



Imparate a conoscere l'RCNN e il suo impatto sul rilevamento degli oggetti. Verranno illustrati i suoi componenti chiave, le sue applicazioni e il suo ruolo nell'avanzamento di tecniche come Fast RCNN e YOLO.

Imparate a conoscere l'RCNN e il suo impatto sul rilevamento degli oggetti. Verranno illustrati i suoi componenti chiave, le sue applicazioni e il suo ruolo nell'avanzamento di tecniche come Fast RCNN e YOLO.
Il rilevamento degli oggetti è un'attività di computer vision in grado di riconoscere e localizzare gli oggetti nelle immagini o nei video per applicazioni come la guida autonoma, la sorveglianza e l'imaging medico. I metodi di rilevamento degli oggetti precedenti, come il rilevatore Viola-Jones e l'istogramma dei gradienti orientati (HOG) con le macchine a vettori di supporto (SVM), si basavano su caratteristiche artigianali e finestre scorrevoli. Questi metodi spesso faticavano a detect con precisione gli oggetti in scene complesse con più oggetti di varie forme e dimensioni.
Le reti neurali convoluzionali basate su regioni (R-CNN) hanno cambiato il modo in cui affrontiamo il rilevamento degli oggetti. Si tratta di un'importante pietra miliare nella storia della computer vision. Per capire come modelli come YOLOv8 è nato, dobbiamo prima capire i modelli come R-CNN.
Creato da Ross Girshick e dal suo team, l'architettura del modello R-CNN genera proposte di regione, estrae caratteristiche con una rete neurale convoluzionale (CNN) pre-addestrata, classifica gli oggetti e perfeziona i riquadri di delimitazione. Anche se può sembrare scoraggiante, alla fine di questo articolo avrai una chiara comprensione di come funziona R-CNN e perché è così di impatto. Diamo un'occhiata!
Il processo di object detection del modello R-CNN prevede tre fasi principali: generazione di proposte di regione, estrazione di caratteristiche e classificazione degli oggetti, affinando al contempo i loro bounding box. Analizziamo ogni fase.
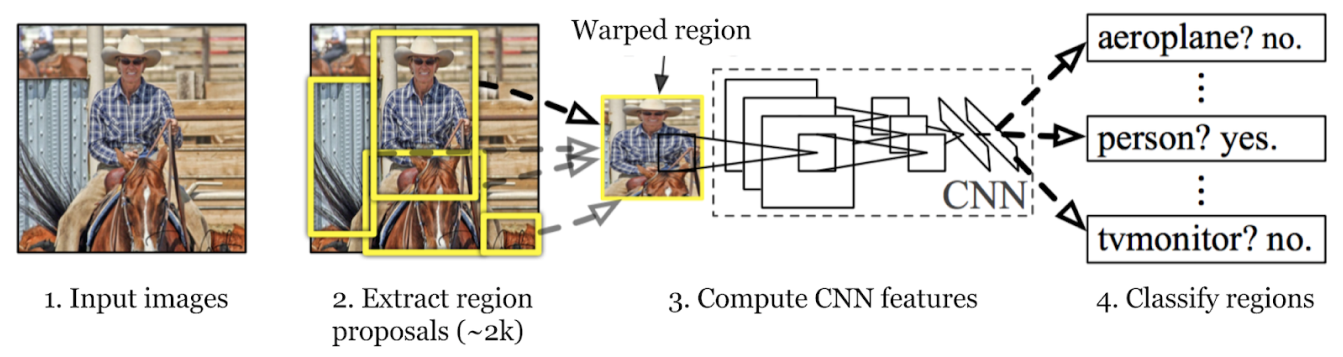
Nella prima fase, il modello R-CNN scansiona l'immagine per creare numerose proposte di regione. Le proposte di regione sono aree potenziali che potrebbero contenere oggetti. Metodi come la Selective Search vengono utilizzati per esaminare vari aspetti dell'immagine, come il colore, la texture e la forma, scomponendola in diverse parti. La Selective Search inizia dividendo l'immagine in parti più piccole, quindi unendo quelle simili per formare aree di interesse più grandi. Questo processo continua fino a quando non vengono generate circa 2.000 proposte di regione.
