



Join us as we take a closer look at Google’s new vision language models: PaliGemma 2. These models can help with understanding and analyzing both images and text.

Join us as we take a closer look at Google’s new vision language models: PaliGemma 2. These models can help with understanding and analyzing both images and text.
On December 5th, 2024, Google introduced PaliGemma 2, the latest version of its cutting-edge vision-language model (VLM). PaliGemma 2 is designed to handle tasks that combine images and text, such as generating captions, answering visual questions, and detecting objects in visuals.
Building on the original PaliGemma, which was already a strong tool for multilingual captioning and object recognition, PaliGemma 2 brings several key improvements. These include larger model sizes, support for higher-resolution images, and better performance on complex visual tasks. These upgrades make it even more flexible and effective for a wide range of uses.
In this article, we’ll take a closer look at PaliGemma 2, including how it works, its key features, and the applications where it shines. Let’s get started!
PaliGemma 2 is built on two key technologies: the SigLIP vision encoder and the Gemma 2 language model. The SigLIP encoder processes visual data, like images or videos, and breaks it into features that the model can analyze. Meanwhile, Gemma 2 handles text, enabling the model to understand and generate multilingual language. Together, they form a VLM, designed to interpret and connect visual and text information seamlessly.
What makes PaliGemma 2 a major step forward is its scalability and versatility. Unlike the original version, PaliGemma 2 comes in three sizes - 3 billion (3B), 10 billion (10B), and 28 billion (28B) parameters. These parameters are like the internal settings of the model, helping it learn and process data effectively. It also supports different image resolutions (e.g., 224 x 224 pixels for quick tasks and 896 x 896 for detailed analysis), making it adaptable for various applications.
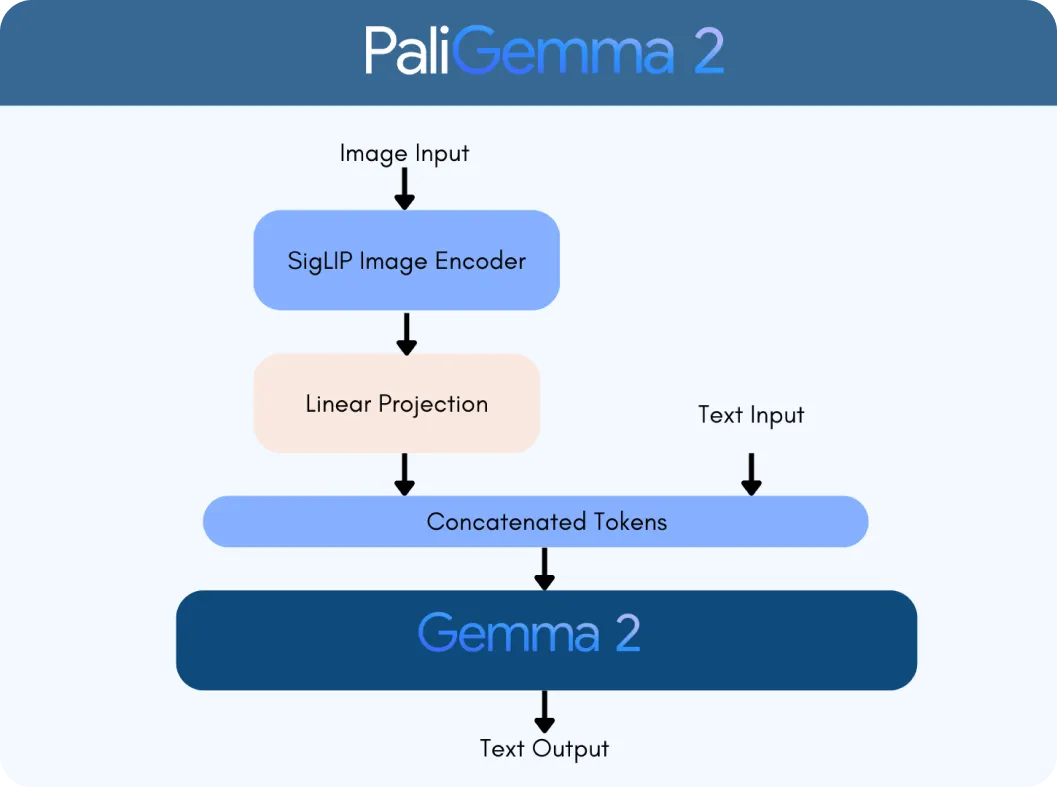
Integrating Gemma 2’s advanced language capabilities with SigLIP’s image processing makes PaliGemma 2 significantly more intelligent. It can handle tasks like:
PaliGemma 2 goes beyond processing images and text separately - it brings them together in meaningful ways. For example, it can understand relationships in a scene, like recognizing that “The cat is sitting on the table,” or identifying objects while adding context, like recognizing a famous landmark.
Next, we’ll walk through an example using the graph shown in the image below to get a better understanding of how PaliGemma 2 processes visual and textual data. Let’s say you upload this graph and ask the model, “What does this graph represent?

