



Edge AIとJetson、Triton、TensorRT NVIDIAイノベーションが、コンピュータ・ビジョン・アプリケーションの展開をどのように簡素化しているかをご覧ください。

Edge AIとJetson、Triton、TensorRT NVIDIAイノベーションが、コンピュータ・ビジョン・アプリケーションの展開をどのように簡素化しているかをご覧ください。
近年のコンピュータビジョンと人工知能(AI)の進歩のおかげで、かつては研究分野に過ぎなかったものが、今やさまざまな産業で影響力のあるアプリケーションを推進しています。自動運転車から医療画像処理、セキュリティまで、コンピュータビジョンシステムは現実の問題を大規模に解決しています。
これらのアプリケーションの多くは、画像をリアルタイムで分析し、クラウドコンピューティングに依存することは、レイテンシ、コスト、プライバシーの問題から、必ずしも実用的ではありません。エッジAIは、このような状況に最適なソリューションです。Vision AIモデルをエッジデバイス上で直接実行することにより、企業はより高速、より手頃な価格で、より安全にデータを処理できるため、リアルタイムAIがより利用しやすくなります。
Ultralytics主催の年次ハイブリッドイベントであるYOLO Vision 2024(YV24)では、デプロイメントをよりユーザーフレンドリーかつ効率的にすることで、Vision AIを民主化することが中心テーマの1つとなった。NVIDIAシニア・ソリューション・アーキテクトであるガイ・ダハンは、エッジ・コンピューティング・デバイス、推論サーバー、最適化フレームワーク、AIデプロイメントSDKを含むNVIDIAハードウェアおよびソフトウェア・ソリューションが、開発者がエッジでAIを最適化するのをどのように支援しているかについて説明した。
この記事では、ガイ・ダハンのYV24基調講演の主な要点と、NVIDIA最新のイノベーションがVision AIの導入をより迅速かつスケーラブルにする方法を探ります。
ガイ・ダハンはまず、YV24にバーチャルで参加することへの熱意と、Ultralytics Python パッケージとUltralytics YOLO モデルへの興味を示し、「Ultralytics 発売されたその日から使っています。それ以前からYOLOv5 、このUltralytics 熱狂的なファンなんです」。
次に、彼はエッジAIの概念を紹介し、AI計算を、処理のために遠隔のクラウドサーバーにデータを送信するのではなく、カメラ、ドローン、または産業用機械などのデバイス上で直接実行することを説明しました。
