



Узнайте о RCNN и его влиянии на обнаружение объектов. Мы рассмотрим ее ключевые компоненты, области применения и роль в развитии таких методов, как Fast RCNN и YOLO.

Узнайте о RCNN и его влиянии на обнаружение объектов. Мы рассмотрим ее ключевые компоненты, области применения и роль в развитии таких методов, как Fast RCNN и YOLO.
Обнаружение объектов - это задача компьютерного зрения, которая позволяет распознавать и находить объекты на изображениях или видео для таких приложений, как автономное вождение, наблюдение и медицинская визуализация. Ранние методы обнаружения объектов, такие как детектор Виолы-Джонса и гистограмма ориентированных градиентов (HOG) с использованием машин с опорными векторами (SVM), основывались на ручном создании признаков и скользящих окнах. Эти методы часто не справлялись с точным detect объектов в сложных сценах с множеством объектов различных форм и размеров.
Конволюционные нейронные сети на основе регионов (R-CNN) изменили наши представления об обнаружении объектов. Это важная веха в истории компьютерного зрения. Чтобы понять, как такие модели, как YOLOv8 мы должны сначала понять, как появились такие модели, как R-CNN.
Архитектура модели R-CNN, созданная Россом Гиршиком и его командой, генерирует предложения регионов, извлекает признаки с помощью предварительно обученной сверточной нейронной сети (CNN), классифицирует объекты и уточняет ограничивающие рамки. Хотя это может показаться сложным, к концу этой статьи вы получите четкое представление о том, как работает R-CNN и почему она так эффективна. Давайте посмотрим!
Процесс обнаружения объектов в модели R-CNN включает в себя три основных этапа: генерация предложений регионов, извлечение признаков и классификация объектов с одновременным уточнением их ограничивающих рамок. Давайте рассмотрим каждый этап.
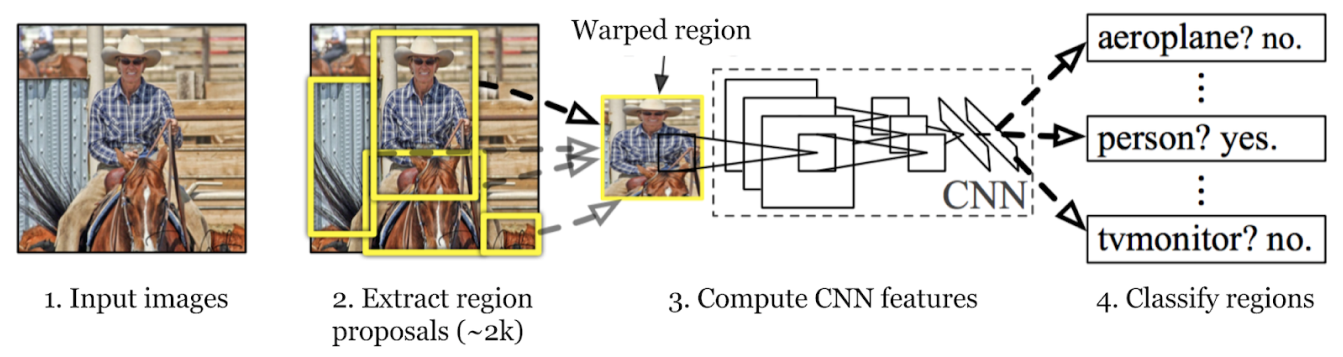
На первом этапе модель R-CNN сканирует изображение для создания множества предложений регионов. Предложения регионов — это потенциальные области, которые могут содержать объекты. Такие методы, как Selective Search, используются для анализа различных аспектов изображения, таких как цвет, текстура и форма, разделяя его на различные части. Selective Search начинается с разделения изображения на более мелкие части, а затем объединяет похожие, чтобы сформировать более крупные области интереса. Этот процесс продолжается до тех пор, пока не будет сгенерировано около 2000 предложений регионов.
