


Getting to know Llama 3.1: Meta’s latest open-source model family

Explore Meta's new Llama 3.1 open-source model family, featuring the versatile 8B, the all rounder 70B, and the flagship 405B, their largest and most advanced model to date.

Explore Meta's new Llama 3.1 open-source model family, featuring the versatile 8B, the all rounder 70B, and the flagship 405B, their largest and most advanced model to date.
On July 23, 2024, Meta released the new Llama 3.1 open-source family of models, featuring the versatile 8B, the capable 70B, and the Llama 3.1 405B models, with the latest standing out as the largest open-source large language model (LLM) to date.
You might be wondering what sets these new models apart from their predecessors. Well, as we delve into this article, you'll discover that the release of the Llama 3.1 models marks a significant milestone in AI technology. The newly released models offer significant improvements in natural language processing; moreover, they introduce new features and enhancements not found in earlier versions. This release promises to change how we leverage AI for complex tasks, providing a powerful toolset for researchers and developers alike.
In this article, we will explore the Llama 3.1 family of models, delving into their architecture, key improvements, practical uses, and a detailed comparison of their performance.
Meta's latest Large Language Model, Llama 3.1, is making significant strides in the AI landscape, rivaling the capabilities of top-tier models like OpenAI's Chat GPT-4o and Anthropic’s Claude 3.5 Sonnet.
Even though it may be considered a minor update on the previous Llama 3 model, Meta has taken it another step forward by introducing some key improvements to the new model family, offering:
In addition to all of the above, the new Llama 3.1 model family highlights a major advancement with its impressive 405 billion parameter model. This substantial parameter count represents a significant leap forward in AI development, greatly enhancing the model’s capacity to understand and generate complex text. The 405B model includes an extensive array of parameters with each parameter referring to the weights and biases in the neural network that the model learns during training. This allows the model to capture more intricate language patterns, setting a new standard for large language models and showcasing the future potential of AI technology. This large-scale model not only improves performance on a wide range of tasks but also pushes the boundaries of what AI can achieve in terms of text generation and comprehension.
Llama 3.1 leverages the decoder-only transformer model architecture, a cornerstone for modern large language models. This architecture is renowned for its efficiency and effectiveness in handling complex language tasks. The use of transformers enables Llama 3.1 to excel in understanding and generating human-like text, providing a significant advantage over models that use older architectures such as LSTMs and GRUs.
Additionally, the Llama 3.1 model family utilizes the Mixture of Experts (MoE) architecture, which enhances training efficiency and stability. Avoiding the MoE architecture ensures a more consistent and reliable training process, as MoE can sometimes introduce complexities that may impact model stability and performance.
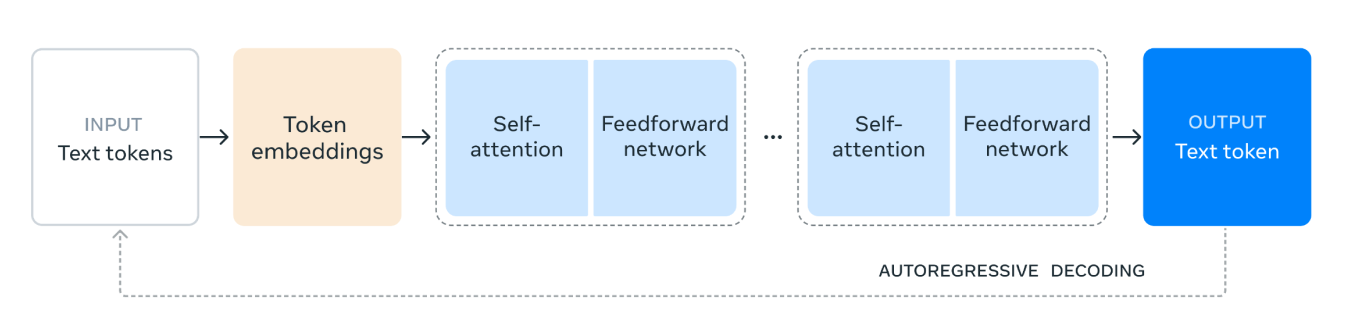
The Llama 3.1 model architecture works as follows:
1. Input Text Tokens: The process begins with the input, consisting of text tokens. These tokens are individual units of text, such as words or subwords, that the model will process.
