



Недавно выпущенная Llama 3 от Meta вызвала большой ажиотаж в AI-сообществе. Давайте узнаем больше о Llama 3 — последней разработке Meta AI.

Недавно выпущенная Llama 3 от Meta вызвала большой ажиотаж в AI-сообществе. Давайте узнаем больше о Llama 3 — последней разработке Meta AI.
Когда мы подводили итоги инноваций в области искусственного интеллекта (AI) первого квартала 2024 года, мы увидели, что LLM, или большие языковые модели, выпускались разными организациями направо и налево. Продолжая эту тенденцию, 18 апреля 2024 года Meta выпустила Llama 3, LLM нового поколения с открытым исходным кодом и передовыми возможностями.
Вы можете подумать: Это всего лишь еще одна LLM. Почему AI-сообщество так взволновано этим?
Хотя вы можете точно настроить такие модели, как GPT-3 или Gemini, для получения индивидуальных ответов, они не предлагают полной прозрачности в отношении их внутренней работы, такой как данные обучения, параметры модели или алгоритмы. В отличие от них, Llama 3 от Meta более прозрачна, ее архитектура и веса доступны для загрузки. Для AI-сообщества это означает большую свободу для экспериментов.
В этой статье мы узнаем, что может делать Llama 3, как она появилась и какое влияние она оказывает на область AI. Давайте сразу перейдем к делу!
Прежде чем мы углубимся в Llama 3, давайте посмотрим на ее более ранние версии.
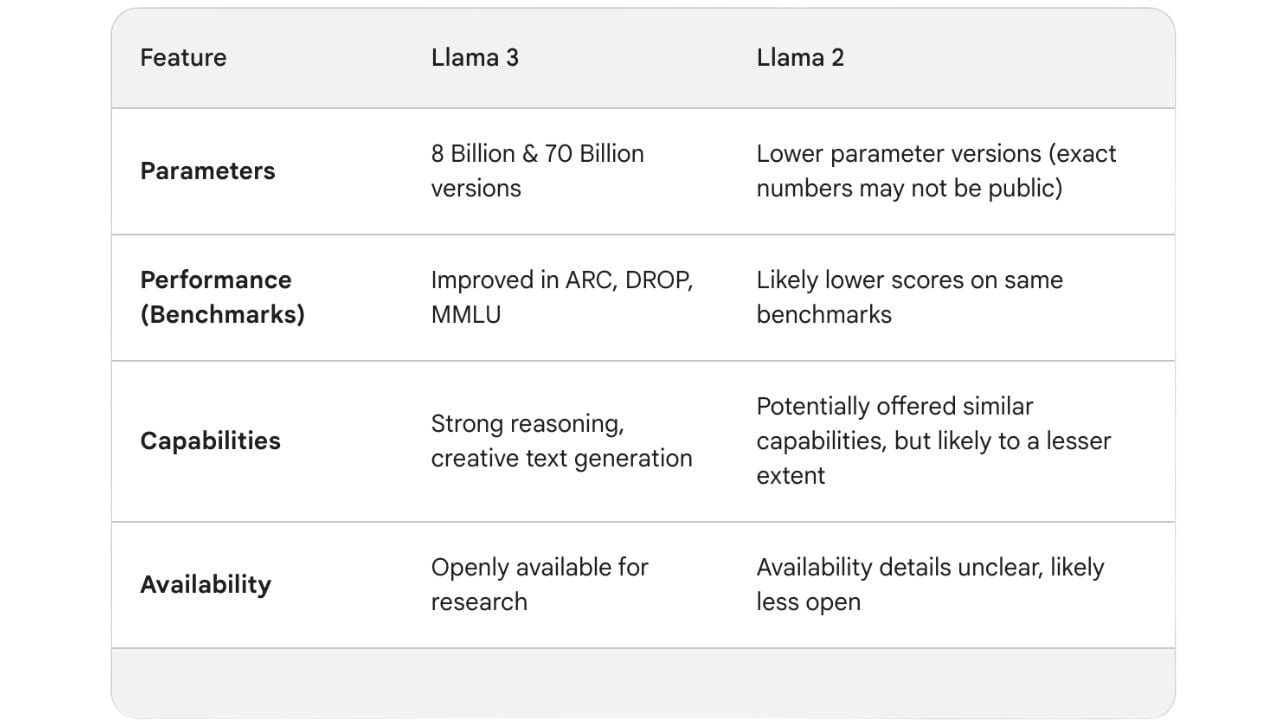
Meta запустила Llama 1 в феврале 2023 года, которая поставлялась в четырех вариантах с параметрами от 7 миллиардов до 64 миллиардов. В машинном обучении «параметры» относятся к элементам модели, которые изучаются на основе данных обучения. Из-за меньшего количества параметров Llama 1 иногда испытывала трудности с нюансированным пониманием и давала непоследовательные ответы.
Вскоре после Llama 1 Meta запустила Llama 2 в июле 2023 года. Она была обучена на 2 триллионах токенов. Токен представляет собой часть текста, например слово или часть слова, используемую в качестве основной единицы данных для обработки в модели. Модель также включала в себя такие улучшения, как удвоенное контекстное окно в 4096 токенов для понимания более длинных отрывков и более 1 миллиона человеческих аннотаций для уменьшения количества ошибок. Несмотря на эти улучшения, Llama 2 все еще требовала большой вычислительной мощности, что Meta стремилась исправить с помощью Llama 3.
Llama 3 поставляется с четырьмя вариантами, которые были обучены на ошеломляющих 15 триллионах токенов. Более 5% этих данных обучения (около 800 миллионов токенов) представляли собой данные на 30 различных языках. Все варианты Llama 3 могут работать на различных типах потребительского оборудования и имеют длину контекста 8 тысяч токенов.