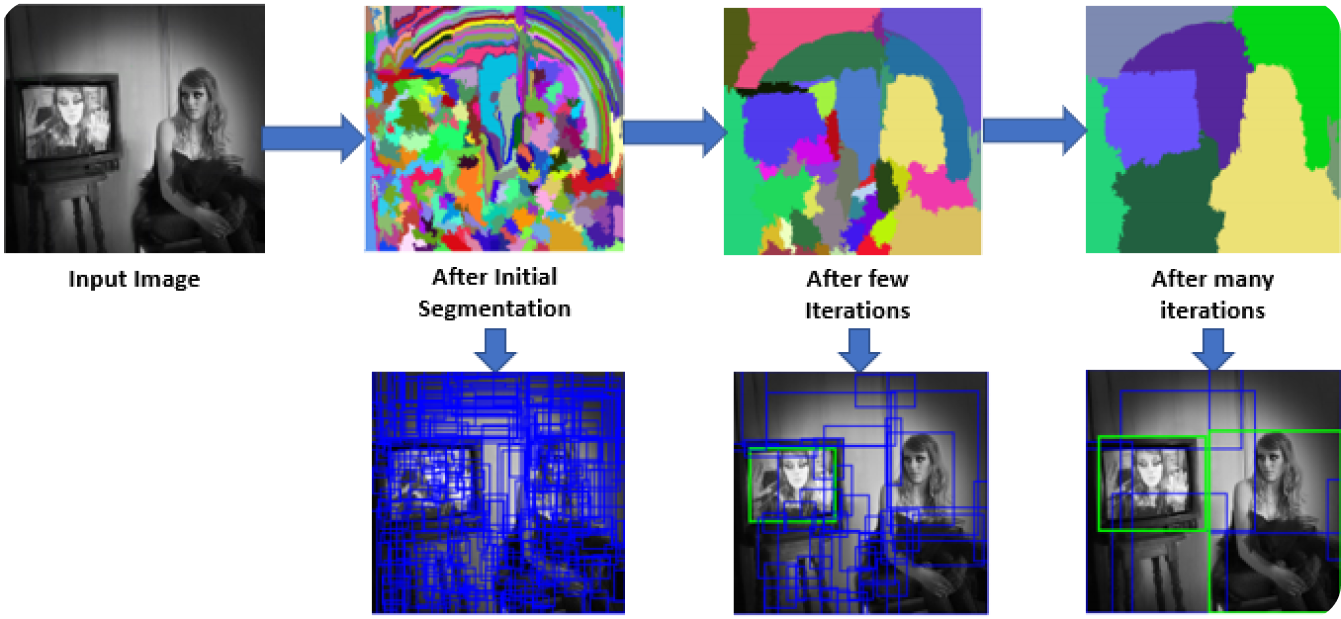
Эти предложения регионов помогают определить все возможные места, где может находиться объект. На следующих этапах модель может эффективно обрабатывать наиболее релевантные области, фокусируясь на этих конкретных областях, а не на всем изображении. Использование предложений регионов обеспечивает баланс между тщательностью и вычислительной эффективностью.
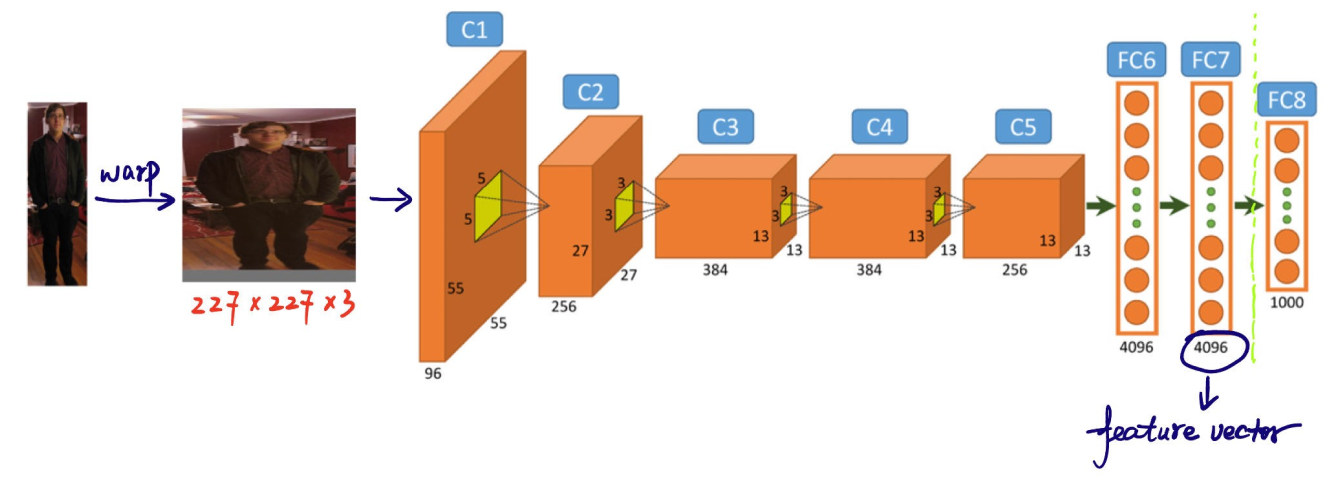
Следующий шаг в процессе обнаружения объектов модели R-CNN — извлечение признаков из предложенных регионов. Каждый предложенный регион изменяется до согласованного размера, который ожидает CNN (например, 224x224 пикселя). Изменение размера помогает CNN эффективно обрабатывать каждое предложение. Перед деформацией размер каждого предложенного региона немного увеличивается, чтобы включить 16 пикселей дополнительного контекста вокруг региона, чтобы предоставить больше окружающей информации для лучшего извлечения признаков.