2. Token Embeddings: The text tokens are then converted into token embeddings. Embeddings are dense vector representations of the tokens that capture their semantic meaning and relationships within the text. This transformation is crucial as it allows the model to work with numerical data.
3. Self-Attention Mechanism: Self-attention allows the model to weigh the importance of different tokens in the input sequence when encoding each token. This mechanism helps the model to understand the context and relationships between tokens, regardless of their positions in the sequence. In the self-attention mechanism, each token in the input sequence is represented as a vector of numbers. These vectors are used to create three different types of representations: queries, keys, and values.
The model calculates how much attention each token should give to other tokens by comparing the query vectors with the key vectors. This comparison results in scores that indicate the relevance of each token in relation to others.
4. Feedforward Network: After the self-attention process, the data passes through a feedforward network. This network is a fully connected neural network that applies non-linear transformations to the data, helping the model to recognize and learn complex patterns.
5. Repeated Layers: The self-attention and feedforward network layers are stacked multiple times. This repeated application allows the model to capture more complex dependencies and patterns in the data.
6. Output Text Token: Finally, the processed data is used to generate the output text token. This token is the model's prediction for the next word or subword in the sequence, based on the input context.
Benchmark tests reveal that Llama 3.1 not only holds its own against these state-of-the-art models but also outperforms them in certain tasks, demonstrating its superior performance.
The Llama 3.1 model has undergone extensive evaluation across over 150 benchmark datasets, where it has been rigorously compared to other leading large language models. The Llama 3.1 405B model, recognized as the most capable in the newly released series, has been benchmarked against industry titans such as OpenAI’s GPT-4 and Claude 3.5 Sonnet. Results from these comparisons reveal that Llama 3.1 demonstrates a competitive edge, showcasing its superior performance and capabilities in various tasks.
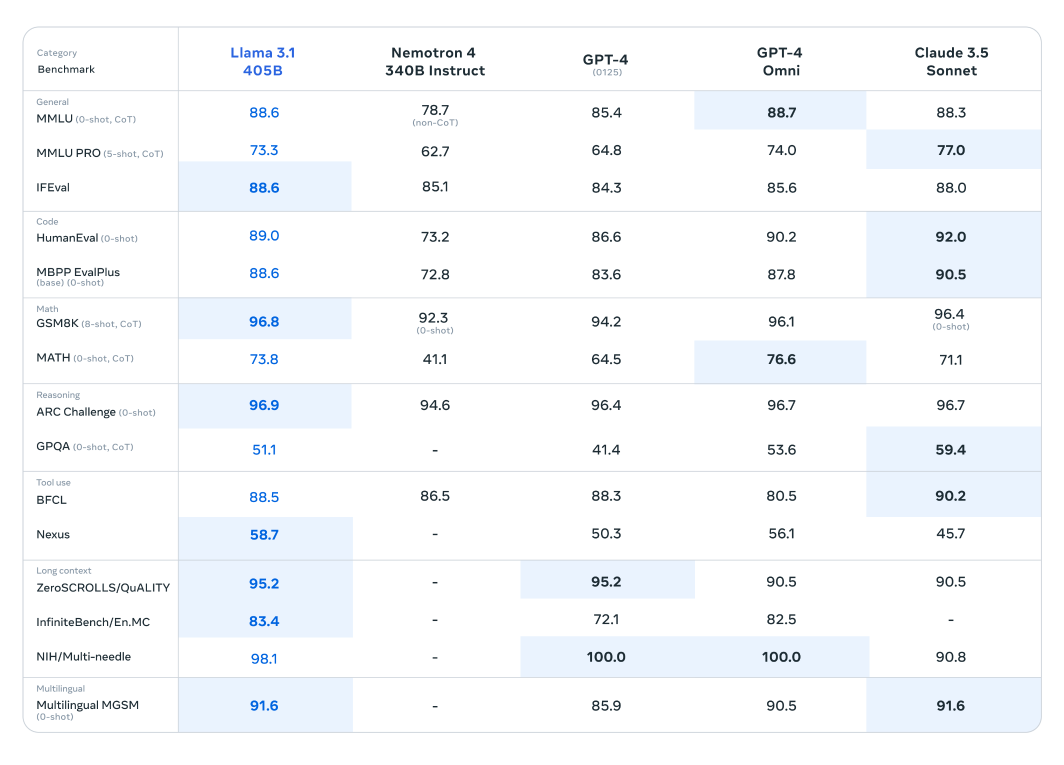
This model's impressive parameter count and advanced architecture enable it to excel in complex understanding and text generation, often surpassing its competitors in specific benchmarks. These evaluations highlight Llama 3.1's potential to set new standards in the field of large language models, providing researchers and developers with a powerful tool for diverse applications.
