



استكشف كيف تعمل ابتكارات Edge AI وابتكارات NVIDIA مثل Jetson Triton TensorRT على تبسيط نشر تطبيقات الرؤية الحاسوبية.

استكشف كيف تعمل ابتكارات Edge AI وابتكارات NVIDIA مثل Jetson Triton TensorRT على تبسيط نشر تطبيقات الرؤية الحاسوبية.
بفضل التطورات الأخيرة في الرؤية الحاسوبية والذكاء الاصطناعي (AI)، فإن ما كان مجرد مجال بحثي يقود الآن تطبيقات مؤثرة في مجموعة واسعة من الصناعات. من السيارات ذاتية القيادة إلى التصوير الطبي والأمن، تحل أنظمة الرؤية الحاسوبية مشاكل حقيقية على نطاق واسع.
تتضمن العديد من هذه التطبيقات تحليل الصور والفيديو في الوقت الفعلي، والاعتماد على الحوسبة السحابية ليس عمليًا دائمًا بسبب زمن الوصول والتكاليف ومخاوف الخصوصية. الذكاء الاصطناعي الطرفي (Edge AI) هو حل رائع في هذه الحالات. من خلال تشغيل نماذج Vision AI مباشرةً على الأجهزة الطرفية، يمكن للشركات معالجة البيانات بشكل أسرع وبتكلفة معقولة وأمان أكبر، مما يجعل الذكاء الاصطناعي في الوقت الفعلي أكثر سهولة.
خلال حدث YOLO Vision 2024 (YV24)، وهو الحدث السنوي الهجين الذي تستضيفه شركة Ultralytics كان أحد الموضوعات الرئيسية هو إضفاء الطابع الديمقراطي على الذكاء الاصطناعي في Vision من خلال جعل النشر أكثر سهولة وفعالية للمستخدم. ناقش غاي داهان، كبير مهندسي الحلول في NVIDIA كيف تساعد حلول NVIDIAللأجهزة والبرامج، بما في ذلك أجهزة الحوسبة المتطورة وخوادم الاستدلال وأطر عمل التحسين وحزم SDK لنشر الذكاء الاصطناعي، المطورين على تحسين الذكاء الاصطناعي على الحافة.
في هذه المقالة، سنستكشف في هذا المقال، النقاط الرئيسية التي استخلصناها من الكلمة الرئيسية التي ألقاها جاي داهان في مؤتمر YV24 وكيف تجعل أحدث ابتكارات NVIDIAنشر Vision AI أسرع وأكثر قابلية للتطوير.
بدأ غاي داهان حديثه بالتعبير عن حماسه للانضمام إلى YV24 افتراضيًا واهتمامه بحزمة Ultralytics Python ونماذجYOLO قائلاً: "أنا أستخدم Ultralytics منذ اليوم الذي ظهرت فيه. أنا أحب Ultralytics حقًا - لقد كنت أستخدم YOLOv5 حتى قبل ذلك، وأنا متحمس جدًا لهذه الحزمة."
ثم، قدم مفهوم الذكاء الاصطناعي الطرفي (Edge AI)، موضحًا أنه ينطوي على تشغيل حسابات الذكاء الاصطناعي مباشرة على الأجهزة مثل الكاميرات أو الطائرات بدون طيار أو الآلات الصناعية، بدلاً من إرسال البيانات إلى خوادم سحابية بعيدة للمعالجة.
بدلًا من انتظار تحميل الصور أو مقاطع الفيديو، وتحليلها، ثم إرسالها مرة أخرى مع النتائج، يتيح الذكاء الاصطناعي الطرفي (Edge AI) تحليل البيانات على الفور على الجهاز نفسه. وهذا يجعل أنظمة الرؤية الاصطناعية (Vision AI) أسرع وأكثر كفاءة وأقل اعتمادًا على الاتصال بالإنترنت. يعتبر الذكاء الاصطناعي الطرفي مفيدًا بشكل خاص لتطبيقات اتخاذ القرارات في الوقت الفعلي، مثل السيارات ذاتية القيادة وكاميرات المراقبة والمصانع الذكية.