После изменения размера эти предложения регионов поступают в CNN, например AlexNet, который обычно предварительно обучен на большом наборе данных, например ImageNet. CNN обрабатывает каждый регион для извлечения высокоразмерных векторов признаков, которые фиксируют важные детали, такие как края, текстуры и узоры. Эти векторы признаков сгущают важную информацию из регионов. Они преобразуют необработанные данные изображения в формат, который модель может использовать для дальнейшего анализа. Точная классификация и определение местоположения объектов на следующих этапах зависят от этого важнейшего преобразования визуальной информации в осмысленные данные.
Третий шаг - classify объектов в этих регионах. Это означает определение категории или класса каждого объекта, найденного в предложениях. Затем извлеченные векторы признаков пропускаются через классификатор машинного обучения.
В случае с R-CNN для этой цели обычно используются машины опорных векторов (SVM). Каждый SVM обучен распознавать определенный класс объектов, анализируя векторы признаков и решая, содержит ли конкретная область экземпляр этого класса. По сути, для каждой категории объектов существует специальный классификатор, проверяющий каждое предложение региона на наличие этого конкретного объекта.
Во время обучения классификаторам предоставляются размеченные данные с положительными и отрицательными примерами:
Классификаторы учатся различать эти образцы. Регрессия ограничивающих рамок дополнительно уточняет положение и размер обнаруженных объектов, корректируя первоначально предложенные ограничивающие рамки, чтобы они лучше соответствовали фактическим границам объекта. Модель R-CNN может идентифицировать и точно определять местоположение объектов, объединяя классификацию и регрессию ограничивающих рамок.
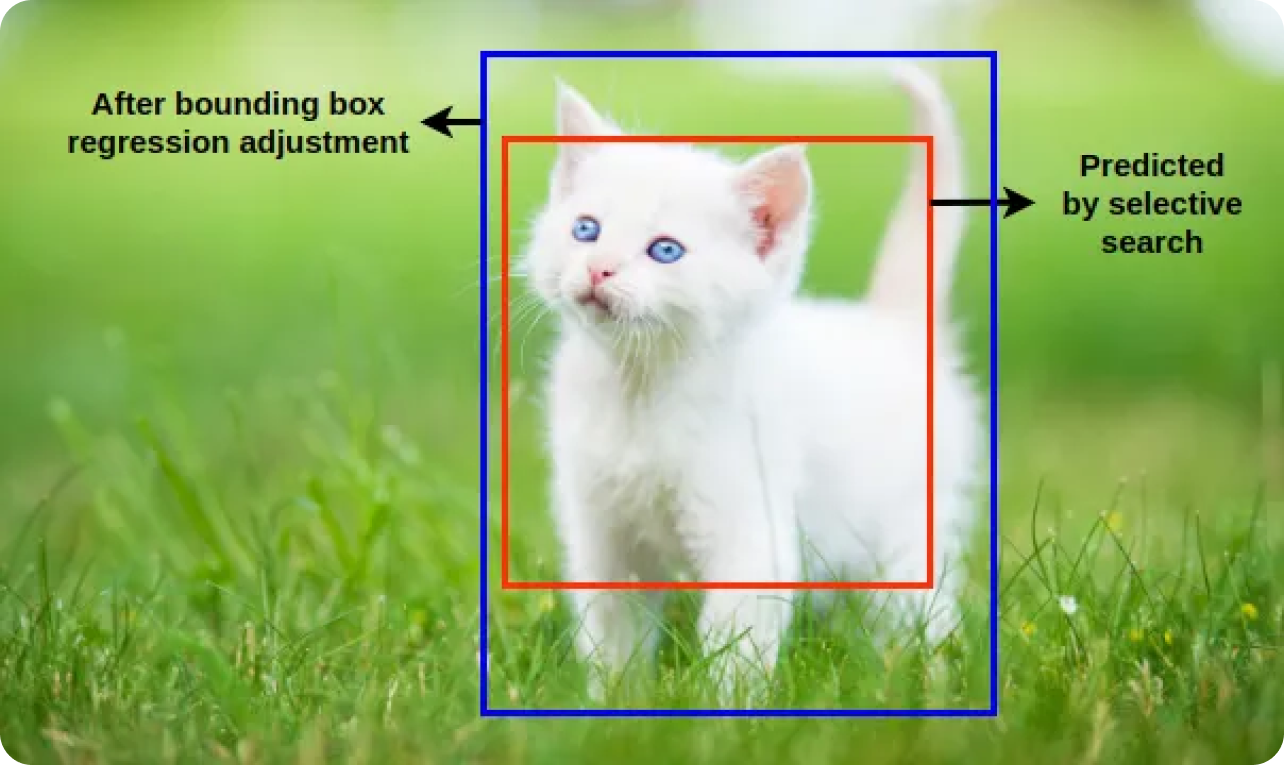
