



Learn about YOLO-World, an innovative object detection model that can identify objects through text prompts. Explore how YOLO-World works and its applications, and get hands-on with a quick code example.

Learn about YOLO-World, an innovative object detection model that can identify objects through text prompts. Explore how YOLO-World works and its applications, and get hands-on with a quick code example.
Computer vision projects often involve spending a lot of time annotating data and training object detection models. But, that might soon be a thing of the past. Tencent’s AI Lab released YOLO-World, a real-time, open-vocabulary object detection model, on January 31st, 2024. YOLO-World is a zero-shot model, meaning you can run object detection inferences on images without having to train it.
Zero-shot models have the potential to change the way we approach computer vision applications. In this blog, we'll explore how YOLO-World works and its potential uses and share a practical code example to get you started.
You can pass an image and text prompt describing what objects you're looking for through the YOLO-World model. For example, if you're interested in finding "a person wearing a red shirt" within a photo, YOLO-World takes this input and gets to work.
The model’s unique architecture combines three main elements:
The YOLO detector scans your input image to identify potential objects. The text encoder transforms your description into a format that the model can understand. These two streams of information are then merged through the RepVL-PAN using multi-level cross-modality fusion. It lets YOLO-World precisely detect and locate the objects described in your prompt within the image.

One of the biggest advantages of using YOLO-World is that you don't have to train the model for a specific class. It has already learned from pairs of images and texts, so it knows how to find objects based on descriptions. You can avoid hours of collecting data, annotating data, training on expensive GPUs, and so on.
Here are some other benefits of using YOLO-World:
YOLO-World models can be used for a wide variety of applications. Let’s explore some of them.
Products manufactured on an assembly line are checked visually for defects before packing them. The defect detection is often done by hand, which takes time and can lead to mistakes. These mistakes can cause problems like high costs and the need for repairs or recalls. To help with this, special machine vision cameras and AI systems have been created to perform these checks.
YOLO-World models are a big advancement in this area. They can find defects in products even when they haven't been trained for that specific problem using their zero-shot abilities. For example, a factory manufacturing water bottles can easily identify between a bottle sealed properly with a bottle cap versus a bottle where a cap was missed out or faulty using YOLO-World.