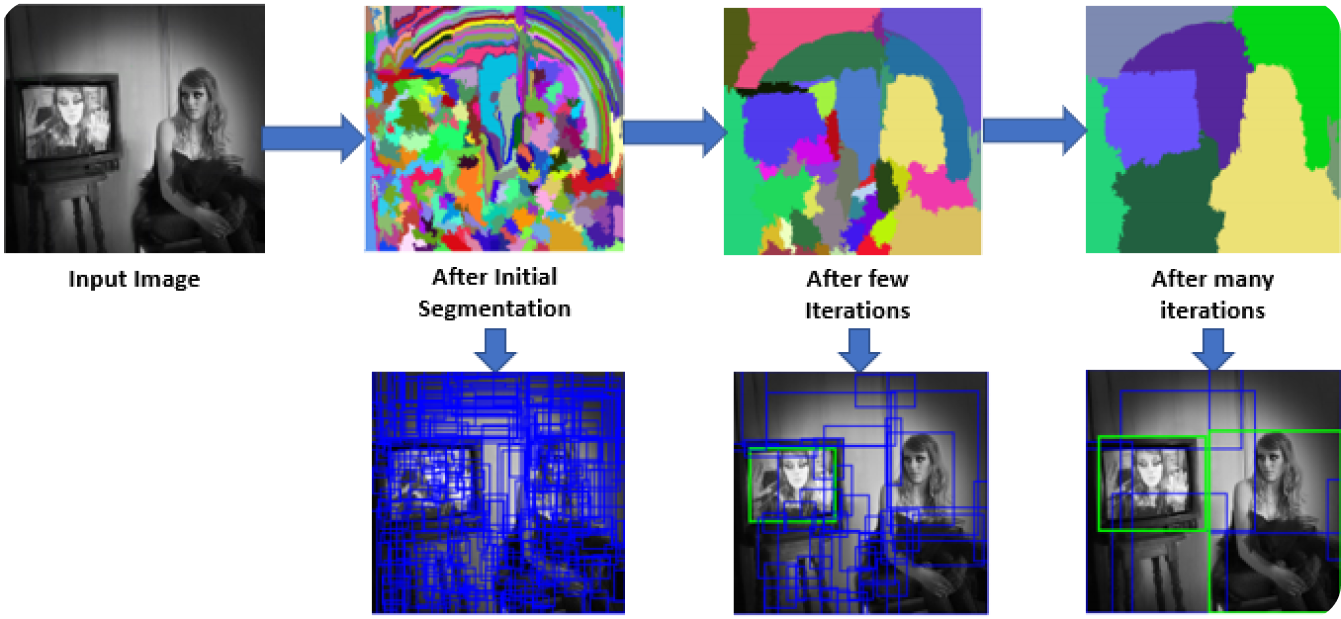
Queste proposte di regione aiutano a identificare tutti i possibili punti in cui un oggetto potrebbe essere presente. Nei passaggi successivi, il modello può elaborare in modo efficiente le aree più rilevanti concentrandosi su queste aree specifiche piuttosto che sull'intera immagine. L'uso di proposte di regione bilancia l'accuratezza con l'efficienza computazionale.
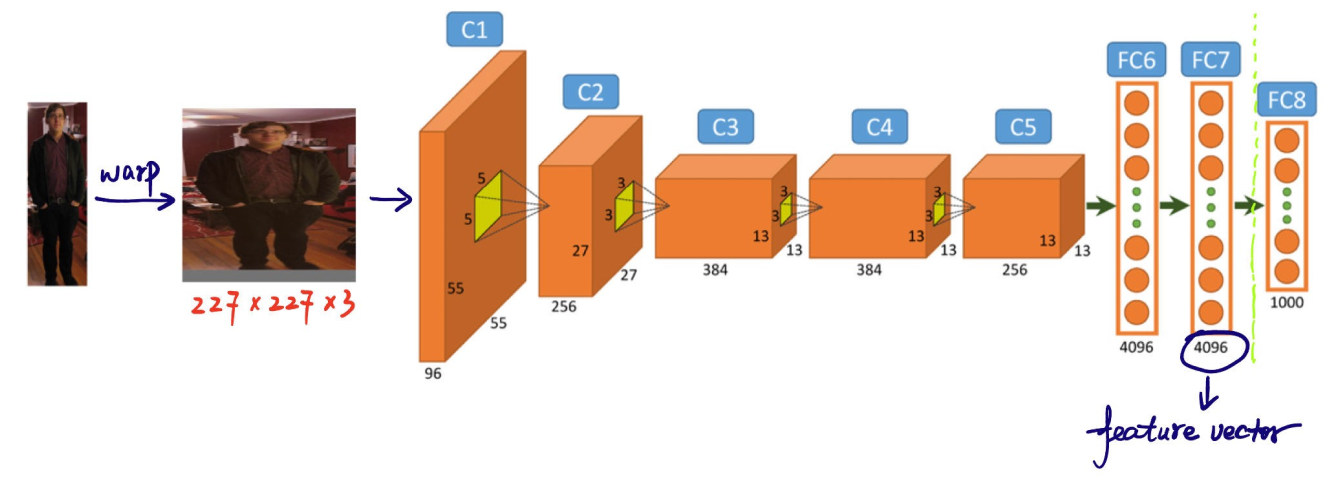
Il passo successivo nel processo di object detection del modello R-CNN è estrarre le caratteristiche dalle region proposals. Ogni region proposal viene ridimensionata a una dimensione coerente che la CNN si aspetta (ad esempio, 224x224 pixel). Il ridimensionamento aiuta la CNN a elaborare ogni proposal in modo efficiente. Prima del warping, la dimensione di ogni region proposal viene leggermente ampliata per includere 16 pixel di contesto aggiuntivo attorno alla regione per fornire maggiori informazioni circostanti per una migliore estrazione delle caratteristiche.
