


Tipi di tecniche di apprendimento AI utilizzate nella computer vision

Esplora i diversi tipi di tecniche di machine learning e deep learning utilizzate nelle applicazioni di computer vision, dall'apprendimento supervisionato al transfer learning.

Esplora i diversi tipi di tecniche di machine learning e deep learning utilizzate nelle applicazioni di computer vision, dall'apprendimento supervisionato al transfer learning.
Il machine learning è un tipo di intelligenza artificiale (IA) che aiuta i computer a imparare dai dati in modo che possano prendere decisioni da soli, senza bisogno di una programmazione dettagliata per ogni attività. Implica la creazione di modelli algoritmici in grado di identificare schemi nei dati. Identificando schemi nei dati e imparando da essi, questi algoritmi possono gradualmente migliorare le loro prestazioni nel tempo.
Un'area in cui l 'apprendimento automatico svolge un ruolo cruciale è la computer vision, un campo dell'IA che si concentra sui dati visivi. La computer vision utilizza l'apprendimento automatico per aiutare i computer a detect e riconoscere i modelli nelle immagini e nei video. Grazie ai progressi dell'apprendimento automatico, si stima che il valore del mercato globale della computer vision sarà di circa 175,72 miliardi di dollari entro il 2032.
In questo articolo, esamineremo i diversi tipi di machine learning utilizzati nella computer vision, tra cui l'apprendimento supervisionato, non supervisionato, per rinforzo e transfer learning, e come ciascuno di essi svolga un ruolo in diverse applicazioni. Iniziamo!
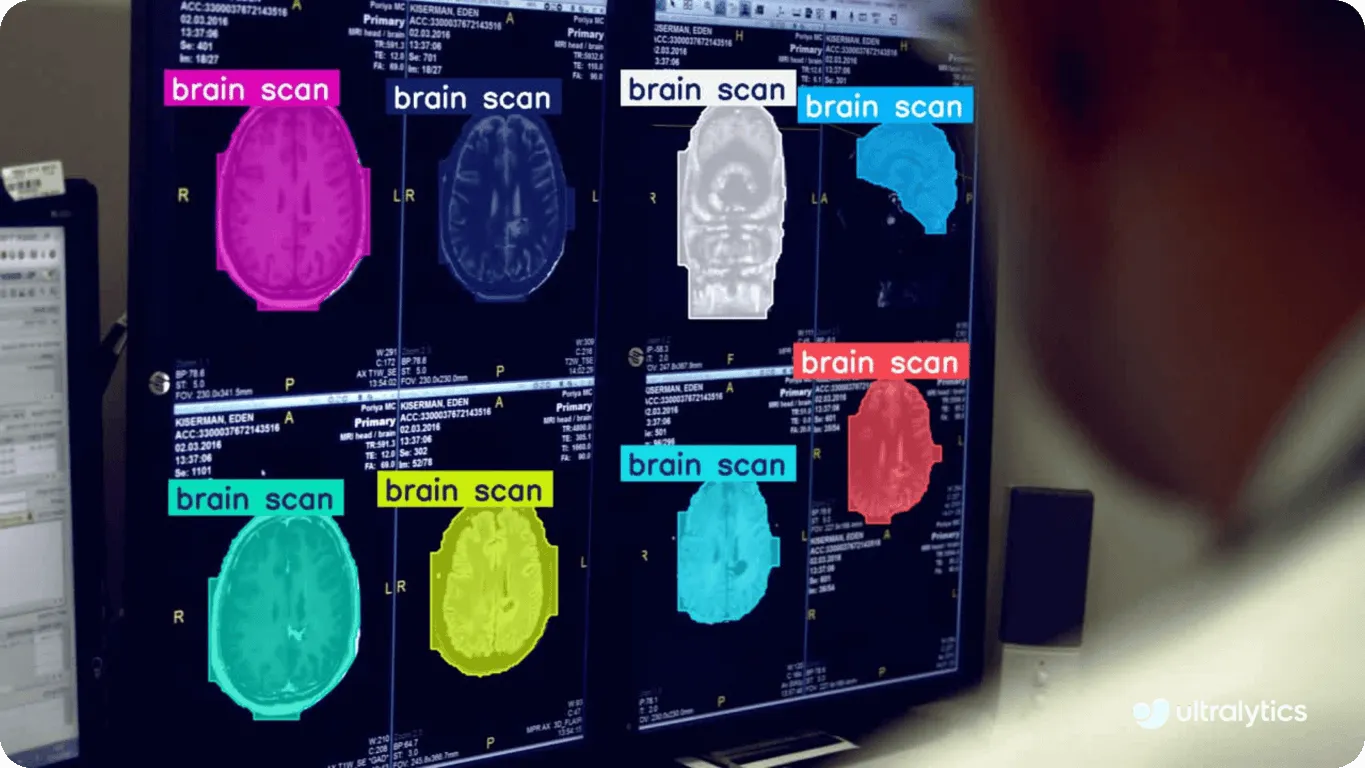
La computer vision si basa sull'apprendimento automatico, in particolare su tecniche come l'apprendimento profondo e le reti neurali, per interpretare e analizzare le informazioni visive. Questi metodi consentono ai computer di eseguire attività di computer vision come il rilevamento di oggetti nelle immagini, la classificazione delle immagini per