


Explorando como funcionam as aplicações de visão computacional

Mergulhe fundo conosco nas aplicações da visão computacional. Também vamos abordar várias tarefas de visão computacional, como detecção e segmentação de objetos.

Mergulhe fundo conosco nas aplicações da visão computacional. Também vamos abordar várias tarefas de visão computacional, como detecção e segmentação de objetos.
Quando explorámos a história dos modelos de visão por computador, vimos como a visão por computador evoluiu e o caminho que conduziu aos modelos de visão avançados que temos atualmente. Modelos modernos como o Ultralytics YOLOv8 suportam múltiplas tarefas de visão computacional e estão a ser utilizados em várias aplicações interessantes.
Neste artigo, vamos analisar os conceitos básicos da visão computacional e dos modelos de visão. Abordaremos como eles funcionam e suas diversas aplicações em vários setores. As inovações em visão computacional estão em toda parte, moldando silenciosamente o nosso mundo. Vamos descobri-las uma por uma!
A inteligência artificial (IA) é um termo abrangente que engloba muitas tecnologias que visam replicar uma parte da inteligência humana. Um desses subcampos da IA é a visão computacional. A visão computacional se concentra em dar às máquinas olhos que podem ver, observar e compreender seus arredores.
Tal como a visão humana, as soluções de visão por computador visam distinguir objectos, calcular distâncias e detect movimentos. No entanto, ao contrário dos humanos, que têm uma vida inteira de experiências para os ajudar a ver e a compreender, os computadores dependem de grandes quantidades de dados, câmaras de alta definição e algoritmos complexos.
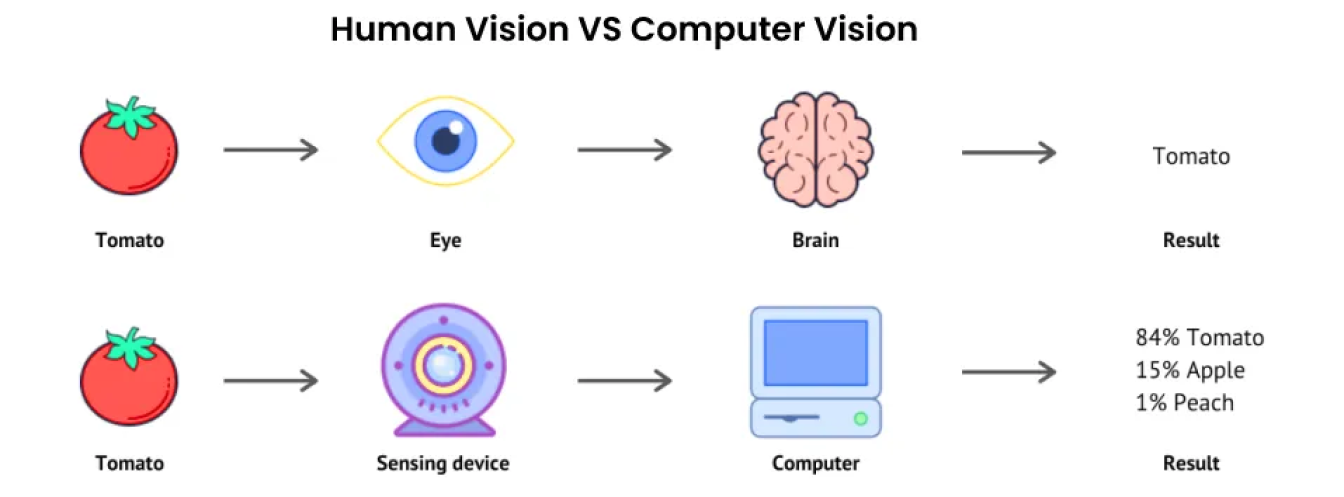
Os sistemas de visão computacional podem processar e analisar dados visuais, como imagens e vídeos, com velocidades e precisão incríveis. A capacidade de analisar de forma rápida e precisa grandes quantidades de informações visuais torna a visão computacional uma ferramenta poderosa em vários setores, desde a manufatura até a saúde.
Os modelos de visão computacional são o núcleo de qualquer aplicação de visão computacional. São essencialmente algoritmos computacionais alimentados por técnicas de aprendizagem profunda concebidos para dar às máquinas a capacidade de interpretar e compreender informações visuais. Os modelos de visão permitem tarefas cruciais de visão computacional, desde a classificação de imagens à deteção de objetos. Vamos analisar mais de perto algumas destas tarefas e os seus casos de utilização com mais detalhe.
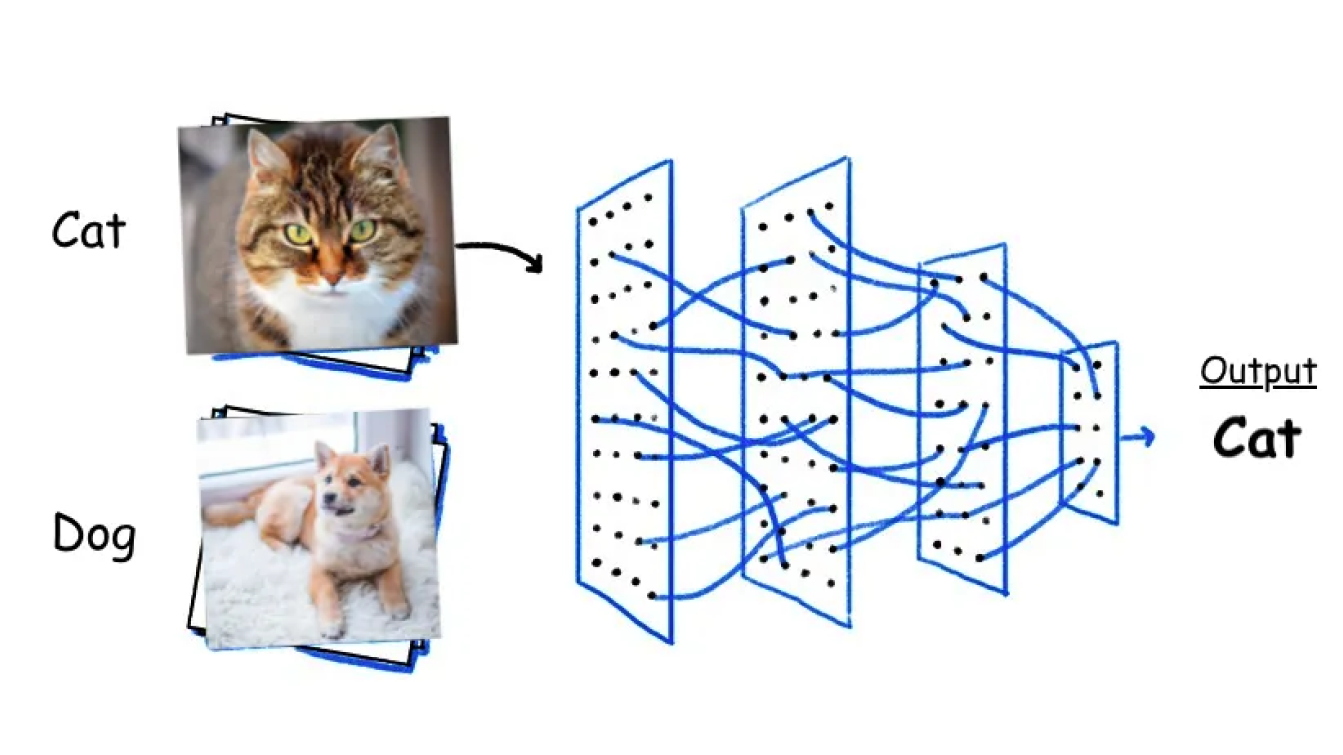
A classificação de imagens envolve a categorização e rotulagem de imagens em classes ou categorias predefinidas. Um modelo de visão como o YOLOv8 pode ser treinado em grandes conjuntos de dados de imagens rotuladas. Durante o treino, o modelo aprende a reconhecer padrões e caraterísticas associadas a cada classe. Uma vez treinado, pode prever a categoria de imagens novas e não vistas, analisando as suas caraterísticas e comparando-as com os padrões aprendidos.
