



Explore a história, as conquistas, os desafios e as direções futuras dos modelos de visão.

Explore a história, as conquistas, os desafios e as direções futuras dos modelos de visão.
Imagine entrar em uma loja onde uma câmera identifica seu rosto, analisa seu humor e sugere produtos personalizados de acordo com suas preferências — tudo em tempo real. Isso não é ficção científica, mas uma realidade possibilitada pelos modelos de visão modernos. De acordo com um relatório da Fortune Business Insight, o tamanho do mercado global de visão computacional foi avaliado em USD 20,31 bilhões em 2023 e está projetado para crescer de USD 25,41 bilhões em 2024 para USD 175,72 bilhões até 2032, refletindo os rápidos avanços e a crescente adoção desta tecnologia em vários setores.
O domínio da visão por computador permite aos computadores detect, identificar e analisar objectos nas imagens. À semelhança de outros domínios relacionados com a IA, a visão por computador registou uma rápida evolução nas últimas décadas, alcançando avanços notáveis.
A história da visão computacional é extensa. Em seus primeiros anos, os modelos de visão computacional eram capazes de detectar formas e bordas simples, muitas vezes limitados a tarefas básicas como reconhecer padrões geométricos ou diferenciar entre áreas claras e escuras. No entanto, os modelos de hoje podem executar tarefas complexas, como detecção de objetos em tempo real, reconhecimento facial e até mesmo interpretar emoções a partir de expressões faciais com excepcional precisão e eficiência. Essa progressão dramática destaca os incríveis avanços feitos em poder computacional, sofisticação algorítmica e a disponibilidade de vastas quantidades de dados para treinamento.
Neste artigo, exploraremos os principais marcos na evolução da visão computacional. Viajaremos por seus primórdios, investigaremos o impacto transformador das Redes Neurais Convolucionais (CNNs) e examinaremos os avanços significativos que se seguiram.
Como em outros campos da IA, o desenvolvimento inicial da visão computacional começou com pesquisa fundamental e trabalho teórico. Um marco significativo foi o trabalho pioneiro de Lawrence G. Roberts no reconhecimento de objetos 3D, documentado em sua tese "Machine Perception of Three-Dimensional Solids" no início dos anos 1960. Suas contribuições lançaram as bases para futuros avanços no campo.
A investigação inicial em visão computacional centrava-se em técnicas de processamento de imagem, como a deteção de arestas e a extração de caraterísticas. Algoritmos como o operador Sobel, desenvolvido no final da década de 1960, foram dos primeiros a detect bordos através do cálculo do gradiente da intensidade da imagem.

Técnicas como os detectores de borda de Sobel e Canny desempenharam um papel crucial na identificação de limites dentro de imagens, que são essenciais para reconhecer objetos e entender cenas.
Na década de 1970, o reconhecimento de padrões emergiu como uma área-chave da visão computacional. Os pesquisadores desenvolveram métodos para reconhecer formas, texturas e objetos em imagens, o que abriu caminho para tarefas de visão mais complexas.