Варианты модели бывают двух размеров: 8B и 70B, что означает 8 миллиардов и 70 миллиардов параметров соответственно. Существуют также две версии: базовая и instruct. «Базовая» относится к стандартной предварительно обученной версии. «Instruct» — это точно настроенная версия, оптимизированная для конкретных приложений или доменов посредством дополнительного обучения на релевантных данных.
Вот варианты модели Llama 3:
Как и в случае с другими достижениями Meta AI, были приняты строгие меры контроля качества для поддержания целостности данных и минимизации предвзятости при разработке Llama 3. Таким образом, конечный продукт представляет собой мощную модель, созданную ответственным образом.
Архитектура модели Llama 3 выделяется своей ориентацией на эффективность и производительность в задачах обработки естественного языка. Построенная на основе фреймворка Transformer, она делает акцент на вычислительной эффективности, особенно во время генерации текста, за счет использования архитектуры только с декодером.
Модель генерирует выходные данные, основываясь исключительно на предыдущем контексте, без кодировщика для кодирования входных данных, что значительно ускоряет ее работу.

В моделях Llama 3 используется токенизатор со словарем из 128 тысяч токенов. Более обширный словарь означает, что модели могут лучше понимать и обрабатывать текст. Кроме того, в моделях теперь используется grouped query attention (GQA) для повышения эффективности inference. GQA — это метод, который можно представить как прожектор, помогающий моделям фокусироваться на соответствующих частях входных данных для более быстрого и точного создания ответов.
Вот еще несколько интересных деталей об архитектуре модели Llama 3:
Для обучения самых больших моделей Llama 3 были объединены три типа параллелизации: параллелизация данных, параллелизация модели и конвейерная параллелизация.
Распараллеливание данных распределяет обучающие данные между несколькими GPU, а распараллеливание модели разделяет архитектуру модели, чтобы использовать вычислительную мощность каждого GPU. Конвейерное распараллеливание делит процесс обучения на последовательные этапы, оптимизируя вычисления и коммуникации.
Наиболее эффективная реализация достигла значительной производительности вычислений, превышающей 400 TFLOPS на GPU при одновременном обучении на 16 000 GPU. Обучение проводилось на двух специально созданных кластерах GPU , каждый из которых состоял из 24 000 GPU. Эта значительная вычислительная инфраструктура обеспечила необходимую мощность для эффективного обучения крупномасштабных моделей Llama 3.
Чтобы максимально увеличить время работы GPU , был разработан новый передовой стек обучения, автоматизирующий обнаружение, обработку и обслуживание ошибок. Механизмы надежности и обнаружения аппаратного обеспечения были значительно улучшены, чтобы снизить риски тихого повреждения данных. Также были разработаны новые масштабируемые системы хранения данных для снижения накладных расходов на создание контрольных точек и откат.
