


A evolução da deteção de objectos e os modelos YOLO da Ultralytics

Junte-se a nós para fazermos uma retrospetiva da evolução da deteção de objectos. Iremos centrar-nos na forma como os modelos YOLO (You Only Look Once) avançaram nos últimos anos.

Junte-se a nós para fazermos uma retrospetiva da evolução da deteção de objectos. Iremos centrar-nos na forma como os modelos YOLO (You Only Look Once) avançaram nos últimos anos.
A visão computacional é um subcampo da inteligência artificial (IA) que se concentra em ensinar as máquinas a ver e entender imagens e vídeos, de forma semelhante a como os humanos percebem o mundo real. Embora reconhecer objetos ou identificar ações seja algo natural para os humanos, essas tarefas exigem técnicas de visão computacional específicas e especializadas quando se trata de máquinas. Por exemplo, uma tarefa fundamental na visão computacional é a detecção de objetos, que envolve identificar e localizar objetos dentro de imagens ou vídeos.
Desde os anos 60, os investigadores têm trabalhado para melhorar a forma como os computadores podem detect objectos. Os primeiros métodos, como a correspondência de modelos, envolviam o deslizamento de um modelo predefinido numa imagem para encontrar correspondências. Embora inovadoras, estas abordagens tinham dificuldades em lidar com as alterações no tamanho, orientação e iluminação dos objectos. Atualmente, dispomos de modelos avançados como o Ultralytics YOLO11 que conseguem detect até objectos pequenos e parcialmente ocultos, conhecidos como objectos ocluídos, com uma precisão impressionante.
À medida que a visão por computador continua a evoluir, é importante olhar para trás e ver como estas tecnologias se desenvolveram. Neste artigo, vamos explorar a evolução da deteção de objectos e analisar a transformação dos modelosYOLO (You Only Look Once). Vamos começar!
Antes de nos debruçarmos sobre a deteção de objectos, vejamos como começou a visão por computador. As origens da visão por computador remontam ao final dos anos 50 e início dos anos 60, quando os cientistas começaram a explorar a forma como o cérebro processa a informação visual. Em experiências com gatos, os investigadores David Hubel e Torsten Wiesel descobriram que o cérebro reage a padrões simples, como arestas e linhas. Isto constituiu a base para a ideia subjacente à extração de caraterísticas - o conceito de que os sistemas visuais detect e reconhecem caraterísticas básicas nas imagens, como arestas, antes de passarem a padrões mais complexos.