Existem diferentes tipos de classificação de imagens. Por exemplo, quando se trata de imagens médicas, pode utilizar a classificação binária para dividir as imagens em dois grupos, como saudáveis ou doentes. Outro tipo é a classificação multiclasse. Pode ajudar a classify imagens em vários grupos, como classificar diferentes animais numa quinta, como porcos, cabras e vacas. Ou, digamos que pretende classify animais em grupos e subgrupos, como classificar animais em mamíferos e aves e depois em espécies como leões, tigres, águias e pardais; a classificação hierárquica seria a melhor opção.
A detecção de objetos é o processo de identificar e localizar objetos em imagens e quadros de vídeo usando visão computacional. Consiste em duas tarefas: localização de objetos, que desenha bounding boxes ao redor dos objetos, e classificação de objetos, que identifica a categoria de cada objeto. Com base nas anotações de bounding box, um modelo de visão pode aprender a reconhecer padrões e características específicas de cada categoria de objeto e prever a presença e localização desses objetos em novas imagens não vistas.
.png)
A detecção de objetos tem muitos casos de uso em diferentes setores, desde esportes até biologia marinha. Por exemplo, no varejo, a tecnologia Just Walk Out da Amazon usa a detecção de objetos para automatizar o checkout, identificando os itens que os clientes pegam. Uma combinação de visão computacional e dados de sensores permite que os clientes peguem seus itens e saiam sem esperar na fila.
Aqui está uma visão mais detalhada de como funciona:
A segmentação semântica e a segmentação de instâncias são tarefas de visão computacional que ajudam a particionar imagens em segmentos significativos. A segmentação semântica classifica os pixels com base em seu significado semântico e trata todos os objetos dentro de uma categoria como uma única entidade com o mesmo rótulo. É adequado para rotular objetos incontáveis como "o céu" ou "oceano" ou agrupamentos como "folhas" ou "grama".
A segmentação de instâncias, por outro lado, pode distinguir diferentes instâncias da mesma classe, atribuindo uma etiqueta única a cada objeto detectado. Pode utilizar a segmentação de instâncias para segment objectos contáveis, onde o número e a independência dos objectos são importantes. Permite uma identificação e diferenciação mais precisas.
.png)
Podemos compreender melhor o contraste entre a segmentação semântica e a segmentação por instância com um exemplo relacionado com os veículos autónomos. A segmentação semântica é excelente para tarefas que requerem a compreensão do conteúdo de uma cena e pode ser utilizada em veículos autónomos para classify caraterísticas na estrada, como passagens de peões e sinais de trânsito. Entretanto, a segmentação de instâncias pode ser utilizada em veículos autónomos para identificar peões individuais, veículos e obstáculos.
A estimativa de pose é uma tarefa de visão computacional focada em detectar e rastrear pontos-chave das poses de um objeto em imagens ou vídeos. É mais comumente usada para estimativa de pose humana, com pontos-chave incluindo áreas como ombros e joelhos. Estimar a pose de um humano nos ajuda a entender e reconhecer ações e movimentos que são críticos para várias aplicações.