画像やビデオがアップロードされ、分析されて結果が返送されるのを待つ代わりに、エッジAIを使用すると、デバイス自体でデータを即座に分析できます。これにより、Vision AIシステムはより高速、より効率的になり、インターネット接続への依存度が低くなります。エッジAIは、自動運転車、セキュリティカメラ、スマートファクトリーなどのリアルタイムの意思決定アプリケーションに特に役立ちます。
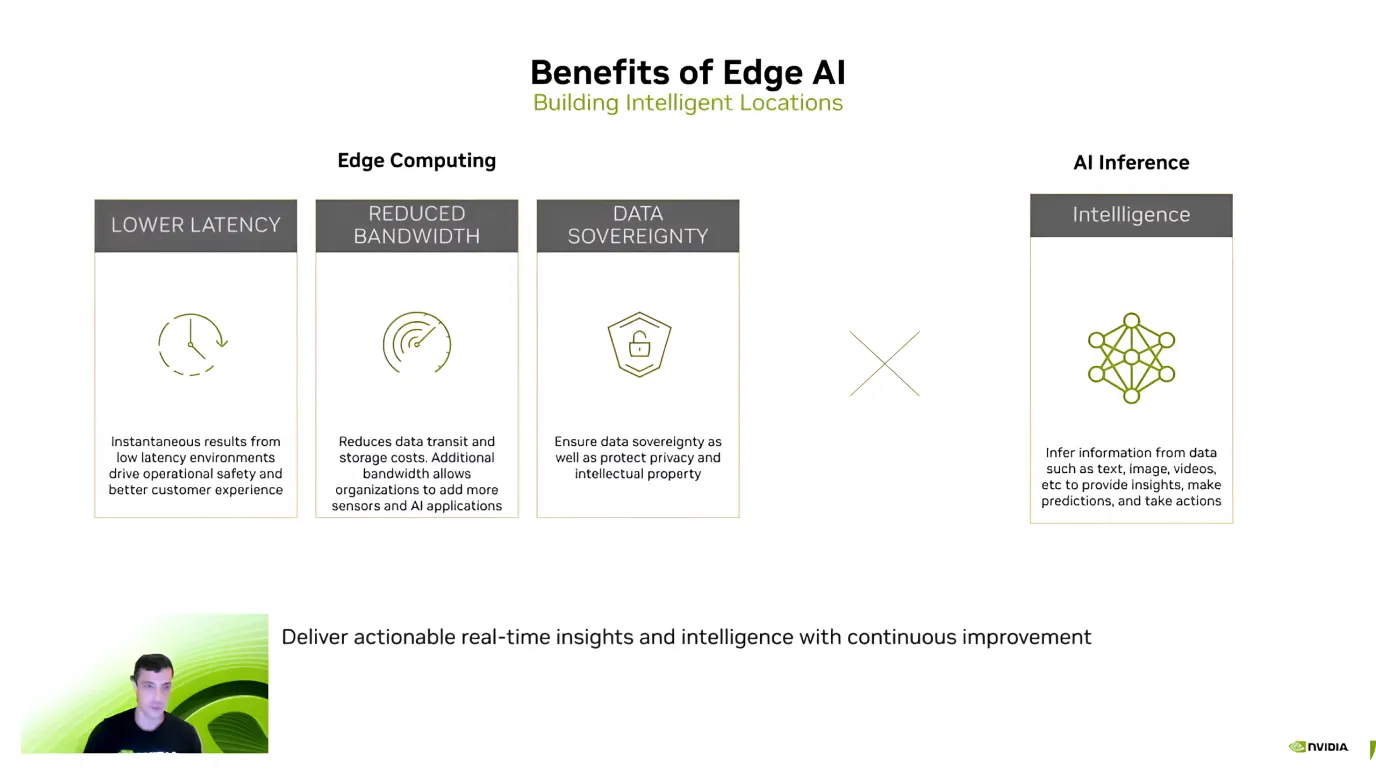
Edge AIを紹介した後、Guy Dahan氏は、効率、コスト削減、データセキュリティに焦点を当て、その主な利点を強調しました。彼は、最大の利点の1つは低遅延であると説明しました。AIモデルはデバイス上で直接データを処理するため、情報をクラウドに送信して応答を待つ必要がないからです。
エッジAIは、コスト削減と機密データの保護にも役立ちます。大量のデータをクラウドに送信する、特にビデオストリームは、コストがかかる可能性があります。しかし、ローカルで処理することで、帯域幅とストレージのコストを削減できます。
もう一つの重要な利点は、情報が外部サーバーに転送されるのではなく、デバイス上に保持されるため、データプライバシーが確保されることです。これは、データをローカルに安全に保つことが最優先事項である医療、金融、セキュリティアプリケーションにとって特に重要です。
こうした利点を踏まえ、ガイ・ダハンはエッジAIの採用拡大についてコメントした。同氏は、NVIDIA 2014年にJetsonを導入して以来、利用が10倍に増えたと指摘。現在、120万人以上の開発者がJetsonデバイスを使用しています。
ガイ・ダハンは次に、低消費電力で高性能を実現するように設計されたAIエッジコンピューティングデバイスのファミリーであるNVIDIA Jetsonデバイスに焦点を当てた。Jetsonデバイスは、ロボット工学、農業、ヘルスケア、産業オートメーションなどの分野におけるコンピュータ・ビジョン・アプリケーションに最適です。「ジェットソンは、AIのために特別に作られたエッジAIデバイスです。元々はコンピュータ・ビジョンのために設計されたものです」とガイ・ダハンは付け加えた。
Jetsonデバイスには3つの階層があり、それぞれ異なるニーズに対応します。
また、ガイ・ダハンは、今年発売予定のJetson AGX Thorについて、GPU (グラフィック・プロセッシング・ユニット)性能は8倍、メモリ容量は2倍、CPU (中央演算処理装置)性能は向上すると語った。この製品は、特にヒューマノイド・ロボティクスや高度なエッジAIアプリケーション向けに設計されている。
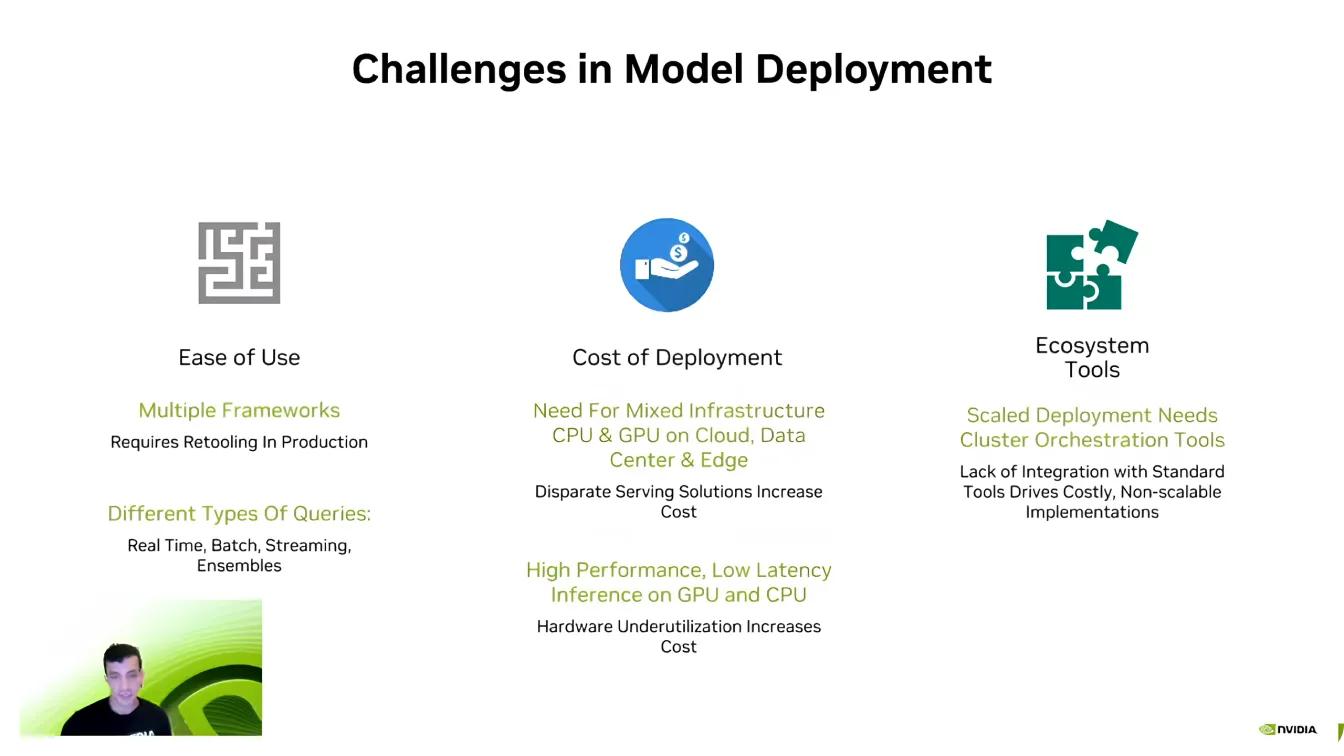
ガイ・ダハン氏はその後、エッジAIのソフトウェア側に軸足を移し、強力なハードウェアがあっても、モデルを効率的にデプロイするのは難しい場合があると説明しました。