بعد تقديم Edge AI، سلط غي دهان الضوء على مزاياه الرئيسية، مع التركيز على الكفاءة وتوفير التكاليف وأمن البيانات. وأوضح أن إحدى أكبر الفوائد هي زمن الوصول المنخفض - نظرًا لأن نماذج الذكاء الاصطناعي تعالج البيانات مباشرة على الجهاز، فليست هناك حاجة لإرسال المعلومات إلى السحابة والانتظار للحصول على استجابة.
يساعد الذكاء الاصطناعي المتطور أيضًا على تقليل التكاليف وحماية البيانات الحساسة. يمكن أن يكون إرسال كميات كبيرة من البيانات إلى السحابة، وخاصة تدفقات الفيديو، مكلفًا. ومع ذلك، فإن معالجتها محليًا تقلل من تكاليف النطاق الترددي والتخزين.
ميزة رئيسية أخرى هي خصوصية البيانات لأن المعلومات تبقى على الجهاز بدلاً من نقلها إلى خادم خارجي. وهذا مهم بشكل خاص لتطبيقات الرعاية الصحية والمالية والأمن، حيث يعد الحفاظ على البيانات المحلية والآمنة أولوية قصوى.
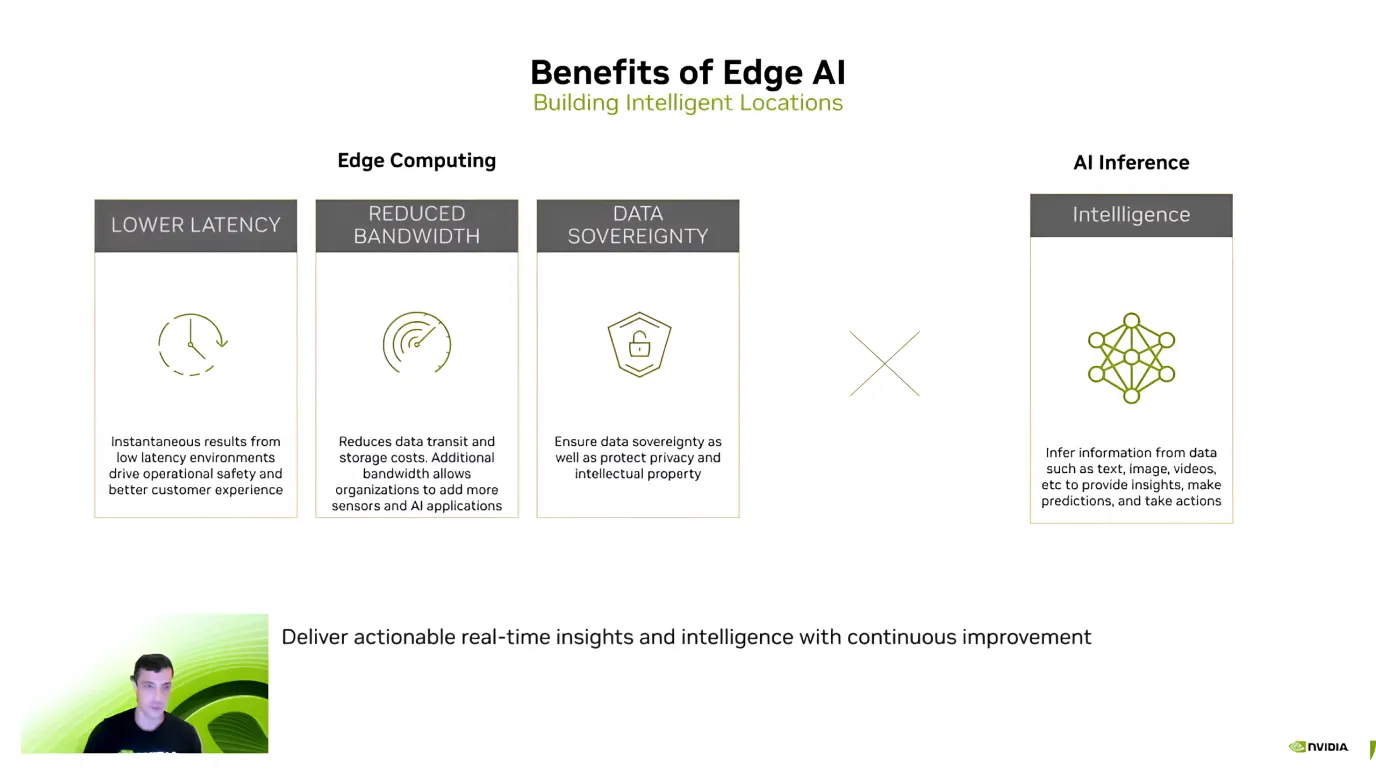
واستنادًا إلى هذه الفوائد، علّق جاي داهان على تزايد اعتماد الذكاء الاصطناعي Edge. وأشار إلى أنه منذ أن طرحت NVIDIA Jetson في عام 2014، زاد الاستخدام عشرة أضعاف. واليوم، يعمل أكثر من 1.2 مليون مطور مع أجهزة Jetson.
