



Explore how Edge AI and NVIDIA's innovations, like the Jetson, Triton, and TensorRT, are simplifying the deployment of computer vision applications.

Explore how Edge AI and NVIDIA's innovations, like the Jetson, Triton, and TensorRT, are simplifying the deployment of computer vision applications.
Thanks to recent advancements in computer vision and artificial intelligence (AI), what was once just a field of research is now driving impactful applications across a range of industries. From self-driving cars to medical imaging and security, computer vision systems are solving real problems at scale.
Many of these applications involve analyzing images and video in real time, and relying on cloud computing isn’t always practical due to latency, costs, and privacy concerns. Edge AI is a great solution in these situations. By running Vision AI models directly on edge devices, businesses can process data faster, more affordably, and with greater security, making real-time AI more accessible.
During YOLO Vision 2024 (YV24), the annual hybrid event hosted by Ultralytics, one of the central themes was democratizing Vision AI by making deployment more user-friendly and efficient. Guy Dahan, Senior Solutions Architect at NVIDIA, discussed how NVIDIA’s hardware and software solutions, including edge computing devices, inference servers, optimization frameworks, and AI deployment SDKs, are helping developers optimize AI at the edge.
In this article, we’ll explore key takeaways from Guy Dahan’s YV24 keynote and how NVIDIA’s latest innovations are making Vision AI deployment faster and more scalable.
Guy Dahan began his talk by expressing his enthusiasm for joining YV24 virtually and his interest in the Ultralytics Python package and Ultralytics YOLO models, saying, "I've been using Ultralytics since the day it came out. I really like Ultralytics - I've been using YOLOv5 even before that, and I'm a real enthusiast for this package."
Then, he introduced the concept of Edge AI, explaining that it involves running AI computations directly on devices like cameras, drones, or industrial machines, rather than sending data to distant cloud servers for processing.
Instead of waiting for images or videos to be uploaded, analyzed, and then sent back with results, Edge AI makes it possible to analyze the data instantly on the device itself. This makes Vision AI systems faster, more efficient, and less dependent on internet connectivity. Edge AI is particularly useful for real-time decision-making applications, such as self-driving cars, security cameras, and smart factories.
After introducing Edge AI, Guy Dahan highlighted its main advantages, focusing on efficiency, cost savings, and data security. He explained that one of the biggest benefits is low latency - since AI models process data directly on the device, there’s no need to send information to the cloud and wait for a response.
Edge AI also helps reduce costs and protect sensitive data. Sending large amounts of data to the cloud, especially video streams, can be expensive. However, processing it locally reduces bandwidth and storage costs.