Um dos primeiros métodos para reconhecimento de padrões envolvia a correspondência de modelos, onde uma imagem é comparada a um conjunto de modelos para encontrar a melhor correspondência. Essa abordagem foi limitada por sua sensibilidade a variações de escala, rotação e ruído.
Os primeiros sistemas de visão computacional eram limitados pelo poder computacional limitado da época. Os computadores nas décadas de 1960 e 1970 eram volumosos, caros e tinham capacidades de processamento limitadas.
O deep learning e as Redes Neurais Convolucionais (CNNs) marcaram um momento crucial no campo da visão computacional. Esses avanços transformaram drasticamente a forma como os computadores interpretam e analisam dados visuais, permitindo uma ampla gama de aplicações que antes eram consideradas impossíveis.
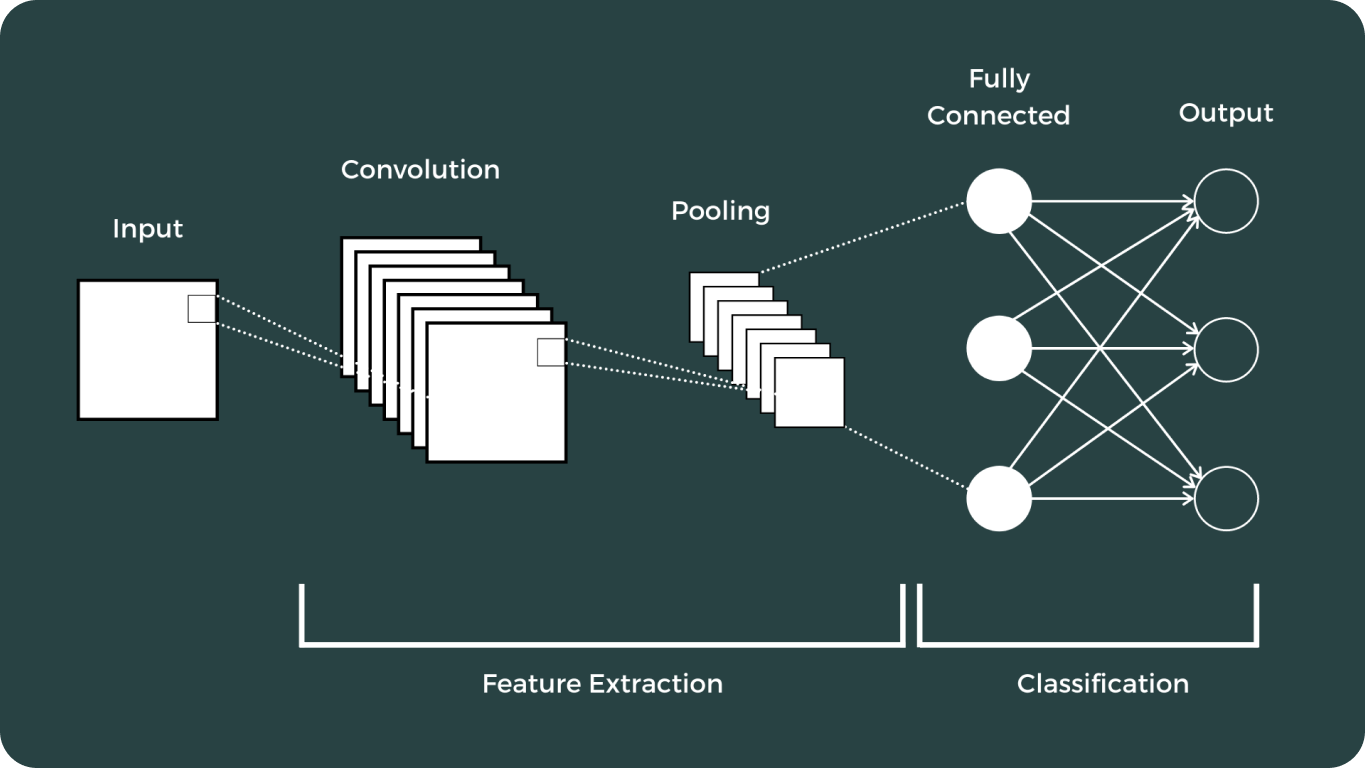
A jornada dos modelos de visão tem sido extensa, apresentando alguns dos mais notáveis:
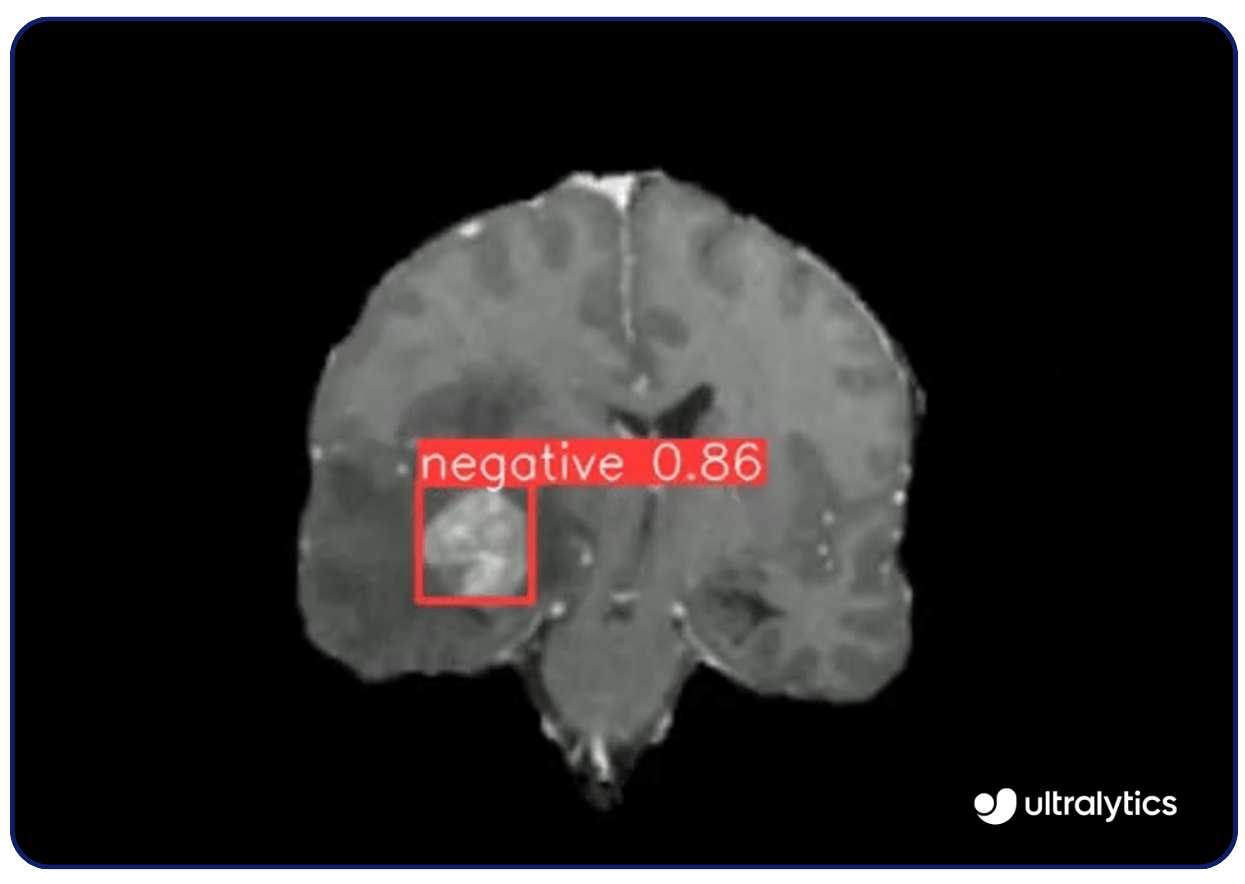
Asutilizações da visão computacional são numerosas. Por exemplo, modelos de visão como o Ultralytics YOLOv8 são utilizados na imagiologia médica para detect doenças como o cancro e a retinopatia diabética. Analisam os raios X, as ressonâncias magnéticas e as tomografias computorizadas com elevada precisão, identificando precocemente as anomalias. Esta capacidade de deteção precoce permite intervenções atempadas e melhores resultados para os doentes.
Os modelos de visão por computador ajudam a monitorizar e a proteger espécies ameaçadas de extinção, analisando imagens e vídeos de habitats de vida selvagem. Identificam e track o comportamento dos animais, fornecendo dados sobre a sua população e movimentos. Esta tecnologia informa as estratégias de conservação e as decisões políticas para proteger espécies como os tigres e os elefantes.
Com a ajuda da visão computacional, outras ameaças ambientais, como incêndios florestais e desmatamento, podem ser monitoradas, garantindo tempos de resposta rápidos das autoridades locais.

