



Learn how Mask R-CNN can be used to precisely segment objects in images and videos for various applications across different sectors.

Learn how Mask R-CNN can be used to precisely segment objects in images and videos for various applications across different sectors.
Innovations like robots in warehouses, self-driving cars safely moving through busy streets, drones checking on crops, and AI systems inspecting products in factories are becoming more common as AI adoption increases. A key technology driving these innovations is computer vision, a branch of AI that enables machines to understand and interpret visual data.
For example, object detection is a computer vision task that helps identify and locate objects in images using bounding boxes. While bounding boxes offer helpful information, they only provide a rough estimate of an object’s position and can’t capture its exact shape or boundaries. This makes them less effective in applications that require precise identification.
To solve this problem, researchers developed segmentation models that capture the exact contours of objects, providing pixel-level details for more accurate detection and analysis.
Mask R-CNN is one of these models. Introduced in 2017 by Facebook AI Research (FAIR), it builds on earlier models like R-CNN, Fast R-CNN, and Faster R-CNN. As an important milestone in the history of computer vision, Mask R-CNN has paved the way for more advanced models, such as Ultralytics YOLO11.
In this article, we’ll explore what Mask R-CNN is, how it works, its applications, and what improvements came after it, leading to YOLO11.
Mask R-CNN, which stands for Mask Region-based Convolutional Neural Network, is a deep learning model that is designed for computer vision tasks like object detection and instance segmentation.
Instance segmentation goes beyond traditional object detection by not only identifying objects in an image but also accurately outlining each one. It assigns a unique label to every detected object and captures its exact shape at the pixel level. This detailed approach makes it possible to clearly distinguish between overlapping objects and to accurately handle complex shapes.
Mask R-CNN builds on Faster R-CNN, which detects and labels objects but does not define their exact shapes. Mask R-CNN improves on this by identifying the exact pixels that make up each object, allowing for much more detailed and accurate image analysis.