A estimativa de pose pode ser usada em esportes para analisar como os atletas se movem. A NBA usa a estimativa de pose para estudar os movimentos e posições dos jogadores durante o jogo. Ao rastrear pontos-chave como ombros, cotovelos, joelhos e tornozelos, a estimativa de pose fornece insights detalhados sobre os movimentos dos jogadores. Esses insights ajudam os treinadores a desenvolver melhores estratégias, otimizar programas de treinamento e fazer ajustes em tempo real durante os jogos. Além disso, os dados podem ajudar a monitorar a fadiga do jogador e o risco de lesões para melhorar a saúde e o desempenho geral do jogador.
A Detecção de Objetos com Caixas Delimitadoras Orientadas (OBB) usa retângulos rotacionados para identificar e localizar com precisão objetos em uma imagem. Ao contrário das caixas delimitadoras padrão que se alinham com os eixos da imagem, as OBBS giram para corresponder à orientação do objeto. Isso as torna especialmente úteis para objetos que não são perfeitamente horizontais ou verticais. Elas são ótimas para identificar e isolar com precisão objetos rotacionados para evitar sobreposições em ambientes lotados.
.png)
Na vigilância marítima, identificar e rastrear navios é fundamental para a segurança e gestão de recursos. A detecção OBB pode ser usada para a localização precisa de navios, mesmo quando estão densamente compactados ou orientados em vários ângulos. Ajuda a monitorar as rotas de navegação, gerenciar o tráfego marítimo e otimizar as operações portuárias. Também pode auxiliar na resposta a desastres, identificando e avaliando rapidamente os danos a navios e infraestruturas após eventos como furacões ou derramamentos de óleo.
Até agora, falámos de tarefas de visão por computador que lidam com imagens. O seguimento de objectos é uma tarefa de visão por computador que pode track um objeto ao longo dos fotogramas de um vídeo. Começa por identificar o objeto na primeira imagem utilizando algoritmos de deteção e, em seguida, segue continuamente a sua posição à medida que se move no vídeo. O seguimento de objectos envolve técnicas como a deteção de objectos, a extração de caraterísticas e a previsão de movimentos para manter o seguimento preciso.

Modelos de visão como o YOLOv8 podem ser utilizados para track peixes em biologia marinha. Utilizando câmaras subaquáticas, os investigadores podem monitorizar os movimentos e comportamentos dos peixes nos seus habitats naturais. O processo começa por detetar peixes individuais nos primeiros fotogramas e depois segue as suas posições ao longo do vídeo. O seguimento dos peixes ajuda os cientistas a compreender os padrões de migração, os comportamentos sociais e as interações com o ambiente. Também apoia práticas de pesca sustentáveis, fornecendo informações sobre a distribuição e abundância dos peixes.
A visão computacional está mudando ativamente a forma como usamos a tecnologia e interagimos com o mundo. Ao usar modelos de aprendizado profundo e algoritmos complexos para entender imagens e vídeos, a visão computacional ajuda as indústrias a otimizar muitos processos. Tarefas de visão computacional, como detecção e rastreamento de objetos, estão possibilitando a criação de soluções que não haviam sido imaginadas antes. À medida que a tecnologia de visão computacional continua a melhorar, o futuro reserva muitas outras aplicações inovadoras!
Vamos aprender e crescer juntos! Explore nosso repositório GitHub para ver nossas contribuições para a IA. Veja como estamos redefinindo setores como carros autônomos e agricultura com IA. 🚀
.webp)

.webp)