



Узнайте, как с помощью Mask R-CNN можно точно segment объекты на изображениях и видео в различных сферах применения.

Узнайте, как с помощью Mask R-CNN можно точно segment объекты на изображениях и видео в различных сферах применения.
Инновации, такие как роботы на складах, самоуправляемые автомобили, безопасно передвигающиеся по оживленным улицам, дроны, проверяющие посевы, и системы искусственного интеллекта, проверяющие продукцию на заводах, становятся все более распространенными по мере увеличения внедрения ИИ. Ключевой технологией, лежащей в основе этих инноваций, является компьютерное зрение — раздел ИИ, который позволяет машинам понимать и интерпретировать визуальные данные.
Например, обнаружение объектов — это задача компьютерного зрения, которая помогает идентифицировать и находить объекты на изображениях с помощью ограничивающих рамок. Хотя ограничивающие рамки предоставляют полезную информацию, они дают лишь приблизительную оценку положения объекта и не могут зафиксировать его точную форму или границы. Это делает их менее эффективными в приложениях, требующих точной идентификации.
Чтобы решить эту проблему, исследователи разработали модели сегментации, которые фиксируют точные контуры объектов, предоставляя детали на уровне пикселей для более точного обнаружения и анализа.
Mask R-CNN - одна из таких моделей. Представленная в 2017 году компанией Facebook AI Research (FAIR), она является развитием более ранних моделей, таких как R-CNN, Fast R-CNN и Faster R-CNN. Являясь важной вехой в истории компьютерного зрения, Mask R-CNN проложила путь для более продвинутых моделей, таких как Ultralytics YOLO11.
В этой статье мы рассмотрим, что такое Mask R-CNN, как он работает, его применение и какие усовершенствования появились после него, приведя к YOLO11.
Mask R-CNN, что расшифровывается как Mask Region-based Convolutional Neural Network (масочная региональная сверточная нейронная сеть), — это модель глубокого обучения, предназначенная для задач компьютерного зрения, таких как обнаружение объектов и сегментация экземпляров.
Сегментация экземпляров выходит за рамки традиционного обнаружения объектов, не только идентифицируя объекты на изображении, но и точно очерчивая каждый из них. Она присваивает уникальную метку каждому обнаруженному объекту и фиксирует его точную форму на уровне пикселей. Этот детальный подход позволяет четко различать перекрывающиеся объекты и точно обрабатывать сложные формы.
Mask R-CNN основана на Faster R-CNN, которая обнаруживает и маркирует объекты, но не определяет их точные формы. Mask R-CNN улучшает это, определяя точные пиксели, составляющие каждый объект, что позволяет проводить гораздо более детальный и точный анализ изображений.

Mask R-CNN использует пошаговый подход для точного detect и segment объектов. Он начинается с извлечения ключевых признаков с помощью глубокой нейронной сети (многослойной модели, которая обучается на основе данных), затем определяет потенциальные области объектов с помощью сети предложения областей (компонента, который предлагает вероятные области объектов) и, наконец, уточняет эти области путем создания подробных масок сегментации (точных контуров объектов), которые передают точную форму каждого объекта.
Далее мы рассмотрим каждый шаг, чтобы лучше понять, как работает Mask R-CNN.