После этапов классификации и регрессии ограничительных рамок модель часто генерирует несколько перекрывающихся ограничительных рамок для одного и того же объекта. Для уточнения этих обнаружений применяется метод немаксимального подавленияNMS), в результате которого сохраняются наиболее точные рамки. Применяя NMS , модель устраняет избыточные и перекрывающиеся рамки и сохраняет только наиболее достоверные обнаружения.
NMS работает, оценивая баллы доверия (показывающие, насколько вероятно, что обнаруженный объект действительно присутствует) всех ограничивающих боксов и подавляя те, которые значительно перекрывают боксы с более высокими баллами.

Вот описание этапов работы с NMS:
Модель R-CNN обнаруживает объекты путем генерации предложений регионов, извлечения признаков с помощью CNN, классификации объектов и уточнения их положения с помощью регрессии ограничительных рамок, а также с помощью немаксимального подавленияNMS), сохраняя только самые точные обнаружения.
R-CNN — знаковая модель в истории обнаружения объектов, поскольку она представила новый подход, который значительно улучшил точность и производительность. До R-CNN модели обнаружения объектов с трудом находили баланс между скоростью и точностью. Метод R-CNN, заключающийся в создании предложений регионов и использовании CNN для извлечения признаков, обеспечивает точную локализацию и идентификацию объектов на изображениях.
R-CNN проложила путь для таких моделей, как Fast R-CNN, Faster R-CNN и Mask R-CNN, которые еще больше повысили эффективность и точность. Благодаря сочетанию глубокого обучения с анализом на основе регионов, R-CNN установила новый стандарт в этой области и открыла возможности для различных реальных приложений.
Интересным примером использования R-CNN является медицинская визуализация. Модели R-CNN использовались для detect и classify различных типов опухолей, например опухолей мозга, на таких медицинских снимках, как МРТ и КТ. Использование модели R-CNN в медицинской визуализации повышает точность диагностики и помогает радиологам выявлять злокачественные опухоли на ранних стадиях. Способность R-CNN detect даже небольшие опухоли на ранних стадиях может существенно повлиять на лечение и прогноз таких заболеваний, как рак.