categoria e il riconoscimento dei volti. L'apprendimento automatico è essenziale anche per le applicazioni di computer vision in tempo reale, come il controllo qualità nella produzione e l'imaging medico nella sanità. In questi casi, le reti neurali aiutano i computer a interpretare dati visivi complessi, come l'analisi delle scansioni cerebrali per detect tumori.
Infatti, molti modelli avanzati di visione computerizzata, come ad es. Ultralytics YOLO11sono basati su reti neurali.
Esistono diversi tipi di metodi di apprendimento nel machine learning, come l'apprendimento supervisionato, l'apprendimento non supervisionato, il transfer learning e il reinforcement learning, che stanno spingendo i confini di ciò che è possibile nella computer vision. Nelle sezioni seguenti, esploreremo ciascuno di questi tipi per capire come contribuiscono alla computer vision.
L'apprendimento supervisionato è il tipo di machine learning più comunemente utilizzato. Nell'apprendimento supervisionato, i modelli vengono addestrati utilizzando dati etichettati. Ogni input è contrassegnato con l'output corretto, il che aiuta il modello a imparare. Simile a uno studente che impara da un insegnante, questi dati etichettati fungono da guida o supervisore.
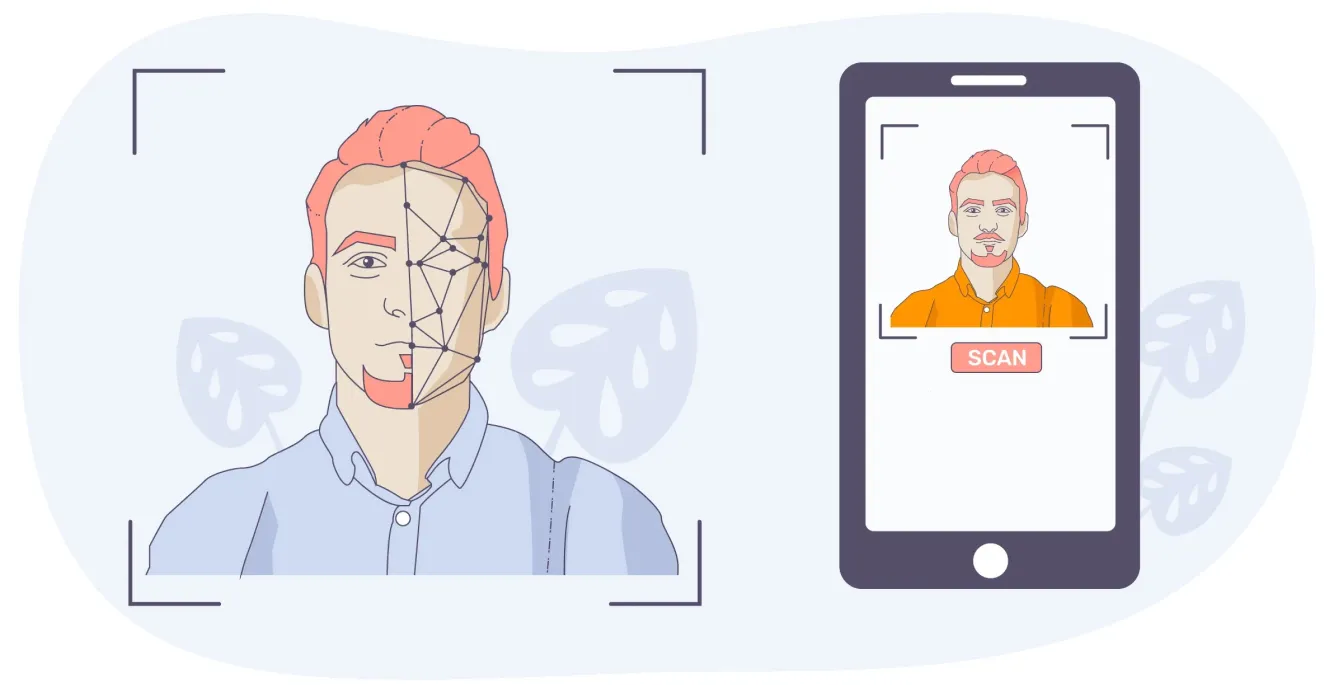
Durante l'addestramento, al modello vengono forniti sia i dati di input (le informazioni che deve elaborare) sia i dati di output (le risposte corrette). Questa impostazione aiuta il modello a imparare la connessione tra input e output. L'obiettivo principale dell'apprendimento supervisionato è che il modello scopra una regola o un modello che colleghi accuratamente ogni input al suo output corretto. Con questa mappatura, il modello può fare previsioni accurate quando incontra nuovi dati. Ad esempio, il riconoscimento facciale nella computer vision si basa sull'apprendimento supervisionato per identificare i volti in base a questi modelli appresi.
