


PaliGemma 2 di Google: approfondimenti sui modelli VLM avanzati

Scoprite insieme a noi i nuovi modelli linguistici di visione di Google: PaliGemma 2. Questi modelli possono aiutare nella comprensione e nell'analisi di immagini e testi.

Scoprite insieme a noi i nuovi modelli linguistici di visione di Google: PaliGemma 2. Questi modelli possono aiutare nella comprensione e nell'analisi di immagini e testi.
Il 5 dicembre 2024 Google ha presentato PaliGemma 2, l'ultima versione del suo modello di linguaggio visivo (VLM) all'avanguardia. PaliGemma 2 è stato progettato per gestire compiti che combinano immagini e testo, come la generazione di didascalie, la risposta a domande visive e il rilevamento di oggetti nelle immagini.
Basandosi sull'originale PaliGemma, che era già un potente strumento per la sottotitolazione multilingue e il riconoscimento degli oggetti, PaliGemma 2 offre diversi miglioramenti chiave. Questi includono dimensioni del modello maggiori, supporto per immagini a risoluzione più elevata e prestazioni migliori su attività visive complesse. Questi aggiornamenti lo rendono ancora più flessibile ed efficace per una vasta gamma di utilizzi.
In questo articolo, esamineremo più da vicino PaliGemma 2, incluso come funziona, le sue caratteristiche principali e le applicazioni in cui eccelle. Iniziamo!
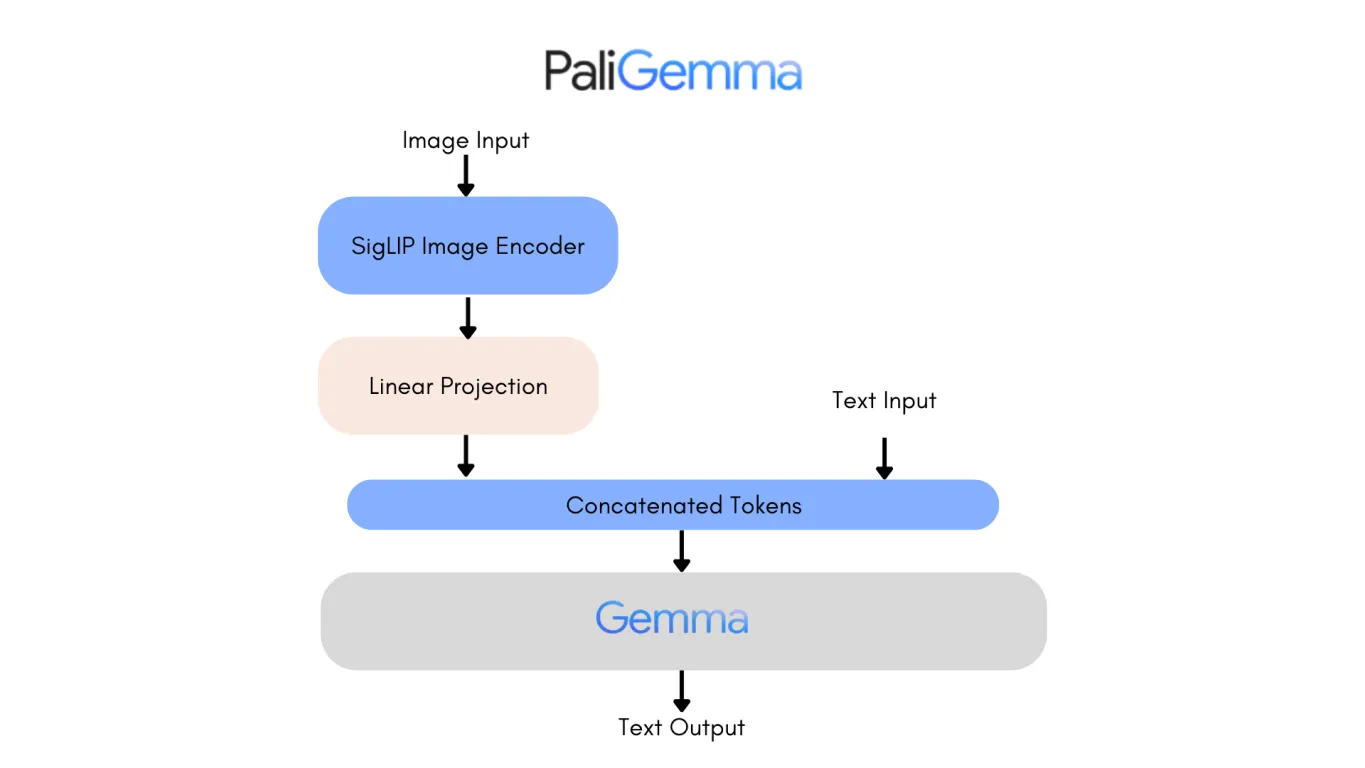
PaliGemma 2 è costruito su due tecnologie chiave: il codificatore di visione SigLIP e il modello linguistico Gemma 2. Il codificatore SigLIP elabora i dati visivi, come immagini o video, e li suddivide in funzionalità che il modello può analizzare. Nel frattempo, Gemma 2 gestisce il testo, consentendo al modello di comprendere e generare linguaggio multilingue. Insieme, formano un VLM, progettato per interpretare e connettere informazioni visive e testuali senza problemi.