AI開発者はPyTorch TensorFlowような異なるAIフレームワークで作業することが多いため、最大のハードルの1つは互換性だ。これらのフレームワーク間の移動は難しく、開発者はすべてが正しく実行されるように環境を作り直す必要がある。
スケーラビリティもまた、重要な課題です。AIモデルは膨大な計算能力を必要とし、Dahan氏が言うように、「より少ない計算能力を求めるAI企業は存在しません。」複数のデバイスにAIアプリケーションを拡張すると、すぐにコストがかさむため、最適化が不可欠になります。
また、AIパイプラインは複雑で、多くの場合、さまざまな種類のデータ、リアルタイム処理、およびシステム統合が含まれます。開発者は、モデルが既存のソフトウェアエコシステムとシームレスに連携するように多大な努力を払っています。これらの課題を克服することは、AIデプロイメントをより効率的かつスケーラブルにする上で重要な部分です。
次にガイ・ダハンは、NVIDIA Triton Inference Serverに注目した。彼は、多くの企業や新興企業がモデルの最適化を十分に行わないままAI開発を始めていることを指摘した。AIパイプライン全体をゼロから再設計することは、破壊的で時間のかかることであり、効率的なスケールが難しくなります。
Triton 、システムの完全なオーバーホールを必要とする代わりに、開発者がAIワークフローを徐々に改良・最適化し、既存のセットアップを壊すことなく、より効率的なコンポーネントを統合することを可能にします。TensorFlow、PyTorch、ONNX、TensorRT複数のAIフレームワークをサポートするTriton 、最小限の調整でクラウド環境、データセンター、エッジデバイスへのシームレスな導入を可能にします。

NVIDIA Triton Inference Serverの主な利点は以下の通りです:
さらに高速化を求めているとしよう; NVIDIA TensorRTは、AIモデルを最適化するための興味深い選択肢です。Guy Dahan氏は、TensorRT NVIDIA GPUのために構築された高性能ディープラーニング・オプティマイザーであると詳しく説明した。TensorFlow、PyTorch、ONNX、MXNetのモデルは、TensorRT使用して、非常に効率的なGPUファイルに変換することができます。
TensorRT これほど信頼できるのは、ハードウェアに特化した最適化を行っているからだ。Jetsonデバイス用に最適化されたモデルは、他のGPUでは効率的に動作しません。これは、TensorRT ターゲットハードウェアに基づいてパフォーマンスを微調整するためです。微調整されたコンピュータビジョンモデルは、最適化されていないモデルと比較して、推論速度が最大36倍向上します。