Quase ao mesmo tempo, surgiu uma nova tecnologia que podia transformar imagens físicas em formatos digitais, despertando o interesse em como as máquinas poderiam processar informações visuais. Em 1966, o Summer Vision Project do Massachusetts Institute of Technology (MIT) impulsionou ainda mais as coisas. Embora o projeto não tenha tido total sucesso, ele visava criar um sistema que pudesse separar o primeiro plano do fundo em imagens. Para muitos na comunidade de Visão de IA, este projeto marca o início oficial da visão computacional como um campo científico.
Com o avanço da visão computacional no final dos anos 90 e início dos anos 2000, os métodos de deteção de objectos passaram de técnicas básicas como a correspondência de modelos para abordagens mais avançadas. Um método popular foi o Haar Cascade, que se tornou amplamente utilizado para tarefas como a deteção de rostos. Funcionava digitalizando imagens com uma janela deslizante, verificando caraterísticas específicas como arestas ou texturas em cada secção da imagem e, em seguida, combinando essas caraterísticas para detect objectos como rostos. O Haar Cascade era muito mais rápido do que os métodos anteriores.
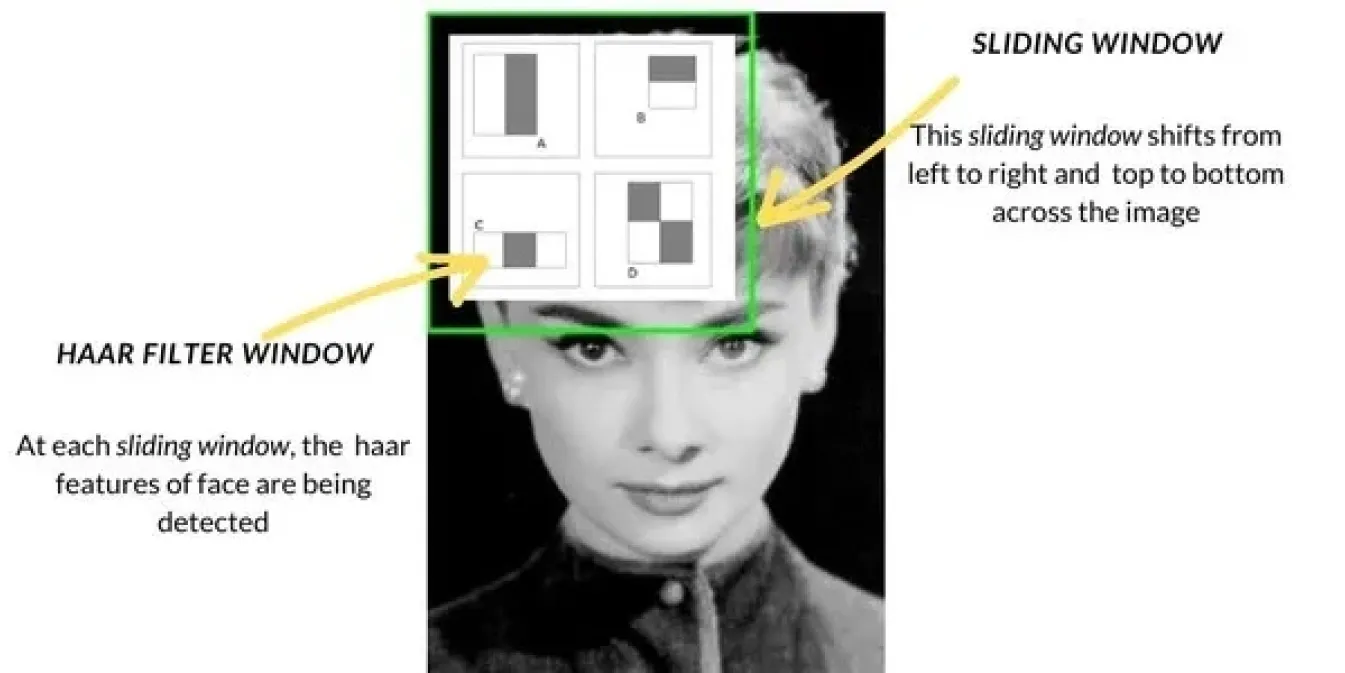
Além destes, métodos como Histogram of Oriented Gradients (HOG) e Support Vector Machines (SVMs) também foram introduzidos. O HOG usava a técnica de janela deslizante para analisar como a luz e as sombras mudavam em pequenas seções de uma imagem, ajudando a identificar objetos com base em suas formas. Os SVMs então classificavam esses recursos para determinar a identidade do objeto. Esses métodos melhoraram a precisão, mas ainda enfrentavam dificuldades em ambientes do mundo real e eram mais lentos em comparação com as técnicas de hoje.
Na década de 2010, a ascensão do deep learning e das Redes Neurais Convolucionais (CNNs) trouxe uma grande mudança na detecção de objetos. As CNNs tornaram possível para os computadores aprenderem automaticamente características importantes de grandes quantidades de dados, o que tornou a detecção muito mais precisa.
Os primeiros modelos como R-CNN (Redes Neurais Convolucionais Baseadas em Regiões) foram uma grande melhoria na precisão, ajudando a identificar objetos com mais precisão do que os métodos mais antigos.
No entanto, esses modelos eram lentos porque processavam imagens em vários estágios, tornando-os impraticáveis para aplicações em tempo real em áreas como carros autônomos ou videovigilância.
Com foco em acelerar as coisas, modelos mais eficientes foram desenvolvidos. Modelos como Fast R-CNN e Faster R-CNN ajudaram refinando como as regiões de interesse eram escolhidas e reduzindo o número de etapas necessárias para a detecção. Embora isso tenha tornado a detecção de objetos mais rápida, ainda não era rápido o suficiente para muitas aplicações do mundo real que precisavam de resultados instantâneos. A crescente demanda por detecção em tempo real impulsionou o desenvolvimento de soluções ainda mais rápidas e eficientes que pudessem equilibrar velocidade e precisão.