Another key advantage is data privacy because information stays on the device instead of being transferred to an external server. This is particularly important for healthcare, finance, and security applications, where keeping data local and secure is a top priority.
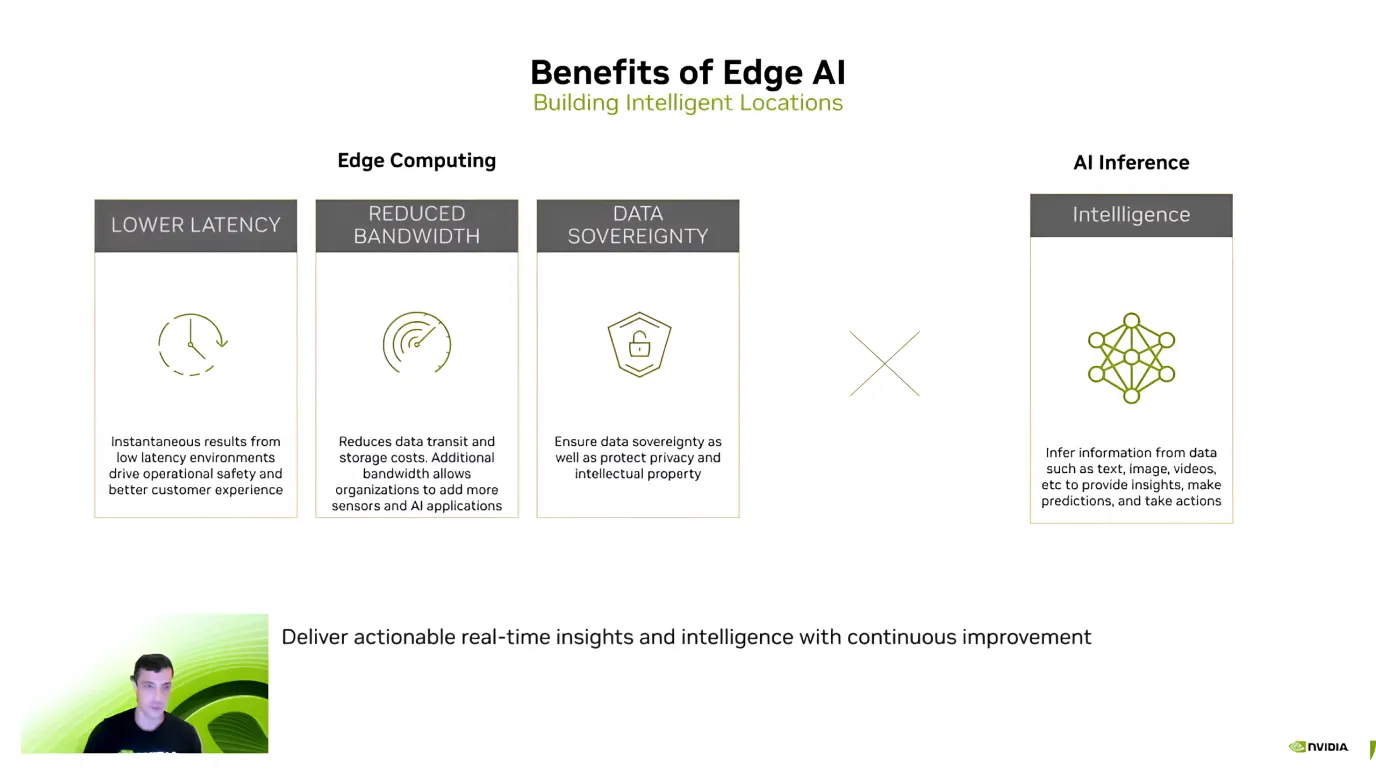
Building on these benefits, Guy Dahan commented on the growing adoption of Edge AI. He noted that since NVIDIA introduced Jetson in 2014, usage has increased tenfold. Today, over 1.2 million developers are working with Jetson devices.
Guy Dahan then focused on NVIDIA Jetson devices, a family of AI edge computing devices designed to deliver high performance with low power consumption. Jetson devices are ideal for computer vision applications in sectors like robotics, agriculture, healthcare, and industrial automation. "Jetsons are Edge AI devices specifically tailor-made for AI. I might even add that originally they were designed mostly for computer vision," Guy Dahan added.
Jetson devices come in three tiers, each suited for different needs:
Also, Guy Dahan shared about the upcoming Jetson AGX Thor, launching this year, and said that it will offer eight times the GPU (Graphics Processing Unit) performance, twice the memory capacity, and improved CPU (Central Processing Unit) performance. It’s specifically designed for humanoid robotics and advanced Edge AI applications.
Guy Dahan then pivoted to discussing the software side of Edge AI and explained that even with powerful hardware, deploying models efficiently can be challenging.
One of the biggest hurdles is compatibility, as AI developers often work with different AI frameworks like PyTorch and TensorFlow. Moving between these frameworks can be difficult, requiring developers to recreate environments to ensure everything runs correctly.
Scalability is another key challenge. AI models require significant computing power, and as Dahan put it, "There has never been an AI company that wants less compute." Expanding AI applications across multiple devices can quickly become expensive, making optimization essential.
Also, AI pipelines are complex, often involving different types of data, real-time processing, and system integration. Developers put a lot of effort into making sure their models interact seamlessly with existing software ecosystems. Overcoming these challenges is a crucial part of making AI deployments more efficient and scalable.
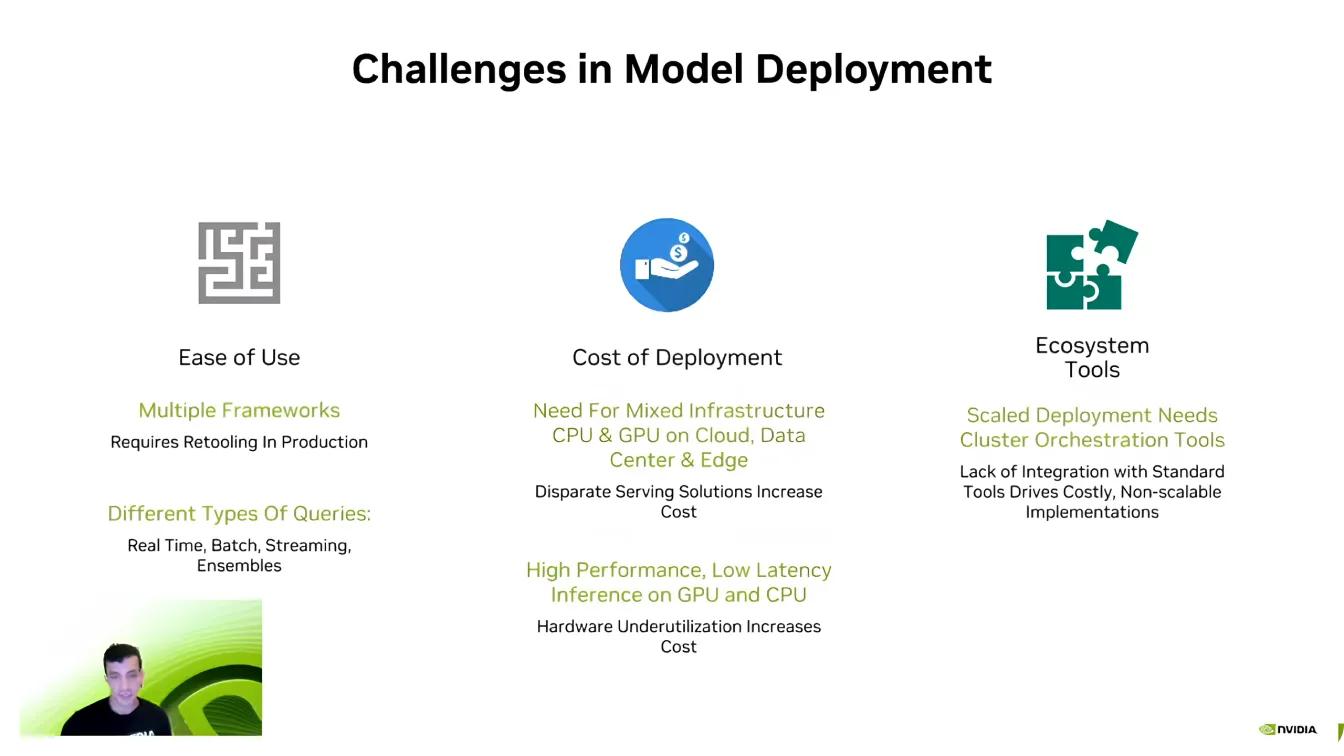
Next, Guy Dahan turned his attention to NVIDIA’s Triton Inference Server. He pointed out that many companies and startups begin AI development without fully optimizing their models. Redesigning an entire AI pipeline from scratch can be disruptive and time-consuming, making it difficult to scale efficiently.
Instead of requiring a complete system overhaul, Triton allows developers to gradually refine and optimize their AI workflows, integrating more efficient components without breaking their existing setup. With support for multiple AI frameworks, including TensorFlow, PyTorch, ONNX, and TensorRT, Triton enables seamless deployment across cloud environments, data centers, and edge devices with minimal adjustments.