Una volta ridimensionate, queste proposte di regioni vengono inserite in una CNN come AlexNet, che di solito è pre-addestrata su un grande set di dati come ImageNet. La CNN elabora ogni regione per estrarre vettori di caratteristiche ad alta dimensione che catturano dettagli importanti come bordi, texture e modelli. Questi vettori di caratteristiche condensano le informazioni essenziali delle regioni. Trasformano i dati grezzi dell'immagine in un formato che il modello può utilizzare per ulteriori analisi. La classificazione accurata e la localizzazione degli oggetti nelle fasi successive dipendono da questa conversione cruciale delle informazioni visive in dati significativi.
La terza fase consiste nel classify gli oggetti all'interno di queste regioni. Ciò significa determinare la categoria o la classe di ogni oggetto trovato all'interno delle proposte. I vettori di caratteristiche estratti vengono quindi passati attraverso un classificatore di apprendimento automatico.
Nel caso di R-CNN, le Macchine a Vettori di Supporto (SVM) sono comunemente utilizzate per questo scopo. Ogni SVM è addestrata a riconoscere una specifica classe di oggetti analizzando i vettori di caratteristiche e decidendo se una particolare regione contiene un'istanza di quella classe. Essenzialmente, per ogni categoria di oggetti, c'è un classificatore dedicato che controlla ogni proposta di regione per quello specifico oggetto.
Durante l'addestramento, ai classificatori vengono forniti dati etichettati con campioni positivi e negativi:
I classificatori imparano a distinguere tra questi campioni. La regressione del bounding box perfeziona ulteriormente la posizione e le dimensioni degli oggetti rilevati regolando i bounding box proposti inizialmente per adattarsi meglio ai confini effettivi dell'oggetto. Il modello R-CNN può identificare e localizzare accuratamente gli oggetti combinando la classificazione e la regressione del bounding box.
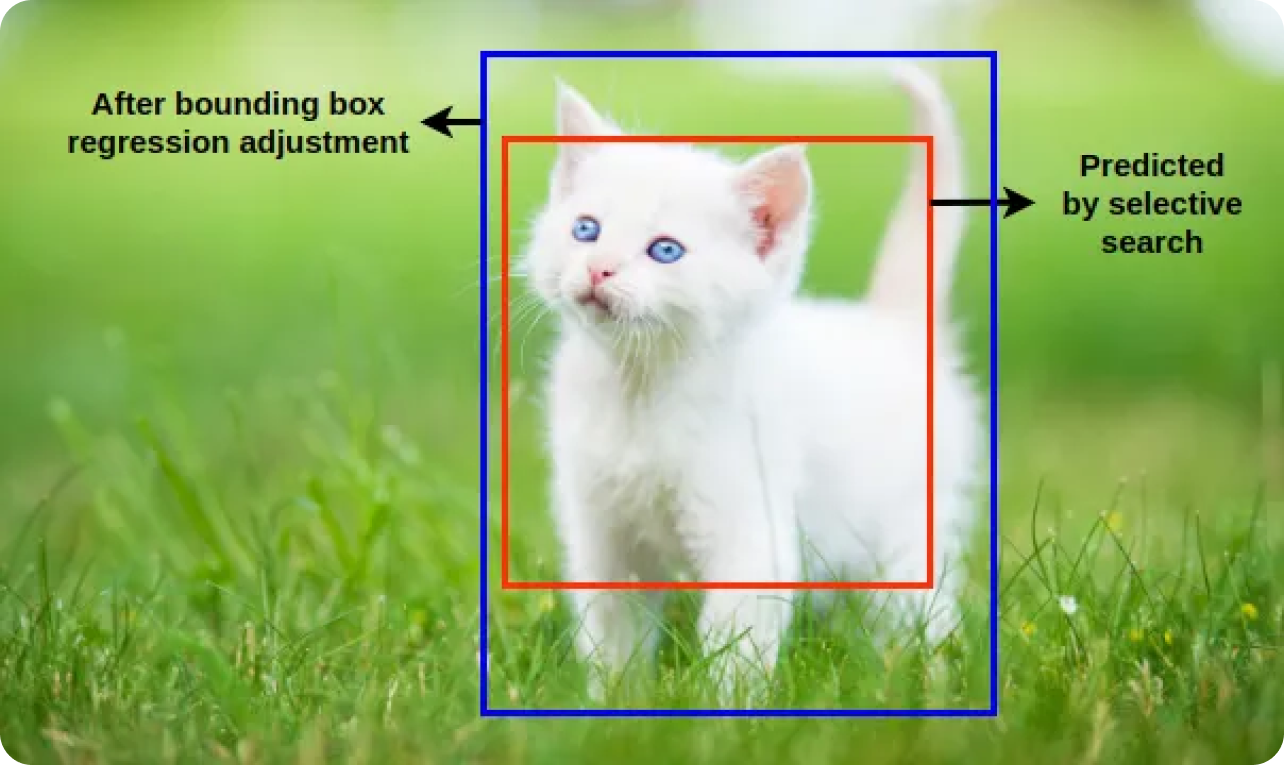