ثم ركز غاي داهان على أجهزةNVIDIA Jetson، وهي عائلة من أجهزة الحوسبة المتطورة للذكاء الاصطناعي المصممة لتقديم أداء عالٍ مع استهلاك منخفض للطاقة. أجهزة Jetson مثالية لتطبيقات الرؤية الحاسوبية في قطاعات مثل الروبوتات والزراعة والرعاية الصحية والأتمتة الصناعية. "Jetsons هي أجهزة ذكاء اصطناعي متطورة مصممة خصيصاً للذكاء الاصطناعي. بل يمكنني أن أضيف أنها مصممة في الأصل خصيصاً للرؤية الحاسوبية".
تأتي أجهزة Jetson في ثلاثة مستويات، كل منها مناسب لاحتياجات مختلفة:
كما تحدث جاي داهان عن Jetson AGX Thor القادم الذي سيتم إطلاقه هذا العام، وقال إنه سيقدم أداءً أكبر بثمانية أضعاف أداء وحدة معالجة الرسومات ( GPU )، وضعف سعة الذاكرة، وأداءً محسناً لوحدة المعالجة المركزية ( CPU ). وهو مصمم خصيصاً للروبوتات الشبيهة بالبشر وتطبيقات الذكاء الاصطناعي المتطورة Edge.
ثم انتقل غي داهان لمناقشة الجانب البرمجي من Edge AI وأوضح أنه حتى مع وجود أجهزة قوية، يمكن أن يكون نشر النماذج بكفاءة أمرًا صعبًا.
إحدى أكبر العقبات هي التوافق، حيث يعمل مطورو الذكاء الاصطناعي غالباً مع أطر عمل مختلفة للذكاء الاصطناعي مثل PyTorch و TensorFlow. قد يكون التنقل بين هذه الأطر أمراً صعباً، مما يتطلب من المطورين إعادة إنشاء البيئات لضمان تشغيل كل شيء بشكل صحيح.
تعد قابلية التوسع تحديًا رئيسيًا آخر. تتطلب نماذج الذكاء الاصطناعي قوة حوسبة كبيرة، وكما قال داهان، "لم تكن هناك شركة ذكاء اصطناعي تريد قوة حوسبة أقل." يمكن أن يصبح توسيع تطبيقات الذكاء الاصطناعي عبر أجهزة متعددة مكلفًا بسرعة، مما يجعل التحسين ضروريًا.
أيضًا، تعد خطوط أنابيب الذكاء الاصطناعي معقدة، وغالبًا ما تتضمن أنواعًا مختلفة من البيانات، والمعالجة في الوقت الفعلي، وتكامل الأنظمة. يبذل المطورون الكثير من الجهد للتأكد من أن نماذجهم تتفاعل بسلاسة مع النظم البيئية للبرامج الحالية. يعد التغلب على هذه التحديات جزءًا حاسمًا من جعل عمليات نشر الذكاء الاصطناعي أكثر كفاءة وقابلية للتطوير.