YOLO é um modelo de deteção de objectos que redefiniu a visão por computador ao permitir a deteção em tempo real de vários objectos em imagens e vídeos, tornando-o único em relação aos métodos de deteção anteriores. Em vez de analisar cada objeto detectado individualmente, a arquitetura doYOLO trata a deteção de objectos como uma tarefa única, prevendo a localização e a classe dos objectos de uma só vez utilizando CNNs.
O modelo funciona dividindo uma imagem em uma grade, com cada parte responsável por detectar objetos em sua respectiva área. Ele faz múltiplas previsões para cada seção e filtra os resultados menos confiantes, mantendo apenas os precisos.

A introdução do YOLO nas aplicações de visão por computador tornou a deteção de objectos muito mais rápida e eficiente do que os modelos anteriores. Devido à sua velocidade e precisão, YOLO tornou-se rapidamente uma escolha popular para soluções em tempo real em sectores como o fabrico, os cuidados de saúde e a robótica.
Outro ponto importante a salientar é que, uma vez que YOLO era de código aberto, os programadores e investigadores puderam melhorá-lo continuamente, conduzindo a versões ainda mais avançadas.
Os modelos YOLO têm vindo a ser constantemente melhorados ao longo do tempo, com base nos avanços de cada versão. Para além de um melhor desempenho, estas melhorias tornaram os modelos mais fáceis de utilizar por pessoas com diferentes níveis de experiência técnica.
Por exemplo, quando Ultralytics YOLOv5 foi introduzido, a implantação de modelos ficou mais simples com o PyTorchpermitindo a um maior número de utilizadores trabalhar com IA avançada. Reuniu precisão e facilidade de utilização, dando a mais pessoas a capacidade de implementar a deteção de objectos sem necessidade de serem especialistas em programação.
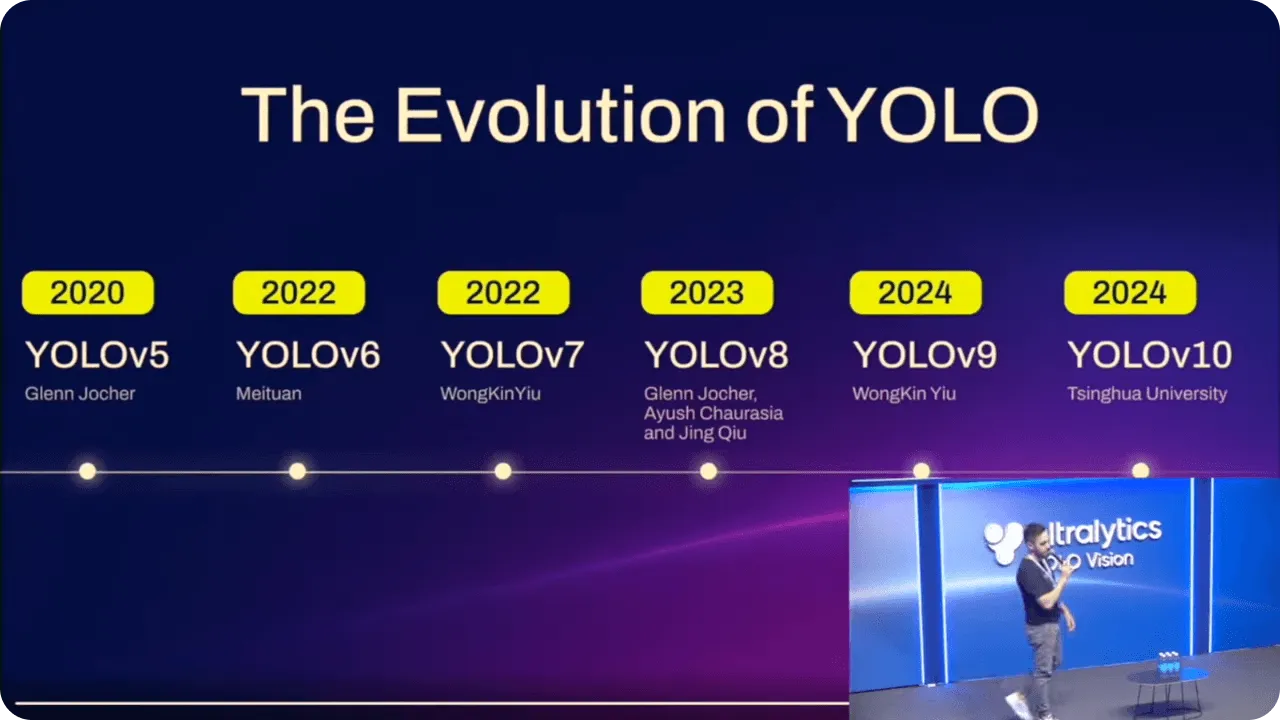
Ultralytics YOLOv8 continuou este progresso, adicionando suporte para tarefas como a segmentação de instâncias e tornando os modelos mais flexíveis. Tornou-se mais fácil utilizar YOLO tanto para aplicações básicas como para aplicações mais complexas, tornando-o útil numa série de cenários.
Com o modelo mais recente, Ultralytics YOLO11foram efectuadas mais optimizações. Ao reduzir o número de parâmetros e ao mesmo tempo melhorar a precisão, é agora mais eficiente para tarefas em tempo real. Quer seja um programador experiente ou um novato em IA, YOLO11 oferece uma abordagem avançada à deteção de objectos que é facilmente acessível.