The process begins with PaliGemma 2’s SigLIP vision encoder to analyze images and extract key features. For a graph, this includes identifying elements like axes, data points, and labels. The encoder is trained to capture both broad patterns and fine details. It also uses optical character recognition (OCR) to detect and process any text embedded in the image. These visual features are converted into tokens, which are numerical representations that the model can process. These tokens are then adjusted using a linear projection layer, a technique that ensures they can be combined seamlessly with textual data.
At the same time, the Gemma 2 language model processes the accompanying query to determine its meaning and intent. The text from the query is converted into tokens, and these are combined with the visual tokens from SigLIP to create a multimodal representation, a unified format that links visual and textual data.
Using this integrated representation, PaliGemma 2 generates a response step-by-step through autoregressive decoding, a method where the model predicts one part of the answer at a time based on the context it has already processed.
Now that we have understood how it works, let’s explore the key features that make PaliGemma 2 a reliable vision-language model:
Taking a look at the architecture of the first version of PaliGemma is a good way to see PaliGemma 2’s enhancements. One of the most notable changes is the replacement of the original Gemma language model with Gemma 2, which brings substantial improvements in both performance and efficiency.
Gemma 2, available in 9B and 27B parameter sizes, was engineered to deliver class-leading accuracy and speed while reducing deployment costs. It achieves this through a redesigned architecture optimized for inference efficiency across various hardware setups, from powerful GPUs to more accessible configurations.
As a result, PaliGemma 2 is a highly accurate model. The 10B version of PaliGemma 2 achieves a lower Non-Entailment Sentence (NES) score of 20.3, compared to the original model’s 34.3, meaning fewer factual errors in its outputs. These advancements make PaliGemma 2 more scalable, precise, and adaptable to a wider range of applications, from detailed captioning to visual question answering.
PaliGemma 2 has the potential to redefine industries by seamlessly combining visual and language understanding. For example, with regard to accessibility, it can generate detailed descriptions of objects, scenes, and spatial relationships, providing crucial assistance to visually impaired individuals. This capability helps users understand their environments better, offering greater independence when it comes to everyday tasks.

In addition to accessibility, PaliGemma 2 is making an impact across various industries, including:
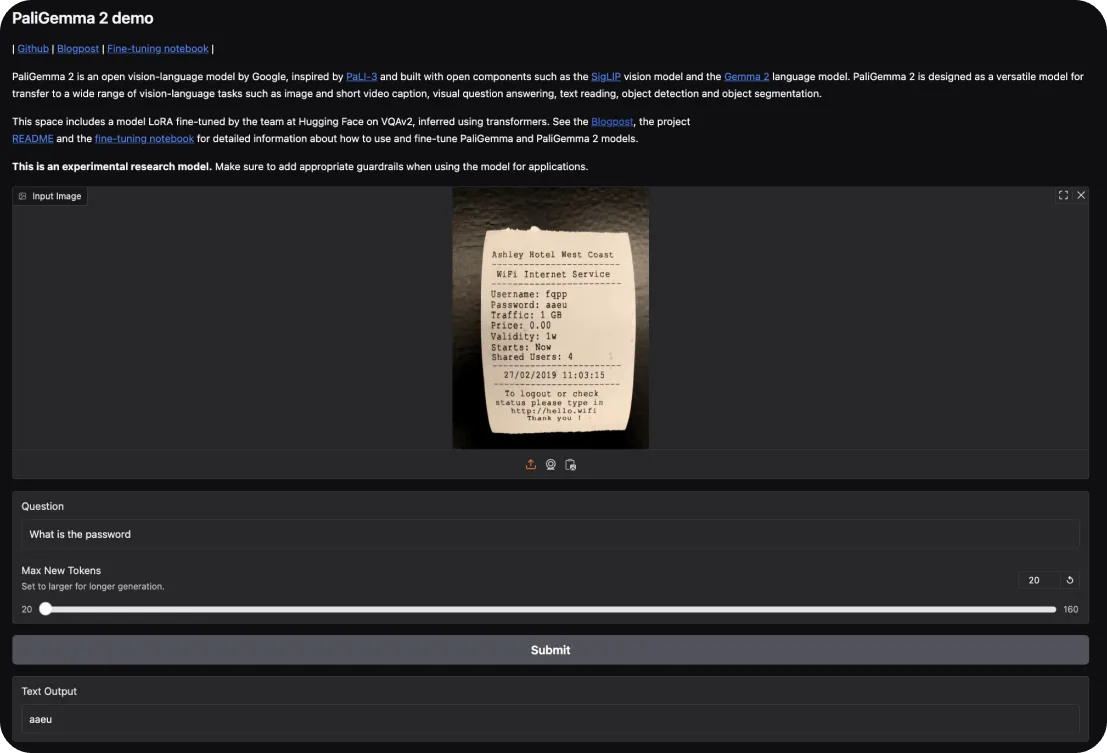
To try out PaliGemma 2, you can start with Hugging Face’s interactive demo. It lets you explore its capabilities in tasks like image captioning and visual question answering. Simply upload an image and ask the model questions about it or request a description of the scene.
If you’d like to dive deeper, here’s how you can get hands-on:
Having understood how to get started with PaliGemma 2, let’s take a closer look at its key strengths and drawbacks to keep in mind when using these models.
Here’s what makes PaliGemma 2 stand out as a vision-language model:
Meanwhile, here are some areas where PaliGemma 2 may face limitations:
PaliGemma 2 is a fascinating advancement in vision-language modeling, offering improved scalability, fine-tuning flexibility, and accuracy. It can serve as a valuable tool for applications ranging from accessibility solutions and e-commerce to healthcare diagnostics and education.
While it does have limitations, such as computational requirements and a dependency on high-quality data, its strengths make it a practical choice for tackling complex tasks that integrate visual and textual data. PaliGemma 2 can provide a robust foundation for researchers and developers to explore and expand the potential of AI in multimodal applications.
Become a part of the AI conversation by checking out our GitHub repository and community. Read about how AI is making strides in agriculture and healthcare! 🚀