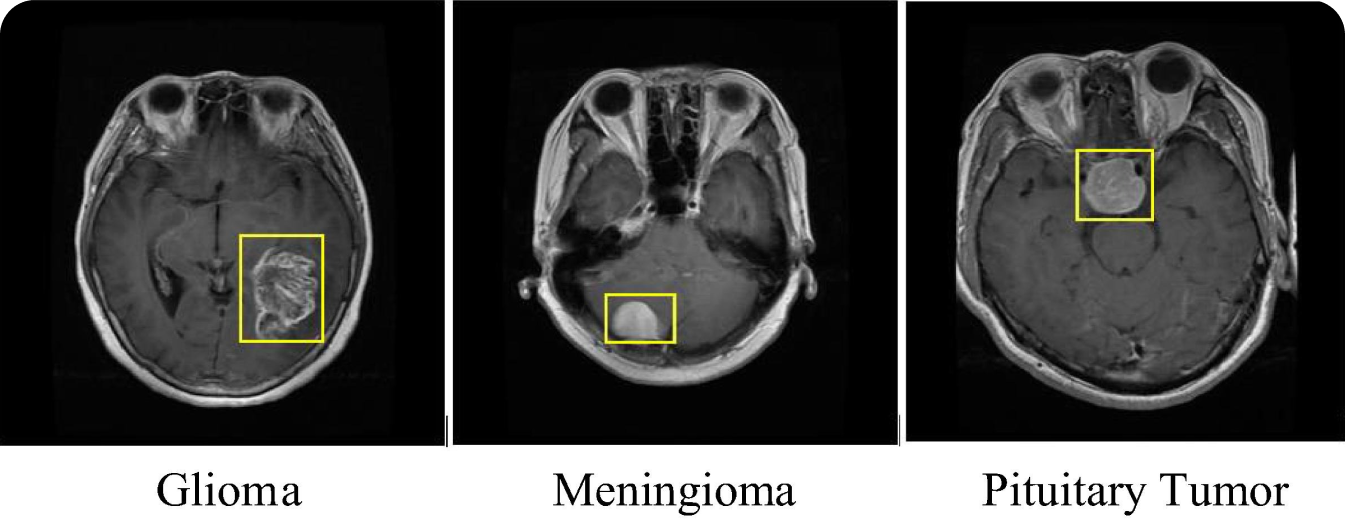
Модель R-CNN может применяться не только для обнаружения опухолей, но и для решения других задач медицинской визуализации. Например, она может выявлять переломы, detect заболевания сетчатки на снимках глаз и анализировать изображения легких на предмет таких заболеваний, как пневмония и COVID-19. Независимо от медицинской проблемы, раннее обнаружение может привести к улучшению состояния пациентов. Применяя точность R-CNN в выявлении и локализации аномалий, медицинские работ ники могут повысить надежность и скорость медицинской диагностики. Благодаря обнаружению объектов, упрощающему процесс диагностики, пациенты могут получить своевременные и точные планы лечения.
Несмотря на впечатляющие результаты, R-CNN имеет определенные недостатки, такие как высокая вычислительная сложность и большое время инференса. Эти недостатки делают модель R-CNN непригодной для приложений, работающих в режиме реального времени. Разделение предложений регионов и классификаций на отдельные этапы может привести к снижению эффективности.
С годами появилось множество моделей обнаружения объектов, которые решают эти проблемы. Fast R-CNN объединяет предложения регионов и извлечение признаков CNN в один этап, ускоряя процесс. Faster R-CNN представляет сеть предложений регионов (RPN) для оптимизации генерации предложений, а Mask R-CNN добавляет сегментацию на уровне пикселей для более детального обнаружения.

Примерно в то же время, что и Faster R-CNN, серия YOLO (You Only Look Once) начала продвигать обнаружение объектов в реальном времени. Модели YOLO предсказывают ограничительные рамки и вероятности классов за один проход по сети. Например, модель Ultralytics YOLOv8 предлагает повышенную точность и скорость, а также расширенные функции для многих задач компьютерного зрения.
RCNN изменил игру в компьютерном зрении, показав, как глубокое обучение может изменить обнаружение объектов. Его успех вдохновил множество новых идей в этой области. Несмотря на то, что новые модели, такие как Faster R-CNN и YOLO , уже исправили недостатки RCNN, ее вклад - это огромная веха, о которой важно помнить.
По мере продолжения исследований мы увидим еще более совершенные и быстрые модели обнаружения объектов. Эти достижения не только улучшат понимание мира машинами, но и приведут к прогрессу во многих отраслях. Будущее обнаружения объектов выглядит многообещающим!
Хотите узнать больше об искусственном интеллекте? Станьте частьюсообщества Ultralytics ! Изучите наш репозиторий GitHub, чтобы ознакомиться с нашими последними инновациями в области искусственного интеллекта. Ознакомьтесь с нашими решениями в области искусственного интеллекта для различных отраслей, таких как сельское хозяйство и производство. Присоединяйтесь к нам, чтобы учиться и развиваться!


