



Take a deep dive with us into the applications of computer vision. We'll also walk through various computer vision tasks like object detection and segmentation.

Take a deep dive with us into the applications of computer vision. We'll also walk through various computer vision tasks like object detection and segmentation.
When we explored the history of computer vision models, we saw how computer vision has evolved and the path that has led to the advanced vision models we have today. Modern models like Ultralytics YOLOv8 support multiple computer vision tasks and are being used in various exciting applications.
In this article, we’ll take a look at the basics of computer vision and vision models. We'll cover how they work and their diverse applications across various industries. Computer vision innovations are everywhere, silently shaping our world. Let’s uncover them one by one!
Artificial intelligence (AI) is an umbrella term that encompasses many technologies that aim to replicate a part of human intelligence. One such subfield of AI is computer vision. Computer vision focuses on giving machines eyes that can see, observe, and comprehend their surroundings.
Just like human vision, computer vision solutions aim to distinguish objects, calculate distances, and detect movements. However, unlike humans, who have a lifetime of experiences to help them see and understand, computers rely on vast amounts of data, high-definition cameras, and complex algorithms.
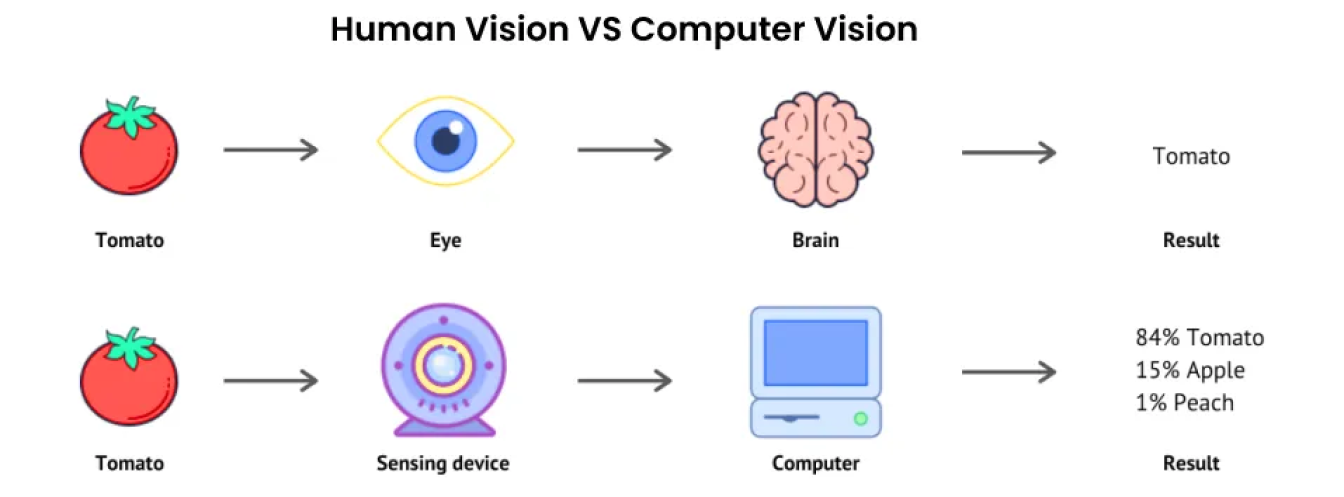
Computer vision systems can process and analyze visual data like images and videos at incredible speeds and accuracy. The ability to quickly and accurately analyze vast amounts of visual information makes computer vision a powerful tool in various industries, ranging from manufacturing to healthcare.
Computer vision models are the core of any computer vision application. They are essentially computational algorithms powered by deep learning techniques designed to give machines the ability to interpret and understand visual information. Vision models enable crucial computer vision tasks ranging from image classification to object detection. Let’s take a closer look at some of these tasks and their use cases in more detail.
Image classification involves categorizing and labeling images into predefined classes or categories. A vision model like YOLOv8 can be trained on large datasets of labeled images. During training, the model learns to recognize patterns and features associated with each class. Once trained, it can predict the category of new, unseen images by analyzing their features and comparing them to the learned patterns.
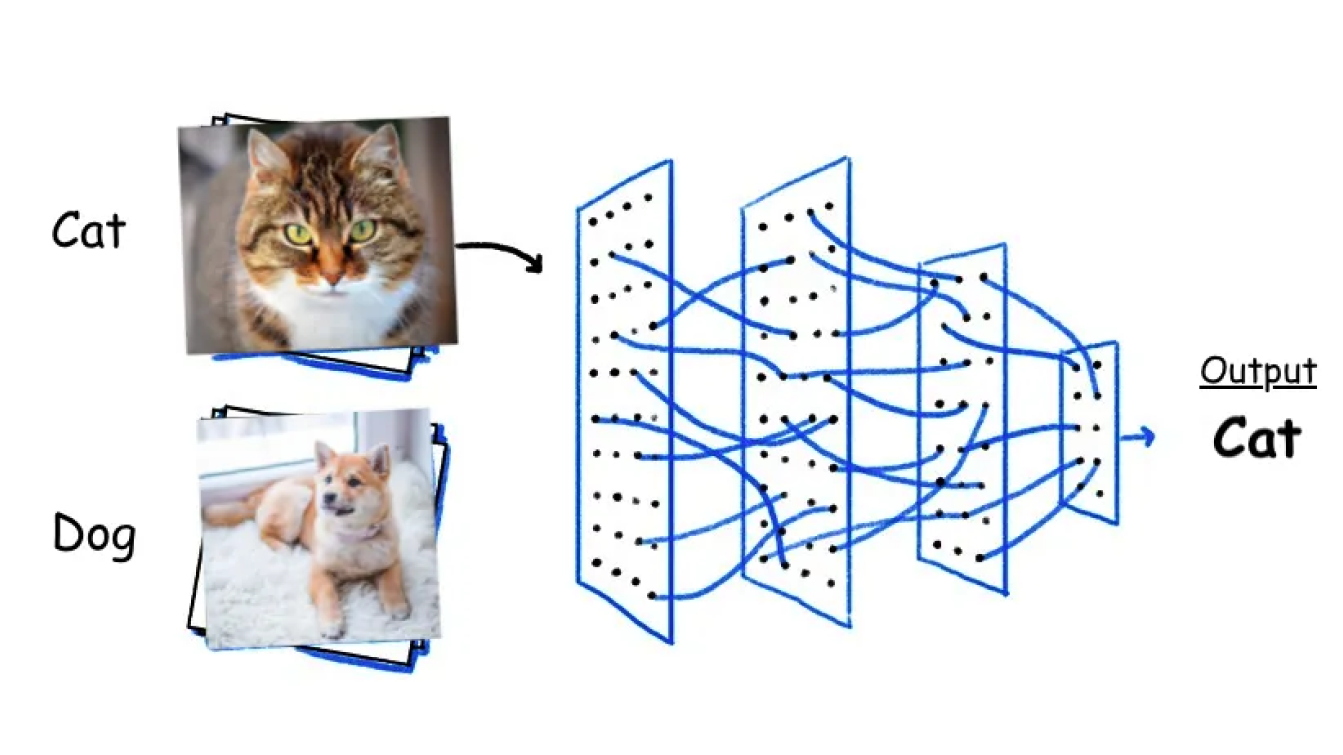