YOLO11, lançado no evento híbrido anual da Ultralytics, YOLO Vision 2024 (YV24), suporta as mesmas tarefas de visão computacional que YOLOv8, como a deteção de objectos, a segmentação de instâncias, a classificação de imagens e a estimativa de pose. Assim, os utilizadores podem mudar facilmente para este novo modelo sem terem de ajustar os seus fluxos de trabalho. Além disso, a arquitetura actualizada do YOLO11torna as previsões ainda mais precisas. De facto, o YOLO11m atinge uma precisão média superiormAP) no conjunto de dadosCOCO com menos 22% de parâmetros do que YOLOv8m.
YOLO11 foi também concebido para funcionar eficientemente numa série de plataformas, desde smartphones e outros dispositivos periféricos a sistemas de nuvem mais potentes. Esta flexibilidade garante um desempenho suave em diferentes configurações de hardware para aplicações em tempo real. Para além disso, YOLO11 é mais rápido e mais eficiente, reduzindo os custos computacionais e acelerando os tempos de inferência. Quer esteja a utilizar o pacoteUltralytics Python ou o Ultralytics HUB sem código, é fácil integrar YOLO11 nos seus fluxos de trabalho existentes.
O impacto da deteção avançada de objectos nas aplicações em tempo real e na IA de ponta já se faz sentir em todas as indústrias. À medida que sectores como o petróleo e o gás, os cuidados de saúde e o retalho dependem cada vez mais da IA, a procura de uma deteção de objectos rápida e precisa continua a aumentar. YOLO11 tem como objetivo responder a esta procura, permitindo uma deteção de elevado desempenho, mesmo em dispositivos com poder de computação limitado.
À medida que a IA de ponta cresce, é provável que os modelos de deteção de objectos como o YOLO11 se tornem ainda mais essenciais para a tomada de decisões em tempo real em ambientes onde a velocidade e a precisão são fundamentais. Com melhorias contínuas no design e na adaptabilidade, o futuro da deteção de objectos parece destinado a trazer ainda mais inovações numa variedade de aplicações.
A deteção de objectos percorreu um longo caminho, evoluindo de métodos simples para as técnicas avançadas de aprendizagem profunda que vemos hoje. Os modelos YOLO têm estado no centro deste progresso, proporcionando uma deteção em tempo real mais rápida e precisa em diferentes sectores. YOLO11 baseia-se neste legado, melhorando a eficiência, reduzindo os custos computacionais e aumentando a precisão, tornando-o uma escolha fiável para uma variedade de aplicações em tempo real. Com os avanços contínuos em IA e visão computacional, o futuro da deteção de objectos parece brilhante, com espaço para ainda mais melhorias em termos de velocidade, precisão e adaptabilidade.
Curioso sobre IA? Mantenha-se conectado com a nossa comunidade para continuar aprendendo! Confira nosso repositório GitHub para descobrir como estamos usando a IA para criar soluções inovadoras em setores como manufatura e saúde. 🚀
.webp)

.webp)