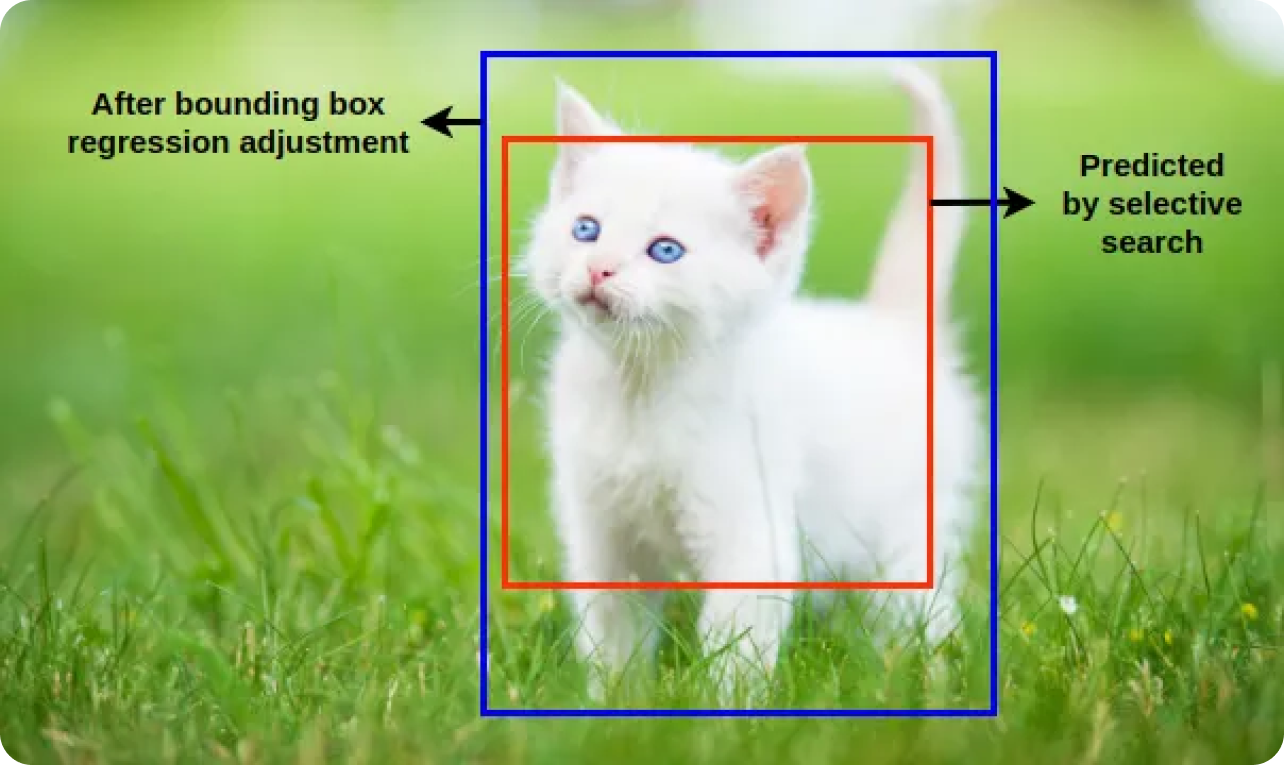
Tras los pasos de clasificación y regresión de recuadros delimitadores, el modelo genera a menudo múltiples recuadros delimitadores superpuestos para el mismo objeto. Se aplica la supresión no máximaNMS) para refinar estas detecciones, manteniendo los recuadros más precisos. El modelo elimina los recuadros redundantes y superpuestos aplicando NMS y conserva sólo las detecciones más seguras.
NMS funciona evaluando las puntuaciones de confianza (que indican la probabilidad de que un objeto detectado esté realmente presente) de todos los recuadros delimitadores y suprimiendo aquellos que se solapan significativamente con recuadros de mayor puntuación.

Aquí tienes un desglose de los pasos de NMS:
En resumen, el modelo R-CNN detecta objetos generando propuestas de regiones, extrayendo características con una CNN, clasificando objetos y refinando sus posiciones con regresión de caja delimitadora, y utilizando Supresión No MáximaNMS) manteniendo sólo las detecciones más precisas.
R-CNN es un modelo histórico en la historia de la detección de objetos porque introdujo un nuevo enfoque que mejoró enormemente la precisión y el rendimiento. Antes de R-CNN, los modelos de detección de objetos tenían dificultades para equilibrar la velocidad y la precisión. El método de R-CNN de generar propuestas de región y utilizar CNN para la extracción de características permite una localización e identificación precisas de los objetos dentro de las imágenes.
R-CNN allanó el camino para modelos como Fast R-CNN, Faster R-CNN y Mask R-CNN, que mejoraron aún más la eficiencia y la precisión. Al combinar el aprendizaje profundo con el análisis basado en regiones, R-CNN estableció un nuevo estándar en el campo y abrió posibilidades para diversas aplicaciones del mundo real.
Un caso interesante de uso de R-CNN es el de las imágenes médicas. Los modelos R-CNN se han utilizado para detect y classify distintos tipos de tumores, como los cerebrales, en exploraciones médicas como resonancias magnéticas y tomografías computarizadas. El uso del modelo R-CNN en imágenes médicas mejora la precisión del diagnóstico y ayuda a los radiólogos a identificar tumores malignos en una fase temprana. La capacidad de R-CNN para detect incluso tumores pequeños y en estadios tempranos puede suponer una diferencia significativa en el tratamiento y el pronóstico de enfermedades como el cáncer.