Ciò che rende PaliGemma 2 un importante passo avanti sono la sua scalabilità e versatilità. A differenza della versione originale, PaliGemma 2 è disponibile in tre dimensioni: 3 miliardi (3B), 10 miliardi (10B) e 28 miliardi (28B) di parametri. Questi parametri sono come le impostazioni interne del modello, che lo aiutano ad apprendere ed elaborare i dati in modo efficace. Supporta anche diverse risoluzioni di immagine (ad esempio, 224 x 224 pixel per attività rapide e 896 x 896 per analisi dettagliate), rendendolo adattabile a varie applicazioni.
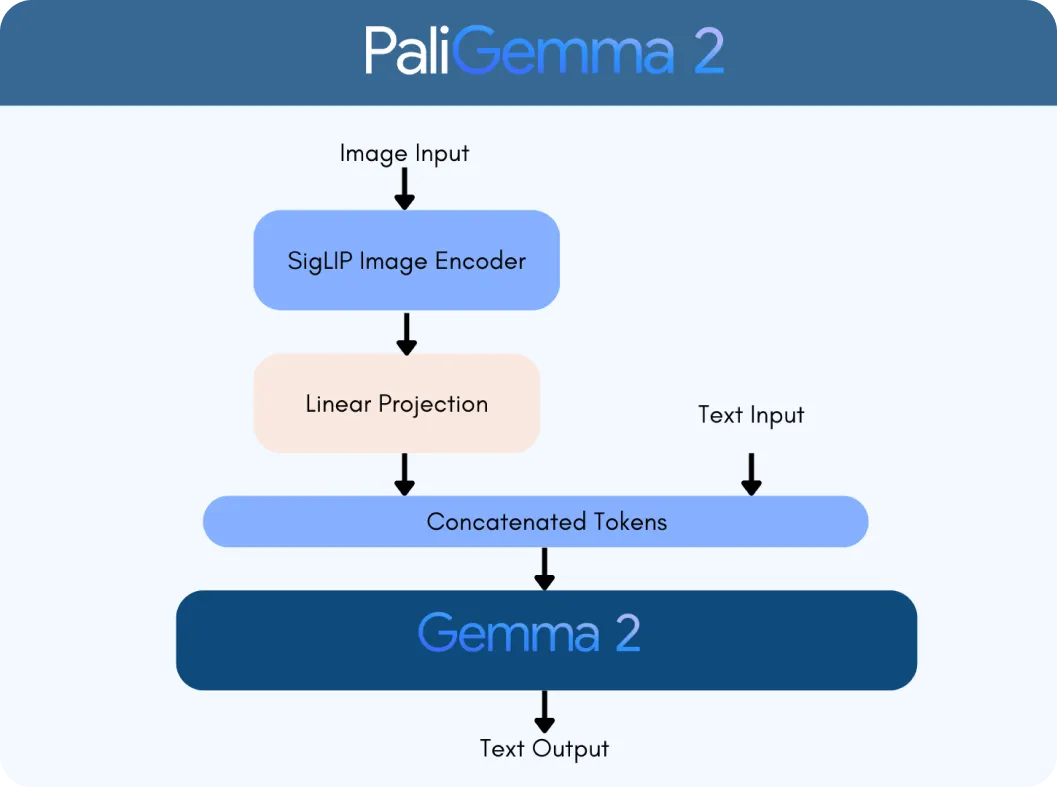
L'integrazione delle funzionalità avanzate di linguaggio di Gemma 2 con l'elaborazione delle immagini di SigLIP rende PaliGemma 2 significativamente più intelligente. Può gestire attività come:
PaliGemma 2 va oltre l'elaborazione separata di immagini e testo: li unisce in modi significativi. Ad esempio, può comprendere le relazioni in una scena, come riconoscere che "Il gatto è seduto sul tavolo", o identificare oggetti aggiungendo contesto, come riconoscere un famoso punto di riferimento.