Here are some of the key advantages of NVIDIA’s Triton Inference Server:
Let’s say you are looking for even more acceleration; NVIDIA TensorRT is an interesting option to optimize your AI models. Guy Dahan elaborated that TensorRT is a high-performance deep learning optimizer built for NVIDIA GPUs. Models from TensorFlow, PyTorch, ONNX, and MXNet can be converted into highly efficient GPU-executable files using TensorRT.
What makes TensorRT so reliable is its hardware-specific optimizations. A model optimized for Jetson devices won’t perform as efficiently on other GPUs because TensorRT fine-tunes performance based on the target hardware. A fine-tuned computer vision model can result in an increase in inference speed by up to 36 times compared to unoptimized models.
Guy Dahan also called attention to Ultralytics' support for TensorRT, talking about how it makes AI model deployment faster and more efficient. Ultralytics YOLO models can be directly exported to TensorRT format, letting developers optimize them for NVIDIA GPUs without needing to make any changes.
Wrapping up the talk on a high note, Guy Dahan showcased DeepStream 7.0 - an AI framework designed for real-time processing of video, audio, and sensor data using NVIDIA GPUs. Built to support high-speed computer vision applications, it enables object detection, tracking, and analytics across autonomous systems, security, industrial automation, and smart cities. By running AI directly on edge devices, DeepStream eliminates cloud dependency, reducing latency and improving efficiency.

Specifically, DeepStream can handle AI-powered video processing from start to finish. It supports end-to-end workflows, from video decoding and pre-processing to AI inference and post-processing.
Recently, DeepStream has introduced several updates to enhance AI deployment, making it more accessible and scalable. New tools simplify development, improve multi-camera tracking, and optimize AI pipelines for better performance.
Developers now have expanded support for Windows environments, enhanced sensor fusion capabilities for integrating data from multiple sources, and access to pre-built reference applications to accelerate deployment. These improvements make DeepStream a more flexible and efficient solution for real-time AI applications, helping developers scale intelligent video analytics with ease.
As illustrated in Guy Dahan’s keynote at YV24, Edge AI is redefining computer vision applications. With advancements in hardware and software, real-time processing is becoming faster, more efficient, and cost-effective.
As more industries adopt Edge AI, addressing challenges like fragmentation and deployment complexity will be key to unlocking its full potential. Embracing these innovations will drive smarter, more responsive AI applications, shaping the future of computer vision.
Become a part of our growing community! Explore our GitHub repository to learn more about AI, and check out our licensing options to kickstart your Vision AI projects. Curious about innovations like AI in healthcare and computer vision in manufacturing? Visit our solutions pages to learn more!