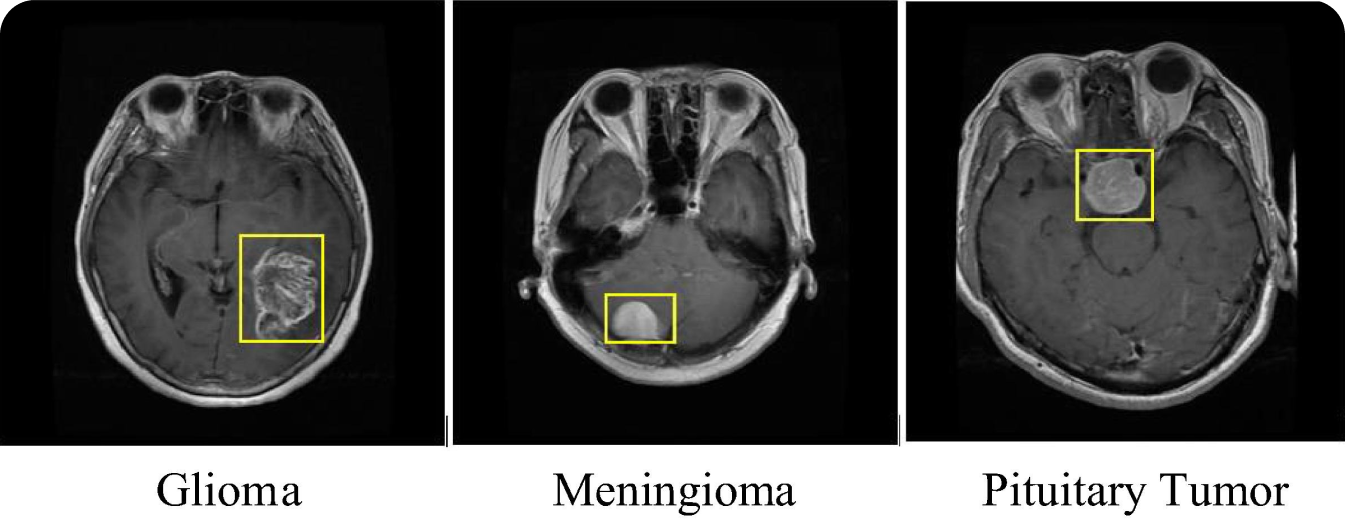
El modelo R-CNN puede aplicarse a otras tareas de imagen médica además de la detección de tumores. Por ejemplo, puede identificar fracturas, detect enfermedades de la retina en exploraciones oculares y analizar imágenes pulmonares para detectar afecciones como neumonía y COVID-19. Sea cual sea el problema médico, la detección precoz puede mejorar la evolución de los pacientes. Aplicando la precisión de R-CNN en la identificación y localización de anomalías, los profesionales sanitarios pueden mejorar la fiabilidad y rapidez de los diagnósticos médicos. Con la detección de objetos que agiliza el proceso de diagnóstico, los pacientes pueden beneficiarse de planes de tratamiento oportunos y precisos.
Aunque impresionante, R-CNN tiene ciertos inconvenientes, como una alta complejidad computacional y tiempos de inferencia lentos. Estos inconvenientes hacen que el modelo R-CNN no sea adecuado para aplicaciones en tiempo real. La separación de las propuestas de región y las clasificaciones en pasos distintos puede conducir a un rendimiento menos eficiente.
Con el paso de los años, han surgido varios modelos de detección de objetos que han abordado estas preocupaciones. Fast R-CNN combina las propuestas de región y la extracción de características de CNN en un solo paso, lo que acelera el proceso. Faster R-CNN introduce una Red de Propuesta de Regiones (RPN) para agilizar la generación de propuestas, mientras que Mask R-CNN añade la segmentación a nivel de píxel para detecciones más detalladas.

Más o menos al mismo tiempo que Faster R-CNN, la serie YOLO (You Only Look Once) empezó a avanzar en la detección de objetos en tiempo real. Los modelos YOLO predicen los recuadros delimitadores y las probabilidades de clase en una sola pasada por la red. Por ejemplo, el modelo Ultralytics YOLOv8 ofrece mayor precisión y velocidad con funciones avanzadas para muchas tareas de visión por ordenador.
RCNN cambió las reglas del juego de la visión por ordenador, mostrando cómo el aprendizaje profundo puede cambiar la detección de objetos. Su éxito inspiró muchas ideas nuevas en este campo. Aunque han surgido nuevos modelos como Faster R-CNN y YOLO para corregir los defectos de RCNN, su contribución es un hito enorme que es importante recordar.
A medida que la investigación continúa, veremos modelos de detección de objetos aún mejores y más rápidos. Estos avances no solo mejorarán la forma en que las máquinas entienden el mundo, sino que también conducirán al progreso en muchas industrias. ¡El futuro de la detección de objetos parece emocionante!
¿Quieres seguir explorando sobre IA? ¡Forme parte de lacomunidad Ultralytics ! Explore nuestro repositorio GitHub para ver nuestras últimas innovaciones en inteligencia artificial. Echa un vistazo a nuestras soluciones de IA que abarcan varios sectores como la agricultura y la fabricación. ¡Únase a nosotros para aprender y avanzar!