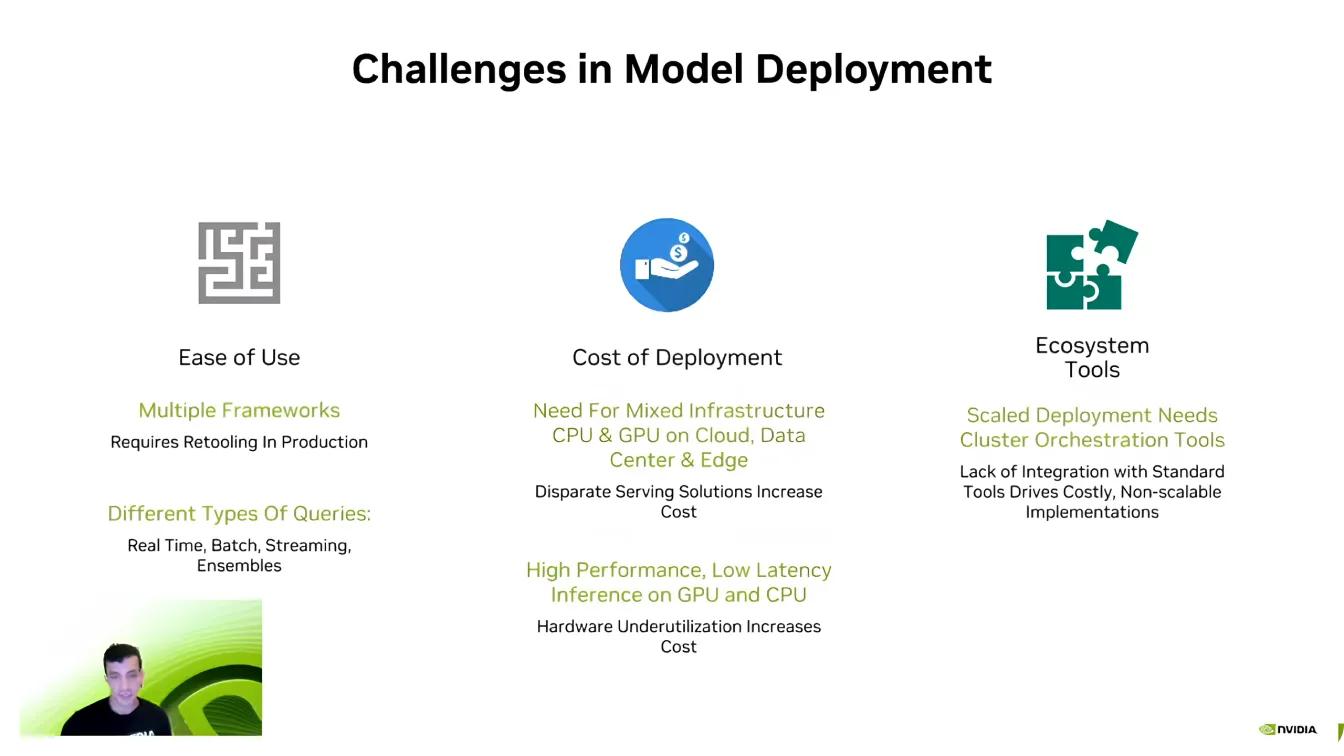
بعد ذلك، حوّل جاي داهان انتباهه إلى خادم الاستدلالTriton Inference Server من NVIDIA. وأشار إلى أن العديد من الشركات والشركات الناشئة تبدأ في تطوير الذكاء الاصطناعي دون تحسين نماذجها بالكامل. إن إعادة تصميم خط أنابيب الذكاء الاصطناعي بالكامل من الصفر قد يكون معطلاً ويستغرق وقتاً طويلاً، مما يجعل من الصعب التوسع بكفاءة.
بدلاً من الحاجة إلى إجراء إصلاح شامل للنظام، يسمح Triton للمطورين بتحسين وتحسين تدفقات عمل الذكاء الاصطناعي تدريجياً، ودمج مكونات أكثر كفاءة دون كسر الإعدادات الحالية. بفضل دعمه للعديد من أطر عمل الذكاء الاصطناعي، بما في ذلك TensorFlow PyTorch ONNX TensorRT يتيح Triton النشر السلس عبر البيئات السحابية ومراكز البيانات والأجهزة الطرفية بأقل قدر من التعديلات.

فيما يلي بعض المزايا الرئيسية لخادم الاستدلال Triton Inference Server من NVIDIA:
لنفترض أنك تبحث عن المزيد من التسارع; NVIDIA TensorRT خيارًا مثيرًا للاهتمام لتحسين نماذج الذكاء الاصطناعي الخاصة بك. أوضح جاي داهان أن TensorRT هو مُحسِّن تعلُّم عميق عالي الأداء مصمم لوحدات معالجة الرسومات NVIDIA . يمكن تحويل النماذج من TensorFlow و PyTorch و ONNX و MXNet إلى ملفات عالية الكفاءة GPU باستخدام TensorRT.