Successivamente, esamineremo un esempio utilizzando il grafico mostrato nell'immagine sottostante per comprendere meglio come PaliGemma 2 elabora i dati visivi e testuali. Supponiamo di caricare questo grafico e di chiedere al modello: "Cosa rappresenta questo grafico?"

Il processo inizia con il codificatore di visione SigLIP di PaliGemma 2 per analizzare le immagini ed estrarre le caratteristiche chiave. Nel caso di un grafico, questo include l'identificazione di elementi come assi, punti dati ed etichette. Il codificatore è addestrato a catturare sia modelli ampi che dettagli fini. Utilizza anche il riconoscimento ottico dei caratteri (OCR) per detect ed elaborare qualsiasi testo incorporato nell'immagine. Queste caratteristiche visive vengono convertite in token, rappresentazioni numeriche che il modello può elaborare. Questi token vengono poi regolati con un livello di proiezione lineare, una tecnica che garantisce la possibilità di combinarli senza problemi con i dati testuali.
Allo stesso tempo, il modello linguistico Gemma 2 elabora la query di accompagnamento per determinarne il significato e l'intento. Il testo della query viene convertito in token, e questi vengono combinati con i token visivi di SigLIP per creare una rappresentazione multimodale, un formato unificato che collega dati visivi e testuali.
Utilizzando questa rappresentazione integrata, PaliGemma 2 genera una risposta passo dopo passo attraverso la decodifica autoregressiva, un metodo in cui il modello prevede una parte della risposta alla volta in base al contesto che ha già elaborato.
Ora che abbiamo capito come funziona, esploriamo le caratteristiche principali che rendono PaliGemma 2 un modello di visione-linguaggio affidabile:
Analizzare l'architettura della prima versione di PaliGemma è un buon modo per vedere i miglioramenti di PaliGemma 2. Uno dei cambiamenti più notevoli è la sostituzione del modello linguistico Gemma originale con Gemma 2, che apporta notevoli miglioramenti sia in termini di prestazioni che di efficienza.
Gemma 2, disponibile nelle dimensioni di 9B e 27B parametri, è stato progettato per offrire accuratezza e velocità ai vertici della categoria, riducendo al contempo i costi di implementazione. Raggiunge questo obiettivo attraverso un'architettura riprogettata e ottimizzata per l'efficienza dell'inferenza su varie configurazioni hardware, dalle potenti GPU a configurazioni più accessibili.
Di conseguenza, PaliGemma 2 è un modello altamente accurato. La versione 10B di PaliGemma 2 raggiunge un punteggio NES (Non-Entailment Sentence) inferiore, pari a 20,3, rispetto al 34,3 del modello originale, il che significa meno errori fattuali nei suoi output. Questi progressi rendono PaliGemma 2 più scalabile, preciso e adattabile a una gamma più ampia di applicazioni, dalla didascalia dettagliata alla risposta a domande visive.
PaliGemma 2 ha il potenziale per ridefinire i settori combinando perfettamente la comprensione visiva e linguistica. Ad esempio, per quanto riguarda l'accessibilità, può generare descrizioni dettagliate di oggetti, scene e relazioni spaziali, fornendo un'assistenza fondamentale alle persone con problemi di vista. Questa capacità aiuta gli utenti a comprendere meglio il loro ambiente, offrendo maggiore indipendenza quando si tratta di attività quotidiane.