There are different types of image classification. For example, when dealing with medical images, you can use binary classification to divide pictures into two groups, like healthy or sick. Another type is multiclass classification. It can help classify images into many groups, like classifying different animals on a farm like pigs, goats, and cows. Or, let’s say you want to classify animals into groups and subgroups, like classifying animals into mammals and birds and then further into species such as lions, tigers, eagles, and sparrows; hierarchical classification would be the best option.
Object detection is the process of identifying and locating objects in images and video frames using computer vision. It consists of two tasks: object localization, which draws bounding boxes around objects, and object classification, which identifies each object's category. Based on bounding box annotations, a vision model can learn to recognize patterns and features specific to each object category and predict the presence and location of these objects in new, unseen images.
.png)
Object detection has many use cases across different industries, anywhere from sports to marine biology. For example, in retail, Amazon’s Just Walk Out technology uses object detection to automate checkout by identifying items customers pick up. A combination of computer vision and sensor data allows customers to grab their items and leave without waiting in line.
Here's a closer look at how it works:
Semantic segmentation and instance segmentation are computer vision tasks that help partition images into meaningful segments. Semantic segmentation classifies pixels based on their semantic meaning and treats all objects within a category as a single entity with the same label. It is suitable for labeling uncountable objects like "the sky" or "ocean" or clusters like "leaves" or "grass."
Instance segmentation, on the other hand, can tell apart different instances of the same class by assigning a unique label to each detected object. You can use instance segmentation to segment countable objects where the number and independence of objects are important. It allows for more precise identification and differentiation.
.png)
We can understand the contrast between semantic and instance segmentation more clearly with an example related to self-driving cars. Semantic segmentation is great for tasks that require understanding the contents of a scene and can be used in autonomous vehicles to classify features on the road, like pedestrian crossings and traffic signs. Meanwhile, instance segmentation can be used in autonomous vehicles to identify between individual pedestrians, vehicles, and obstacles.
Pose estimation is a computer vision task focused on detecting and tracking key points of an object's poses in images or videos. It is most commonly used for human pose estimation, with key points including areas like shoulders and knees. Estimating a human’s pose helps us understand and recognize actions and movements that are critical for various applications.