Un uso comune di questo è lo sblocco del tuo smartphone con il riconoscimento facciale. Il modello viene addestrato su immagini etichettate del tuo viso in modo che, quando vai a sbloccare il telefono, confronti l'immagine dal vivo con ciò che ha imparato. Se rileva una corrispondenza, il telefono si sblocca.
L'apprendimento non supervisionato è un tipo di apprendimento automatico che utilizza dati non etichettati: al modello non viene fornita alcuna guida o risposta corretta durante l'addestramento. Invece, impara a scoprire modelli e informazioni da solo.
L'apprendimento non supervisionato identifica i modelli utilizzando tre metodi principali:
Un'applicazione chiave dell'apprendimento non supervisionato è la compressione delle immagini, dove tecniche come il clustering k-means riducono le dimensioni dell'immagine senza influire sulla qualità visiva. I pixel vengono raggruppati in cluster e ogni cluster è rappresentato da un colore medio, risultando in un'immagine con meno colori e una dimensione del file inferiore.

Tuttavia, l'apprendimento non supervisionato presenta alcune limitazioni. Senza risposte predefinite, può avere difficoltà con l'accuratezza e la valutazione delle prestazioni. Spesso richiede uno sforzo manuale per interpretare i risultati ed etichettare i gruppi, ed è sensibile a problemi come valori mancanti e rumore, che possono influire sulla qualità dei risultati.
A differenza dell'apprendimento supervisionato e non supervisionato, l'apprendimento per rinforzo non si basa sui dati di training. Invece, utilizza agenti di rete neurale per interagire con un ambiente al fine di raggiungere un obiettivo specifico.
Il processo prevede tre componenti principali:
Quando l'agente intraprende delle azioni, influisce sull'ambiente, che a sua volta risponde con un feedback. Questo feedback aiuta l'agente a valutare le proprie scelte e ad adeguare il proprio comportamento. Il segnale di ricompensa aiuta l'agente a capire quali azioni lo avvicinano al raggiungimento del suo obiettivo.