Oltre all'accessibilità, PaliGemma 2 sta avendo un impatto in vari settori, tra cui:
Per provare PaliGemma 2, potete iniziare con la demo interattiva di Hugging Face. Essa consente di esplorare le sue capacità in compiti come la didascalia delle immagini e la risposta a domande visive. È sufficiente caricare un'immagine e porre al modello domande su di essa o richiedere una descrizione della scena.
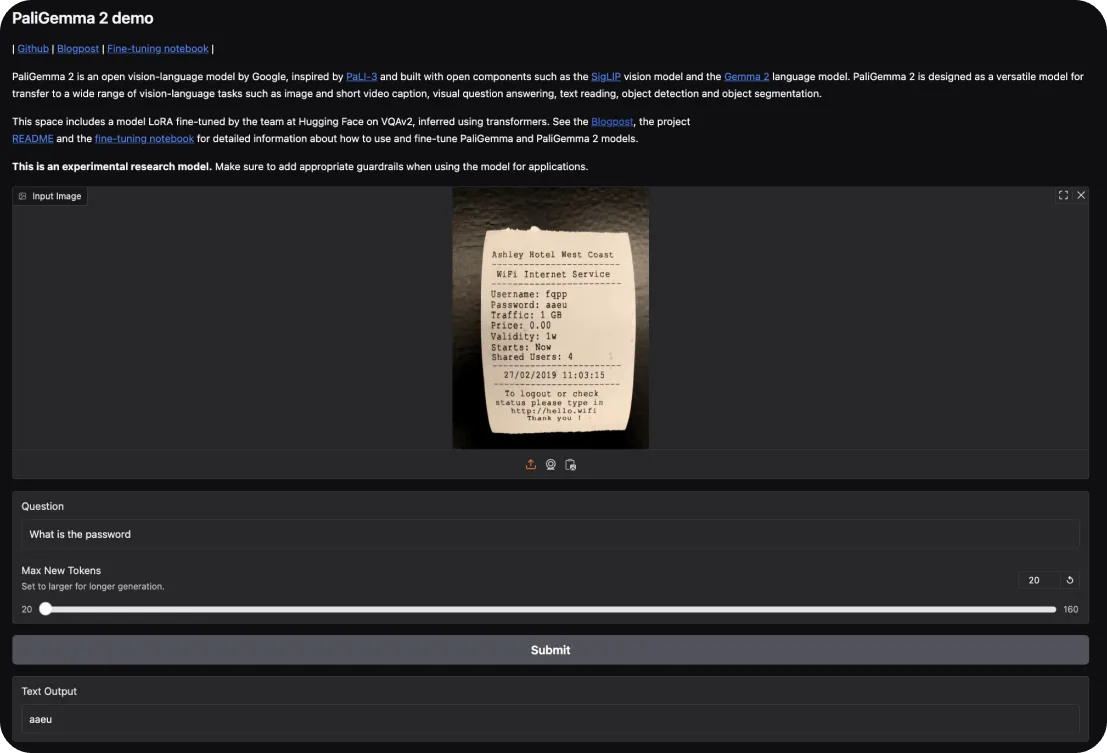
Se desideri approfondire, ecco come puoi mettere in pratica:
Dopo aver capito come iniziare con PaliGemma 2, diamo un'occhiata più da vicino ai suoi principali punti di forza e debolezze da tenere a mente quando si utilizzano questi modelli.
Ecco cosa distingue PaliGemma 2 come modello di visione-linguaggio:
Nel frattempo, ecco alcune aree in cui PaliGemma 2 potrebbe incontrare delle limitazioni:
PaliGemma 2 è un affascinante progresso nella modellazione visione-linguaggio, che offre scalabilità, flessibilità di fine-tuning e accuratezza migliorate. Può servire come strumento prezioso per applicazioni che vanno dalle soluzioni di accessibilità e l'e-commerce alla diagnostica sanitaria e l'istruzione.
Sebbene presenti dei limiti, come i requisiti computazionali e la dipendenza da dati di alta qualità, i suoi punti di forza la rendono una scelta pratica per affrontare compiti complessi che integrano dati visivi e testuali. PaliGemma 2 può fornire una solida base per ricercatori e sviluppatori per esplorare ed espandere il potenziale dell'IA nelle applicazioni multimodali.
Partecipa alla conversazione sull'AI consultando il nostro repository GitHub e la community. Scopri come l'AI sta facendo progressi in agricoltura e sanità! 🚀