Guy Dahan氏はまた、Ultralytics TensorRTサポートしていることに注目し、AIモデルのデプロイをより迅速かつ効率的にする方法について語った。Ultralytics YOLO モデルは、TensorRT フォーマットに直接エクスポートすることができ、開発者は変更を加えることなく、NVIDIA GPU用に最適化することができます。
ガイ・ダハンは、NVIDIA GPUを使用したビデオ、オーディオ、センサーデータのリアルタイム処理用に設計されたAIフレームワークであるDeepStream 7.0を紹介した。高速なコンピュータ・ビジョン・アプリケーションをサポートするために構築されたこのフレームワークは、自律システム、セキュリティ、産業オートメーション、スマートシティにおける物体検出、追跡、分析を可能にします。エッジデバイス上でAIを直接実行することで、DeepStreamはクラウドへの依存を排除し、待ち時間を短縮して効率を向上させます。

具体的には、DeepStreamはAIを活用したビデオ処理を最初から最後まで処理できます。ビデオのデコードとプリプロセッシングから、AI推論とポストプロセッシングまで、エンドツーエンドのワークフローをサポートします。
最近、DeepStream は AI のデプロイメントを強化するためにいくつかのアップデートを導入し、よりアクセスしやすく、スケーラブルにしました。新しいツールは、開発を簡素化し、マルチカメラトラッキングを改善し、AI パイプラインを最適化してパフォーマンスを向上させます。
開発者は、Windows環境に対するサポートの拡大、複数のソースからのデータを統合するための高度なセンサーフュージョン機能、およびデプロイを加速するための構築済みのリファレンスアプリケーションへのアクセスを利用できるようになりました。これらの改善により、DeepStreamはリアルタイムAIアプリケーション向けのより柔軟で効率的なソリューションとなり、開発者はインテリジェントなビデオ分析を容易に拡張できます。
YV24でのガイ・ダハンの基調講演で説明されているように、エッジAIはコンピュータビジョンのアプリケーションを再定義しています。ハードウェアとソフトウェアの進歩により、リアルタイム処理はより高速、より効率的、そして費用対効果が高まっています。
より多くの産業がエッジAIを採用するにつれて、断片化や展開の複雑さなどの課題に対処することが、その潜在能力を最大限に引き出すための鍵となります。これらのイノベーションを受け入れることで、よりスマートで応答性の高いAIアプリケーションが推進され、コンピュータビジョンの未来が形作られるでしょう。
成長を続けるコミュニティに参加しませんか?GitHubリポジトリでAIについてさらに学び、ライセンスオプションをチェックして、Vision AIプロジェクトを始めましょう。ヘルスケアにおけるAIや製造業におけるコンピュータビジョンなどのイノベーションにご興味がありますか?ソリューションページで詳細をご覧ください。