L'apprendimento per rinforzo è fondamentale per casi d'uso come la guida autonoma e la robotica. Nella guida autonoma, compiti come il controllo del veicolo, il rilevamento e l'evitamento degli oggetti vengono appresi in base al feedback. I modelli vengono addestrati utilizzando agenti di rete neurale per detect pedoni o altri oggetti e intraprendere azioni appropriate per evitare collisioni. Analogamente, nella robotica, l'apprendimento per rinforzo consente di svolgere compiti come la manipolazione di oggetti e il controllo dei movimenti.
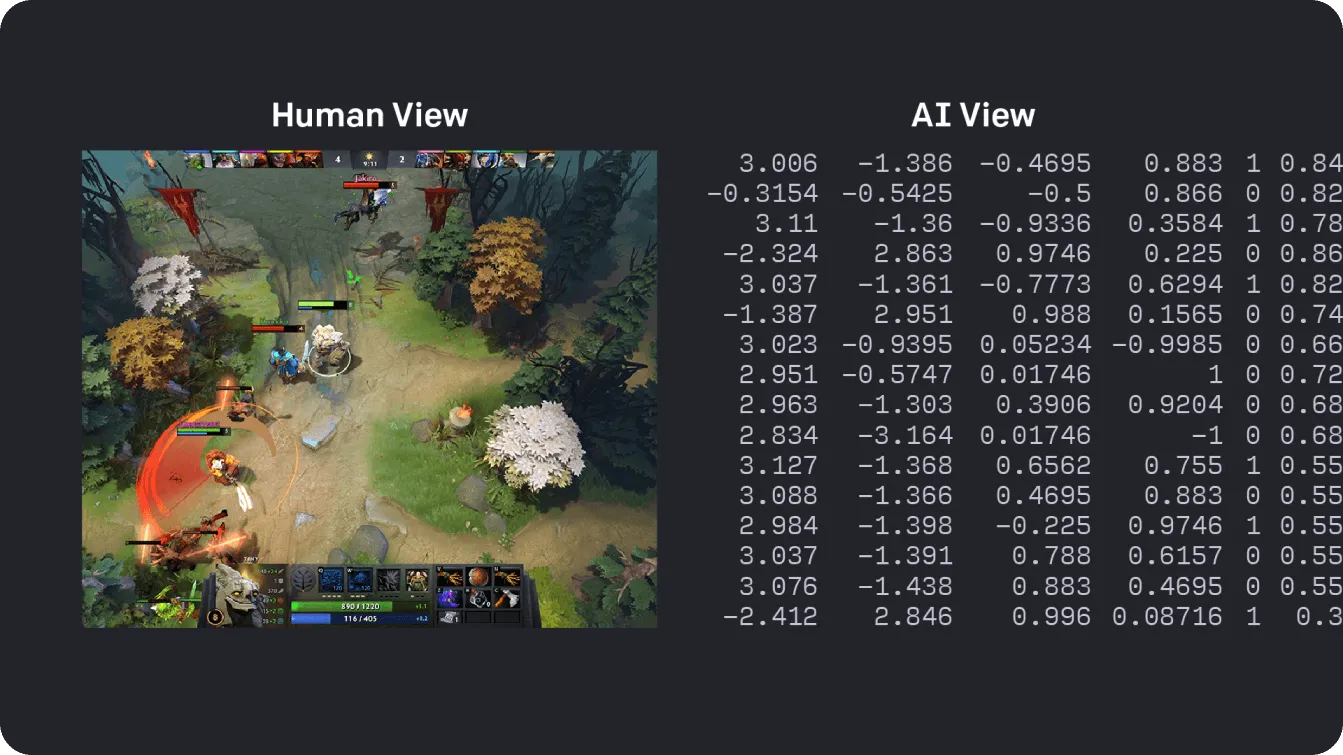
Un ottimo esempio di apprendimento per rinforzo in azione è un progetto di OpenAI, in cui i ricercatori hanno addestrato agenti di IA a giocare al popolare videogioco multiplayer, Dota 2. Utilizzando reti neurali, questi agenti hanno elaborato enormi quantità di informazioni dall'ambiente di gioco per prendere decisioni rapide e strategiche. Attraverso un feedback continuo, gli agenti hanno imparato e migliorato nel tempo, raggiungendo alla fine un livello di abilità sufficientemente alto da battere alcuni dei migliori giocatori del gioco.