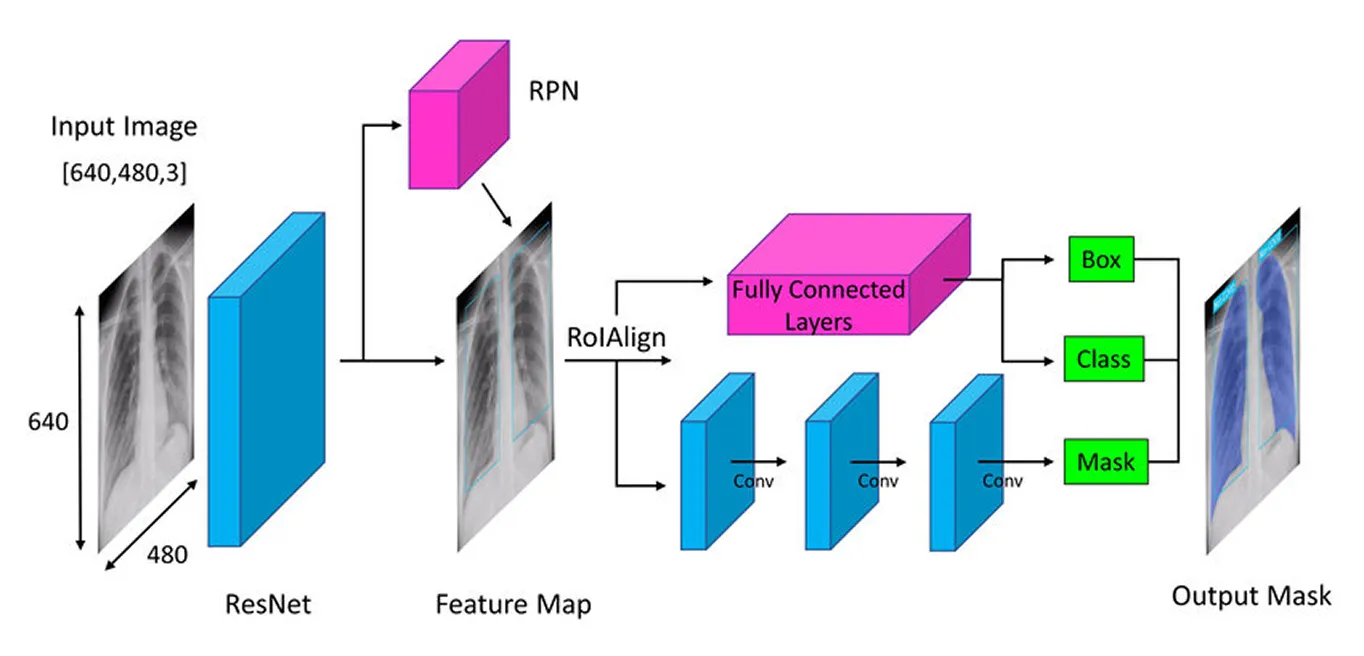
Первый шаг в архитектуре Mask R-CNN — разбить изображение на ключевые части, чтобы модель могла понять, что в нем находится. Представьте, что вы смотрите на фотографию и естественным образом замечаете такие детали, как формы, цвета и края. Модель делает нечто подобное, используя глубокую нейронную сеть, называемую "backbone" (часто ResNet-50 или ResNet-101), которая действует как ее глаза, сканируя изображение и улавливая ключевые детали.
Поскольку объекты на изображениях могут быть очень маленькими или очень большими, Mask R-CNN использует Feature Pyramid Network. Это похоже на наличие разных увеличительных стекол, которые позволяют модели видеть как мелкие детали, так и общую картину, гарантируя, что объекты всех размеров будут замечены.
После того как эти важные характеристики извлечены, модель переходит к определению местоположения потенциальных объектов на изображении, подготавливая почву для дальнейшего анализа.
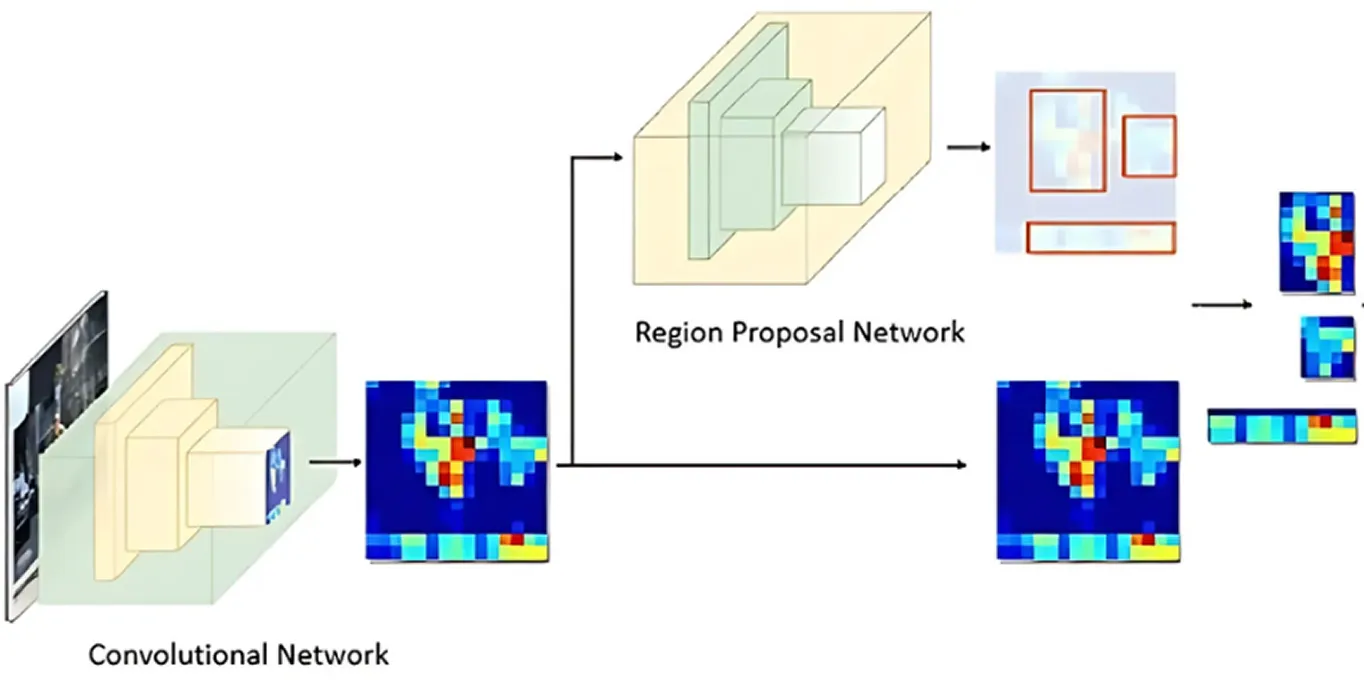
После того как изображение было обработано для выделения ключевых признаков, в дело вступает Region Proposal Network. Эта часть модели рассматривает изображение и предлагает области, которые, вероятно, содержат объекты.