Pose estimation can be used in sports to analyze how athletes move. The NBA uses pose estimation to study player movements and positions during the game. By tracking key points like shoulders, elbows, knees, and ankles, pose estimation provides detailed insights into player movements. These insights help coaches develop better strategies, optimize training programs, and make real-time adjustments during games. Also, the data can help monitor player fatigue and injury risk to improve overall player health and performance.
Oriented Bounding Boxes Object Detection (OBB) uses rotated rectangles to precisely identify and locate objects in an image. Unlike standard bounding boxes that align with the image axes, OBBs rotate to match the object's orientation. This makes them especially useful for objects that are not perfectly horizontal or vertical. They are great at accurately pinpointing and isolating rotated objects to prevent overlaps in crowded environments.
.png)
In maritime surveillance, identifying and tracking ships is key for security and resource management. OBB detection can be used for precise localization of ships, even when they are densely packed or oriented at various angles. It helps monitor shipping lanes, manage maritime traffic, and optimize port operations. It can also assist in disaster response by quickly identifying and assessing damage to ships and infrastructure after events like hurricanes or oil spills.
So far, we’ve discussed computer vision tasks that deal with images. Object tracking is a computer vision task that can track an object throughout the frames of a video. It starts by identifying the object in the first frame using detection algorithms and then continuously follows its position as it moves through the video. Object tracking involves techniques like object detection, feature extraction, and motion prediction to keep the tracking accurate.

Vision models like YOLOv8 can be used to track fish in marine biology. Using underwater cameras, researchers can monitor the movements and behaviors of fish in their natural habitats. The process starts by detecting individual fish in the first frames and then follows their positions throughout the video. Tracking fish helps scientists understand migration patterns, social behaviors, and interactions with the environment. It also supports sustainable fishing practices by providing insights into fish distribution and abundance.
Computer vision is actively changing how we use technology and interact with the world. By using deep learning models and complex algorithms to understand images and videos, computer vision helps industries streamline many processes. Computer vision tasks like object detection and object tracking are making it possible to create solutions that haven’t been imagined before. As computer vision technology keeps improving, the future holds many more innovative applications!
Let’s learn and grow together! Explore our GitHub repository to see our contributions to AI. Check out how we are redefining industries like self-driving cars and agriculture with AI. 🚀
.webp)

.webp)