The smaller and more lightweight Llama models also demonstrate remarkable performance when compared to their counterparts. The Llama 3.1 70B model has been evaluated against larger models such as Mistral 8x22B and GPT-3.5 Turbo. For instance, the Llama 3.1 70B model consistently demonstrates superior performance in the reasoning datasets such as ARC Challenge dataset and coding datasets such as HumanEval datasets. These results highlight the versatility and robustness of the Llama 3.1 series across different model sizes, making it a valuable tool for a wide range of applications.
Additionally, the Llama 3.1 8B model has been benchmarked against models of similar size, including Gemma 2 9B and Mistral 7B. These comparisons reveal that the Llama 3.1 8B model outperforms its competitors in various benchmark datasets in different genres such as the GPQA dataset for reasoning and the MBPP EvalPlus for coding, showcasing its efficiency and capability despite its smaller parameter count.

Meta has enabled the new models to be applied in a variety of practical and beneficial ways for users:
Users can now fine-tune the latest Llama 3.1 models for specific use cases. This process involves training the model on new external data that it was not previously exposed to, thereby enhancing its performance and adaptability for targeted applications. Fine-tuning gives the model a significant edge by enabling it to better understand and generate content relevant to specific domains or tasks.
Llama 3.1 models can now be seamlessly integrated into Retrieval-Augmented Generation (RAG) systems. This integration allows the model to leverage external data sources dynamically, enhancing its ability to provide accurate and contextually relevant responses. By retrieving information from large datasets and incorporating it into the generation process, Llama 3.1 significantly improves its performance in knowledge-intensive tasks, offering users more precise and informed outputs.
You can also utilize the 405 billion parameter model to generate high-quality synthetic data, enhancing the performance of specialized models for specific use cases. This approach leverages the extensive capabilities of Llama 3.1 to produce targeted and relevant data, thereby improving the accuracy and efficiency of tailored AI applications.
The Llama 3.1 release represents a significant leap forward in the field of large language models, showcasing Meta's commitment to advancing AI technology.
With its substantial parameter count, extensive training on diverse datasets, and a focus on robust and stable training processes, Llama 3.1 sets new benchmarks for performance and capability in natural language processing. Whether in text generation, summarization, or complex conversational tasks, Llama 3.1 demonstrates a competitive edge over other leading models. This model not only pushes the boundaries of what AI can achieve today but also sets the stage for future innovations in the ever-evolving landscape of artificial intelligence.
At Ultralytics, we are dedicated to pushing the boundaries of AI technology. To explore our cutting-edge AI solutions and keep up with our latest innovations, check out our GitHub repository. Join our vibrant community on Discord and see how we're revolutionizing industries such as self-driving cars and manufacturing! 🚀