YOLO-World models allow robots to interact with unfamiliar environments. Without being trained on specific objects that may be in a room, they can still identify what objects are present. So, let’s say a robot enters a room it has never been in before. With a YOLO-World model, it can still recognize and identify objects like chairs, tables, or lamps, even though it hasn't been specifically trained on those items.
In addition to object detection, YOLO-World can also determine the conditions of those objects, thanks to its 'prompt-then-detect' feature. For instance, in agricultural robotics, it can be used to identify ripe fruits versus not ripe fruits by programming the robot to detect them.
The automobile industry involves many moving parts, and YOLO-World can be used for different car applications. For example, when it comes to car maintenance, YOLO-World's ability to recognize a wide variety of objects without manual tagging or extensive pre-training is extremely useful. YOLO-World can be used to identify car parts that need to be replaced. It could even automate tasks like quality checks, spotting defects or missing pieces in new cars.
Another application is zero-shot object detection in self-driving cars. YOLO-World’s zero-shot detection capabilities can improve an autonomous vehicle’s capability to detect and classify objects on the road, such as pedestrians, traffic signs, and other vehicles, in real time. By doing so, it can help detect obstacles and prevent accidents for a safer journey.
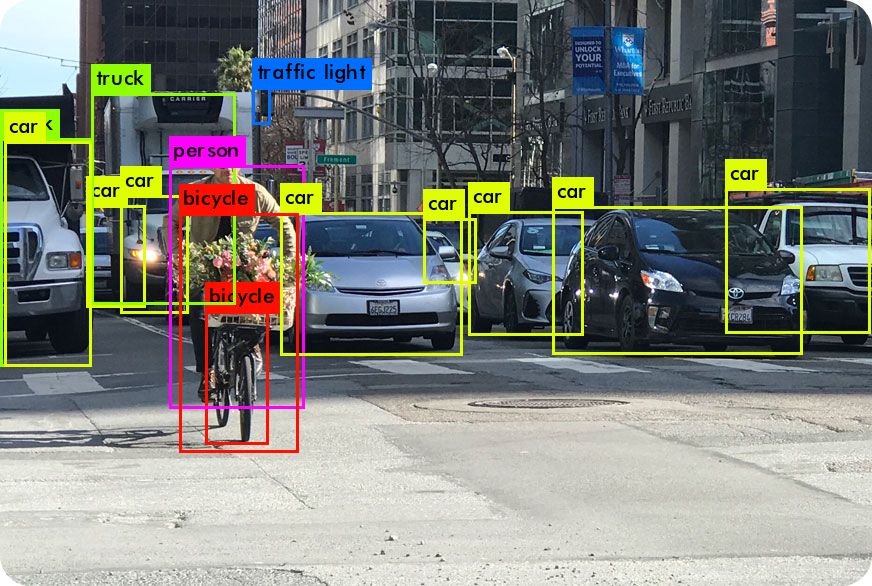
Identifying objects on shelves in retail stores is an important part of tracking inventory, maintaining stocks, and automating processes. Ultralytics YOLO-World's ability to recognize a wide variety of objects without manual tagging or extensive pre-training is extremely useful for inventory management.
For instance, in inventory management, YOLO-World can swiftly spot and categorize items on a shelf, such as different brands of energy drinks. Retail stores can keep accurate inventory, manage stock levels efficiently, and smooth out supply chain operations.
All of the applications are unique and show just how extensively YOLO-World can be used. Next, let’s get hands-on with YOLO-World and take a look at a coding example.
As we mentioned before, YOLO-World can be used to detect different parts of a car for maintenance. A computer vision application that detects any repairs needed would involve taking a picture of the car, identifying car parts, examining each part of the car for damage, and recommending repairs. Every part of this system would use different AI techniques and approaches. For the purpose of this code walkthrough, let’s focus on the part when car parts are detected.
With YOLO-World, you can identify different car parts in an image in under 5 minutes. You can extend this code to try out different applications using YOLO-World as well! To get started, we’ll need to pip install the Ultralytics package as shown below.
For more instructions and best practices related to the installation process, check our Ultralytics Installation guide. While installing the required packages for YOLOv8, if you encounter any difficulties, take a look at our Common Issues guide for solutions and tips.
Once you’ve installed the needed package, we can download an image from the Internet to run our inferences on. We are going to use the image below.

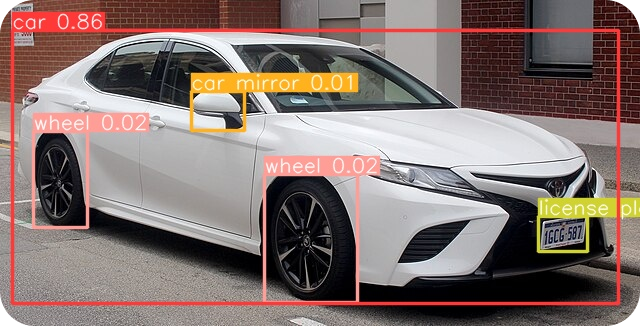
Then, we’ll import the needed package, initialize our model, and set the classes we are looking for in our input image. Here, we are interested in the following classes: car, wheel, car door, car mirror, and license plate.
We'll then use the predict method, providing the image's path along with parameters for the maximum number of detections, and thresholds for intersection over union (IoU) and confidence (conf) to run an inference on the image. Lastly, the detected objects are saved to a file named 'result.jpg.'
The following output image will be saved to your files.
If you’d prefer to see what YOLO-World can do without coding, you can go to the YOLO-World Demo page, upload an input image, and enter the custom classes.
Read our docs page on YOLO-World to learn how to save the model with the custom classes so that it can be used directly later without entering custom classes repeatedly.
If you take a look at the output image again, you’ll notice the custom class “car door” wasn’t detected. Despite its great achievements, YOLO-World has certain limitations. To combat these limitations and use the YOLO-World model effectively, it’s important to use the correct types of textual prompts.
Here’s some insight into it:
Overall, YOLO-World models, can be made into a powerful tool with their advanced object detection capabilities It provides great efficiency, accuracy, and helps automate different tasks across various applications, like the example of identifying car parts that we practically discussed.
Feel free to explore our GitHub repository to learn more about our contributions to computer vision and AI. If you're curious about how AI is reshaping sectors like healthcare technology, check out our solutions pages. The possibilities with innovations like YOLO-World seem to be endless!
.webp)

.webp)