Dopo le fasi di classificazione e regressione dei riquadri di delimitazione, il modello spesso genera più riquadri di delimitazione sovrapposti per lo stesso oggetto. La soppressione non massimaleNMS) viene applicata per affinare questi rilevamenti, mantenendo i riquadri più accurati. Il modello elimina i riquadri ridondanti e sovrapposti applicando la NMS e mantiene solo i rilevamenti più sicuri.
NMS funziona valutando i punteggi di confidenza (che indicano la probabilità che un oggetto rilevato sia effettivamente presente) di tutte le caselle di delimitazione e sopprimendo quelle che si sovrappongono in modo significativo a caselle con punteggi più alti.

Ecco una panoramica delle fasi dell'NMS:
Il modello R-CNN rileva gli oggetti generando proposte di regioni, estraendo caratteristiche con una CNN, classificando gli oggetti e perfezionando le loro posizioni con la regressione del rettangolo di selezione e utilizzando la soppressione non massimaNMS) per mantenere solo i rilevamenti più accurati.
R-CNN è un modello fondamentale nella storia del rilevamento oggetti perché ha introdotto un nuovo approccio che ha notevolmente migliorato l'accuratezza e le prestazioni. Prima di R-CNN, i modelli di rilevamento oggetti faticavano a bilanciare velocità e precisione. Il metodo di R-CNN di generare proposte di regione e utilizzare CNN per l'estrazione di caratteristiche consente la localizzazione e l'identificazione precise degli oggetti all'interno delle immagini.
R-CNN ha aperto la strada a modelli come Fast R-CNN, Faster R-CNN e Mask R-CNN, che hanno ulteriormente migliorato l'efficienza e l'accuratezza. Combinando il deep learning con l'analisi basata sulle regioni, R-CNN ha stabilito un nuovo standard nel campo e ha aperto possibilità per varie applicazioni nel mondo reale.
Un caso d'uso interessante di R-CNN è quello dell'imaging medico. I modelli R-CNN sono stati utilizzati per detect e classify diversi tipi di tumori, come quelli cerebrali, in scansioni mediche come la risonanza magnetica e la TAC. L'uso del modello R-CNN nell'imaging medico migliora l'accuratezza diagnostica e aiuta i radiologi a identificare i tumori maligni in fase iniziale. La capacità di R-CNN di detect anche tumori piccoli e in fase iniziale può fare una differenza significativa nel trattamento e nella prognosi di malattie come il cancro.