Это достигается путем генерации нескольких возможных местоположений объектов, называемых якорями. Затем сеть оценивает эти якоря и выбирает наиболее перспективные для дальнейшего анализа. Таким образом, модель фокусируется только на областях, которые с наибольшей вероятностью представляют интерес, а не проверяет каждое место на изображении.
После определения ключевых областей следующим шагом является уточнение деталей, извлеченных из этих регионов. Более ранние модели использовали метод, называемый ROI Pooling (объединение областей интереса), для захвата признаков из каждой области, но этот метод иногда приводил к небольшим смещениям при изменении размера областей, что делало его менее эффективным, особенно для небольших или перекрывающихся объектов.
Mask R-CNN улучшает это за счет использования техники, называемой ROI Align (выравнивание области интереса). Вместо округления координат, как это делает ROI Pooling, ROI Align использует билинейную интерполяцию для более точной оценки значений пикселей. Билинейная интерполяция — это метод, который вычисляет новое значение пикселя путем усреднения значений четырех ближайших соседей, что создает более плавные переходы. Это обеспечивает правильное выравнивание признаков с исходным изображением, что приводит к более точному обнаружению и сегментации объектов.
Например, в футбольном матче двух игроков, стоящих близко друг к другу, можно ошибочно принять за одного, потому что их ограничивающие рамки перекрываются. ROI Align помогает разделить их, сохраняя их формы отчетливыми.