Apesar de já terem alcançado feitos significativos, devido à sua extrema complexidade e à natureza exigente de seu desenvolvimento, os modelos de visão enfrentam inúmeros desafios que exigem pesquisa contínua e avanços futuros.
Os modelos de visão, especialmente os de aprendizado profundo, são frequentemente vistos como "caixas pretas" com transparência limitada. Isso se deve à grande complexidade de tais modelos. A falta de interpretabilidade dificulta a confiança e a responsabilidade, especialmente em aplicações críticas como a área da saúde, por exemplo.
Treinar e implementar modelos de IA de última geração exige recursos computacionais significativos. Isso é particularmente verdadeiro para modelos de visão, que geralmente exigem o processamento de grandes quantidades de dados de imagem e vídeo. Imagens e vídeos de alta definição, estando entre as entradas de treinamento com maior intensidade de dados, aumentam a carga computacional. Por exemplo, uma única imagem HD pode ocupar vários megabytes de armazenamento, tornando o processo de treinamento intensivo em recursos e demorado.
Isso exige hardware poderoso e algoritmos de visão computacional otimizados para lidar com os extensos dados e os cálculos complexos envolvidos no desenvolvimento de modelos de visão eficazes. A pesquisa sobre arquiteturas mais eficientes, compressão de modelos e aceleradores de hardware como GPUs e TPUs são áreas-chave que impulsionarão o futuro dos modelos de visão.
Estas melhorias têm como objetivo reduzir as exigências computacionais e aumentar a eficiência do processamento. Além disso, a utilização de modelos avançados pré-treinados como o YOLOv8 pode reduzir significativamente a necessidade de formação extensiva, simplificando o processo de desenvolvimento e aumentando a eficiência.
Atualmente, as aplicações de modelos de visão são generalizadas, variando desde a área da saúde, como a detecção de tumores, até usos cotidianos como o monitoramento de tráfego. Esses modelos avançados trouxeram inovação para inúmeras indústrias, fornecendo precisão, eficiência e capacidades aprimoradas que antes eram inimagináveis.
À medida que a tecnologia continua a avançar, o potencial para os modelos de visão inovarem e melhorarem vários aspectos da vida e da indústria permanece ilimitado. Essa evolução contínua ressalta a importância da pesquisa e do desenvolvimento contínuos no campo da visão computacional.
Curioso sobre o futuro da IA de visão? Para obter mais informações sobre os últimos avanços, explore os documentosUltralytics e consulte os seus projectos no GitHubUltralytics e no GitHub doYOLOv8 . Além disso, para obter informações sobre as aplicações de IA em vários sectores, as páginas de soluções sobre carros autónomos e fabrico oferecem informações particularmente úteis.