Il transfer learning è diverso dagli altri tipi di apprendimento. Invece di addestrare un modello da zero, utilizza un modello pre-addestrato su un grande dataset e lo mette a punto per un compito nuovo, ma correlato. Le conoscenze acquisite durante l'addestramento iniziale vengono utilizzate per migliorare le prestazioni del nuovo compito. Il transfer learning riduce il tempo necessario per l'addestramento per un nuovo compito, a seconda della sua complessità. Funziona mantenendo i livelli iniziali del modello che catturano le caratteristiche generali e sostituendo i livelli finali con quelli del nuovo compito specifico.
Il trasferimento di stile artistico è un'applicazione interessante del transfer learning nella computer vision. Questa tecnica consente a un modello di trasformare un'immagine per adattarla allo stile di diverse opere d'arte. Per raggiungere questo obiettivo, una rete neurale viene prima addestrata su un ampio set di dati di immagini abbinate ai loro stili artistici. Attraverso questo processo, il modello impara a identificare le caratteristiche generali dell'immagine e i modelli di stile.
Una volta che il modello è stato addestrato, può essere messo a punto per applicare lo stile di un determinato dipinto a una nuova immagine. La rete si adatta alla nuova immagine preservando le caratteristiche stilistiche apprese, consentendole di creare un risultato unico che combina il contenuto originale con lo stile artistico selezionato. Ad esempio, si potrebbe scattare una foto di una catena montuosa e applicare lo stile de L'urlo di Edvard Munch, ottenendo un'immagine che cattura la scena ma con lo stile audace ed espressivo del dipinto.

Ora che abbiamo trattato i principali tipi di machine learning, diamo un'occhiata più da vicino a ciascuno per aiutarti a capire la soluzione migliore per le diverse applicazioni.

La scelta del tipo di machine learning più adatto dipende da diversi fattori. L'apprendimento supervisionato funziona bene se si dispone di dati etichettati abbondanti e di un compito ben definito. L'apprendimento non supervisionato è utile per l'esplorazione dei dati o quando gli esempi etichettati sono scarsi. L'apprendimento per rinforzo è ideale per compiti complessi che richiedono un processo decisionale passo dopo passo, mentre il transfer learning è ottimo quando i dati sono limitati o le risorse sono vincolate. Considerando questi fattori, è possibile selezionare l'approccio più adatto per il tuo progetto di computer vision.
Le tecniche di machine learning possono affrontare una varietà di sfide, specialmente in aree come la computer vision. Comprendendo i diversi tipi, supervised, unsupervised, reinforcement e transfer learning, puoi scegliere l'approccio migliore per le tue esigenze.
L'apprendimento supervisionato è ideale per attività che richiedono elevata accuratezza e dati etichettati, mentre l'apprendimento non supervisionato è perfetto per trovare modelli in dati non etichettati. L'apprendimento per rinforzo funziona bene in contesti complessi e basati sulle decisioni, e il transfer learning è utile quando si desidera costruire su modelli pre-addestrati con dati limitati.
Ogni metodo ha punti di forza e applicazioni uniche, dal riconoscimento facciale alla robotica al trasferimento di stile artistico. La scelta del tipo giusto può sbloccare nuove possibilità in settori come la sanità, l'automotive e l'intrattenimento.
Per saperne di più, visita il nostro repository GitHub e interagisci con la nostra community. Esplora le applicazioni dell'IA nelle auto a guida autonoma e nell'agricoltura nelle nostre pagine delle soluzioni. 🚀