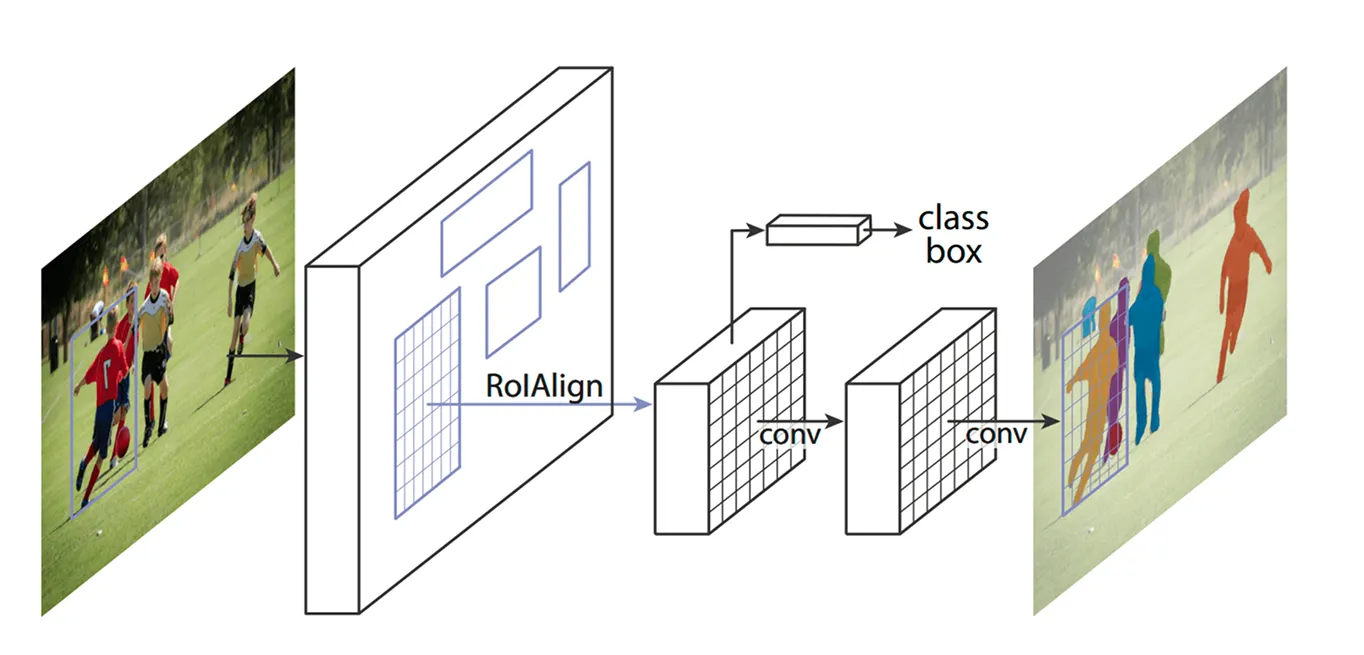
После того как ROI Align обработает изображение, следующим шагом будет classify объектов и точная настройка их местоположения. Модель рассматривает каждую выделенную область и решает, какой объект в ней находится. Она присваивает различным категориям оценку вероятности и выбирает наилучшее соответствие.
В то же время он корректирует ограничивающие рамки, чтобы лучше соответствовать объектам. Первоначальные рамки могут быть расположены не идеально, поэтому это помогает повысить точность, гарантируя, что каждая рамка плотно окружает обнаруженный объект.
Наконец, Mask R-CNN делает дополнительный шаг: он генерирует подробную маску сегментации для каждого объекта параллельно.
Когда эта модель появилась, она вызвала большой ажиотаж в сообществе ИИ и вскоре стала использоваться в различных приложениях. Способность detect и segment объекты в режиме реального времени сделала ее революционной для различных отраслей.
Например, отслеживание исчезающих животных в дикой природе - сложная задача. Многие виды перемещаются по густым лесам, поэтому природоохранникам сложно track ними уследить. Традиционные методы используют фотоловушки, беспилотники и спутниковые снимки, но сортировка всех этих данных вручную отнимает много времени. Ошибки в идентификации и пропущенные встречи могут замедлить работу по охране природы.
Распознавая уникальные особенности, такие как полосы тигра, пятна жирафа или форма ушей слона, Mask R-CNN может с большей точностью detect и segment животных на изображениях и видео. Даже если животные частично скрыты деревьями или стоят близко друг к другу, модель может разделить их и идентифицировать каждого в отдельности, что делает мониторинг дикой природы более быстрым и надежным.

Несмотря на свою историческую значимость в обнаружении и сегментации объектов, Mask R-CNN также имеет некоторые ключевые недостатки. Вот некоторые проблемы, связанные с Mask R-CNN:
Масочные R-CNN отлично подходили для задач сегментации, но многие отрасли стремились внедрить компьютерное зрение, отдавая предпочтение скорости и производительности в реальном времени. Это требование привело исследователей к разработке одноступенчатых моделей, которые detect объекты за один проход, значительно повышая эффективность.
В отличие от многоступенчатого процесса Mask R-CNN, одноступенчатые модели компьютерного зрения, такие как YOLO (You Only Look Once), ориентированы на задачи компьютерного зрения в реальном времени. Вместо того чтобы отдельно заниматься обнаружением и сегментацией, модели YOLO могут анализировать изображение за один раз. Это делает их идеальными для таких приложений, как автономное вождение, здравоохранение, производство и робототехника, где быстрое принятие решений имеет решающее значение.