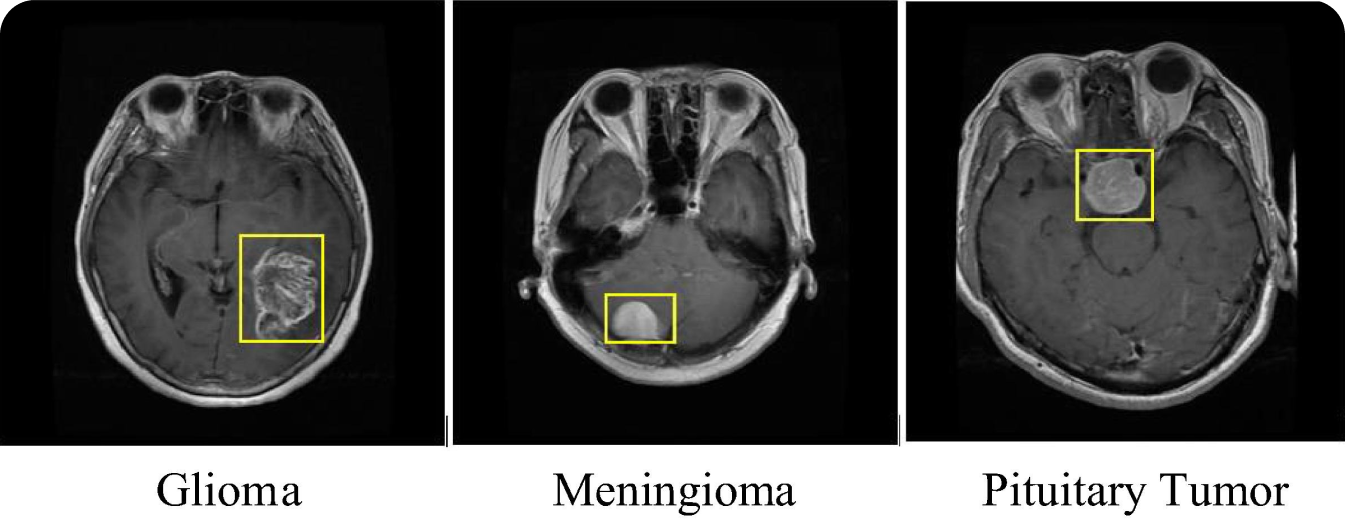
Il modello R-CNN può essere applicato ad altre attività di imaging medico oltre al rilevamento dei tumori. Ad esempio, può identificare le fratture, detect le malattie della retina nelle scansioni oculari e analizzare le immagini polmonari per rilevare condizioni come la polmonite e la COVID-19. Indipendentemente dal problema medico, la diagnosi precoce può portare a risultati migliori per i pazienti. Applicando la precisione di R-CNN nell'identificare e localizzare le anomalie, gli operatori sanitari possono migliorare l'affidabilità e la velocità della diagnostica medica. Con il rilevamento degli oggetti che semplifica il processo di diagnosi, i pazienti possono beneficiare di piani di trattamento tempestivi e accurati.
Sebbene sia impressionante, R-CNN presenta alcuni inconvenienti, come l'elevata complessità computazionale e i tempi di inferenza lenti. Questi inconvenienti rendono il modello R-CNN inadatto per le applicazioni in tempo reale. La separazione delle proposte di regione e delle classificazioni in fasi distinte può portare a prestazioni meno efficienti.
Nel corso degli anni, sono stati sviluppati diversi modelli di object detection che hanno affrontato queste problematiche. Fast R-CNN combina le region proposal e l'estrazione di feature CNN in un unico passaggio, velocizzando il processo. Faster R-CNN introduce una Region Proposal Network (RPN) per semplificare la generazione di proposte, mentre Mask R-CNN aggiunge la segmentazione a livello di pixel per rilevamenti più dettagliati.

Più o meno nello stesso periodo di Faster R-CNN, la serie YOLO (You Only Look Once) ha iniziato a progredire nel rilevamento degli oggetti in tempo reale. I modelli YOLO predicono le bounding box e le probabilità di classe in un unico passaggio attraverso la rete. Ad esempio, il modello Ultralytics YOLOv8 offre una maggiore precisione e velocità con funzioni avanzate per molte attività di computer vision.
RCNN ha cambiato le carte in tavola nella computer vision, dimostrando come l'apprendimento profondo possa cambiare il rilevamento degli oggetti. Il suo successo ha ispirato molte nuove idee nel campo. Anche se modelli più recenti come Faster R-CNN e YOLO hanno risolto i difetti di RCNN, il suo contributo è una pietra miliare importante da ricordare.
Con il proseguire della ricerca, vedremo modelli di rilevamento oggetti ancora migliori e più veloci. Questi progressi non solo miglioreranno il modo in cui le macchine comprendono il mondo, ma porteranno anche a progressi in molti settori. Il futuro del rilevamento oggetti si preannuncia entusiasmante!
Volete continuare a esplorare l'IA? Entrate a far parte dellacomunità di Ultralytics ! Esplorate il nostro repository GitHub per vedere le nostre ultime innovazioni in materia di intelligenza artificiale. Scoprite le nostre soluzioni di intelligenza artificiale in vari settori, come l'agricoltura e la produzione. Unitevi a noi per imparare e progredire!