Эти улучшения привели к общей эффективности времени обучения более 95%. В совокупности они увеличили эффективность обучения Llama 3 примерно в три раза по сравнению с Llama 2. Эта эффективность не просто впечатляет; она открывает новые возможности для методов обучения ИИ.
Поскольку Llama 3 имеет открытый исходный код, исследователи и студенты могут изучать ее код, проводить эксперименты и участвовать в обсуждениях этических проблем и предвзятости. Однако Llama 3 предназначена не только для академической среды. Она производит фурор и в практических приложениях. Она становится основой Meta AI Chat Interface, легко интегрируясь в такие платформы, как Facebook, Instagram, WhatsApp и Messenger. С помощью Meta AI пользователи могут участвовать в разговорах на естественном языке, получать доступ к персонализированным рекомендациям, выполнять задачи и легко общаться с другими.

Llama 3 демонстрирует исключительные результаты по нескольким ключевым бенчмаркам, оценивающим сложное понимание языка и способности к рассуждению. Вот некоторые из бенчмарков, которые проверяют различные аспекты возможностей Llama 3:
Выдающиеся результаты Llama 3 в этих тестах заметно выделяют ее на фоне таких конкурентов, как Gemma 7B от Google, Mistral 7B от Mistral и Claude 3 Sonnet от Anthropic. Согласно опубликованной статистике, особенно модель 70B, Llama 3 превосходит эти модели во всех вышеперечисленных бенчмарках.

Meta расширяет охват Llama 3, делая ее доступной на различных платформах как для обычных пользователей, так и для разработчиков. Для повседневных пользователей Llama 3 интегрирована в популярные платформы Meta, такие как WhatsApp, Instagram, Facebook и Messenger. Пользователи могут получить доступ к расширенным функциям, таким как поиск в реальном времени и возможность создания креативного контента непосредственно в этих приложениях.
Llama 3 также интегрируется в носимые технологии, такие как умные очки Ray-Ban Meta и VR-гарнитура Meta Quest, для интерактивного взаимодействия.
Llama 3 доступна на различных платформах для разработчиков, включая AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM и Snowflake. Вы также можете получить доступ к этим моделям непосредственно из Meta. Широкий спектр возможностей позволяет разработчикам легко интегрировать эти передовые возможности моделей ИИ в свои проекты, независимо от того, предпочитают ли они работать напрямую с Meta или через другие популярные платформы.
Достижения в области машинного обучения продолжают преобразовывать то, как мы взаимодействуем с технологиями каждый день. Meta's Llama 3 показывает, что LLM — это больше, чем просто генерация текста. LLM решают сложные проблемы и обрабатывают несколько языков. В целом, Llama 3 делает AI более адаптивным и доступным, чем когда-либо. В будущем запланированные обновления для Llama 3 обещают еще больше возможностей, таких как обработка нескольких моделей и понимание более крупных контекстов.
Посетите наш репозиторий GitHub и присоединяйтесь к нашему сообществу, чтобы узнать больше об AI. Посетите страницы наших решений, чтобы увидеть, как AI применяется в таких областях, как производство и сельское хозяйство.



{kind=link}
{kind=link}
{kind=link}