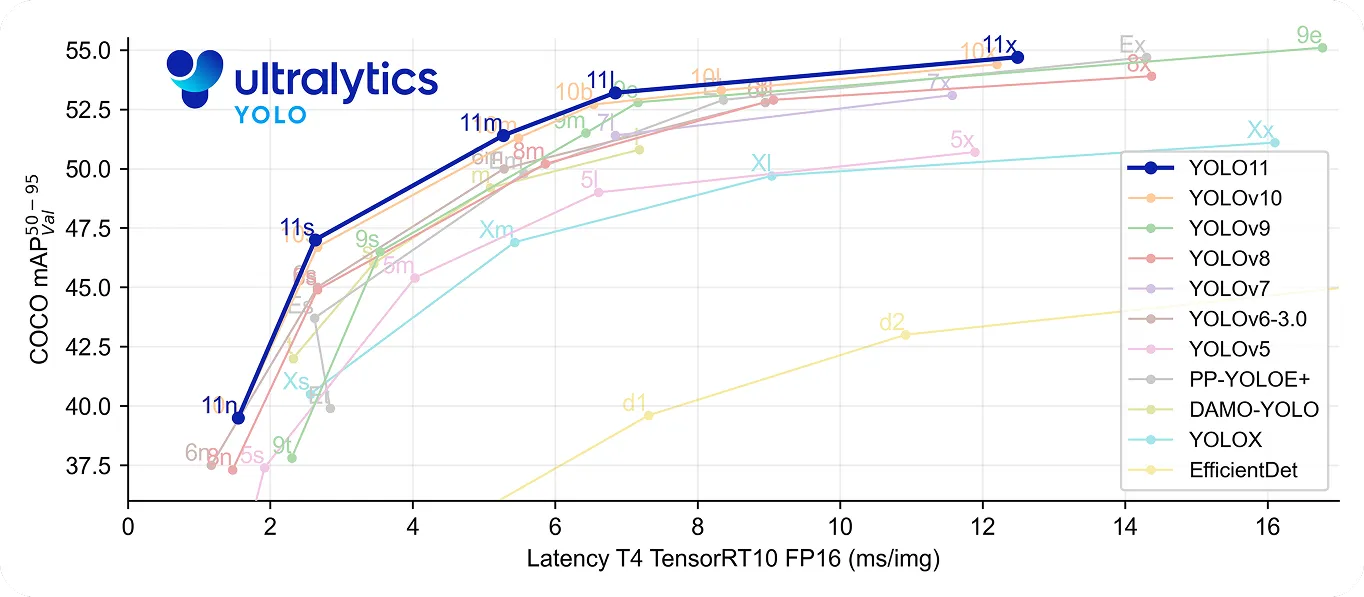
В частности, YOLO11 делает еще один шаг вперед, будучи одновременно быстрым и точным. Он использует на 22 % меньше параметров, чем YOLOv8m , но при этом достигает более высокой средней точностиmAP) на наборе данных COCO , что означает более точное обнаружение объектов. Повышенная скорость обработки данных делает его отличным выбором для приложений реального времени, где важна каждая миллисекунда.
Оглядываясь на историю компьютерного зрения, Mask R-CNN признана крупным прорывом в обнаружении и сегментации объектов. Она обеспечивает очень точные результаты даже в сложных условиях благодаря детальному многоэтапному процессу.
Однако этот же процесс делает его более медленным по сравнению с моделями реального времени, такими как YOLO. Поскольку потребность в скорости и эффективности растет, во многих приложениях теперь используются одноэтапные модели, такие как Ultralytics YOLO11, которые обеспечивают быстрое и точное обнаружение объектов. Хотя R-CNN Маска важна для понимания эволюции компьютерного зрения, тенденция к созданию решений реального времени подчеркивает растущий спрос на более быстрые и эффективные решения для компьютерного зрения.
Присоединяйтесь к нашему растущему сообществу! Изучите наш репозиторий на GitHub, чтобы узнать больше об ИИ. Готовы начать свои собственные проекты в области компьютерного зрения? Ознакомьтесь с нашими вариантами лицензирования. Откройте для себя ИИ в сельском хозяйстве и Vision AI в здравоохранении, посетив страницы наших решений!