ما يجعل TensorRT موثوقاً للغاية هو تحسيناته الخاصة بالأجهزة. لن يعمل النموذج المحسّن لأجهزة Jetson بنفس الكفاءة على وحدات معالجة الرسومات الأخرى لأن TensorRT يضبط الأداء بناءً على الأجهزة المستهدفة. يمكن أن يؤدي نموذج الرؤية الحاسوبية المحسّن إلى زيادة سرعة الاستدلال بما يصل إلى 36 مرة مقارنةً بالنماذج غير المحسّنة.
لفت غاي داهان الانتباه أيضًا إلى دعم Ultralytics لـ TensorRT متحدثًا عن كيفية جعل نشر نماذج الذكاء الاصطناعي أسرع وأكثر كفاءة. يمكن تصدير نماذج Ultralytics YOLO مباشرةً إلى تنسيق TensorRT مما يتيح للمطورين تحسينها لوحدات معالجة الرسومات NVIDIA دون الحاجة إلى إجراء أي تغييرات.
وفي ختام المحاضرة، عرض غاي داهان عرض DeepStream 7.0، وهو إطار عمل للذكاء الاصطناعي مصمم لمعالجة بيانات الفيديو والصوت وبيانات المستشعرات في الوقت الفعلي باستخدام وحدات معالجة الرسومات NVIDIA . تم تصميمه لدعم تطبيقات الرؤية الحاسوبية عالية السرعة، وهو يتيح اكتشاف الأجسام وتتبعها وتحليلها عبر الأنظمة المستقلة والأمن والأتمتة الصناعية والمدن الذكية. من خلال تشغيل الذكاء الاصطناعي مباشرةً على الأجهزة المتطورة، يعمل DeepStream على التخلص من الاعتماد على السحابة، مما يقلل من زمن الاستجابة ويحسن الكفاءة.

على وجه التحديد، يمكن لـ DeepStream التعامل مع معالجة الفيديو المدعومة بالذكاء الاصطناعي من البداية إلى النهاية. وهو يدعم سير العمل الشامل، بدءًا من فك ترميز الفيديو والمعالجة المسبقة وحتى الاستدلال بالذكاء الاصطناعي والمعالجة اللاحقة.
في الآونة الأخيرة، قدمت DeepStream العديد من التحديثات لتحسين نشر الذكاء الاصطناعي، مما يجعلها أكثر سهولة وقابلية للتطوير. تعمل الأدوات الجديدة على تبسيط التطوير وتحسين تتبع الكاميرات المتعددة وتحسين خطوط أنابيب الذكاء الاصطناعي لتحسين الأداء.
يتمتع المطورون الآن بدعم موسع لبيئات Windows، وقدرات محسنة لدمج أجهزة الاستشعار لدمج البيانات من مصادر متعددة، والوصول إلى تطبيقات مرجعية مُنشأة مسبقًا لتسريع النشر. هذه التحسينات تجعل DeepStream حلاً أكثر مرونة وكفاءة لتطبيقات الذكاء الاصطناعي في الوقت الفعلي، مما يساعد المطورين على توسيع نطاق تحليلات الفيديو الذكية بسهولة.
كما هو موضح في الكلمة الرئيسية التي ألقاها Guy Dahan في YV24، فإن الذكاء الاصطناعي المتطرف يعيد تعريف تطبيقات الرؤية الحاسوبية. مع التقدم في الأجهزة والبرامج، أصبحت المعالجة في الوقت الفعلي أسرع وأكثر كفاءة وفعالية من حيث التكلفة.
مع تبني المزيد من الصناعات للذكاء الاصطناعي الطرفي (Edge AI)، سيكون التصدي للتحديات مثل التجزئة وتعقيد النشر أمرًا أساسيًا لإطلاق إمكاناته الكاملة. إن تبني هذه الابتكارات سيؤدي إلى تطبيقات ذكاء اصطناعي أكثر ذكاءً واستجابة، مما يشكل مستقبل رؤية الكمبيوتر.
كن جزءًا من مجتمعنا المتنامي! استكشف مستودع GitHub الخاص بنا لمعرفة المزيد حول الذكاء الاصطناعي، وتحقق من خيارات الترخيص الخاصة بنا لبدء مشاريع Vision AI الخاصة بك. هل أنت مهتم بالابتكارات مثل الذكاء الاصطناعي في الرعاية الصحية و رؤية الكمبيوتر في التصنيع؟ قم بزيارة صفحات الحلول الخاصة بنا لمعرفة المزيد!