Mask R-CNN takes a step-by-step approach to detect and segment objects accurately. It starts by extracting key features using a deep neural network (a multi-layered model that learns from data), then identifies potential object areas with a region proposal network (a component that suggests likely object regions), and finally refines these areas by creating detailed segmentation masks (precise outlines of objects) that capture each object's exact shape.
Next, we'll walk through each step to get a better idea of how Mask R-CNN works.
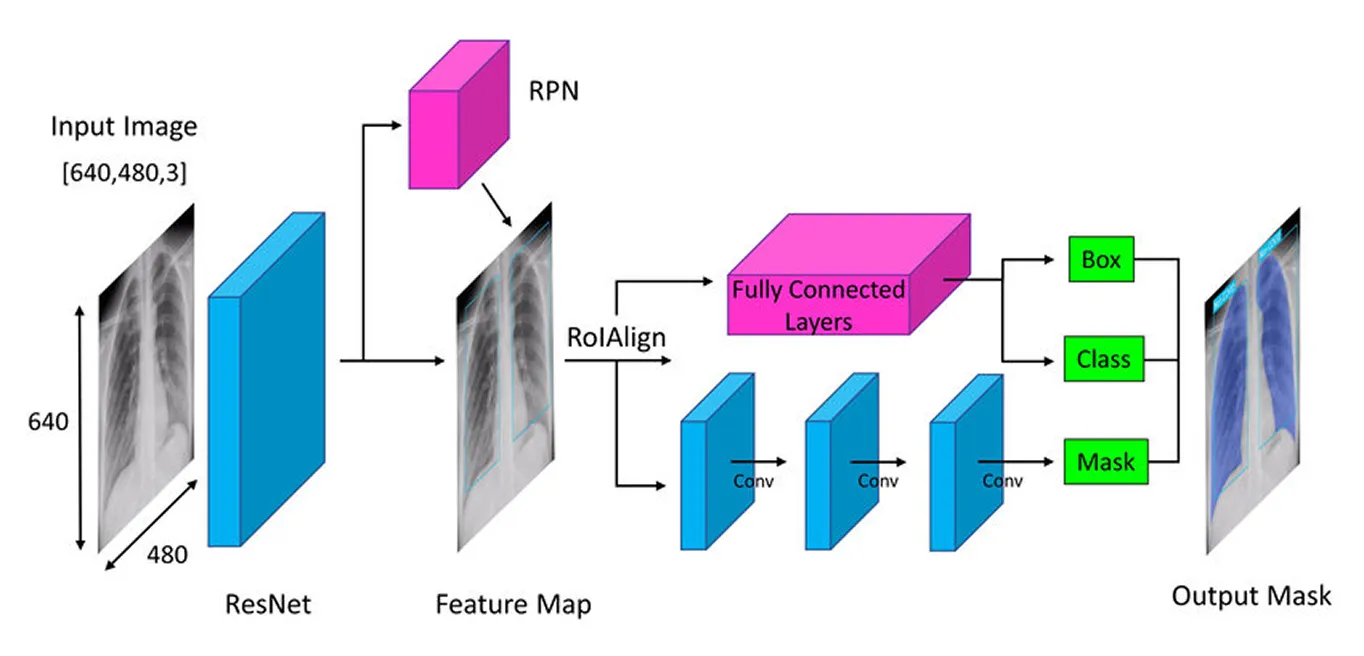
The first step in Mask R-CNN’s architecture is to break the image down into its key parts so the model can understand what's in it. Think of it like when you look at a photo and naturally notice details like shapes, colors, and edges. The model does something similar using a deep neural network called a "backbone" (often ResNet-50 or ResNet-101), which acts like its eyes to scan the image and pick up on key details.
Since objects in images can be very small or very large, Mask R-CNN uses a Feature Pyramid Network. This is like having different magnifying glasses that let the model see both fine details and the bigger picture, ensuring that objects of all sizes are noticed.
Once these important features are extracted, the model then moves on to locate the potential objects in the image, setting the stage for further analysis.
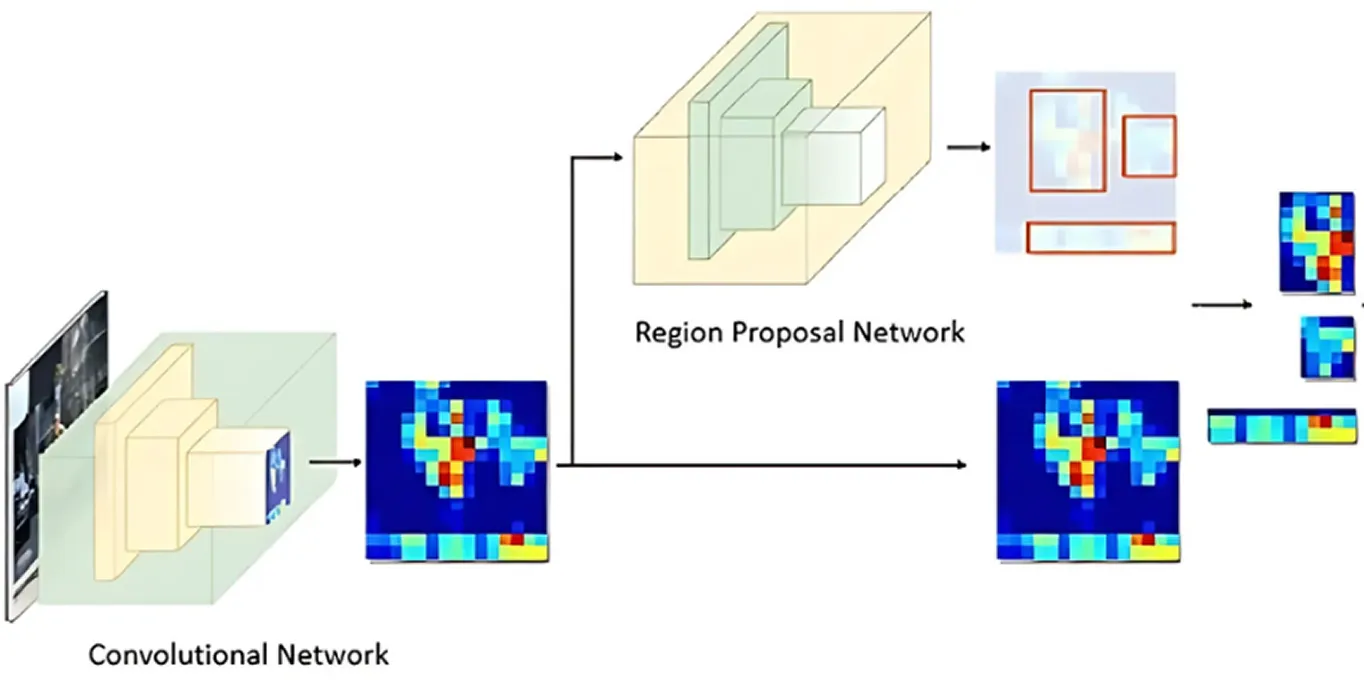
After the image has been processed for key features, the Region Proposal Network takes over. This part of the model looks at the image and suggests areas that are likely to contain objects.
It does this by generating multiple possible object locations called anchors. The network then evaluates these anchors and selects the most promising ones for further analysis. This way, the model focuses only on the areas most likely to be interesting, rather than checking every single spot in the image.
With the key areas identified, the next step is to refine the details extracted from these regions. Earlier models used a method called ROI Pooling (Region of Interest Pooling) to grab features from each area, but this technique sometimes led to slight misalignments when resizing regions, making it less effective - especially for smaller or overlapping objects.
Mask R-CNN improves on this by using a technique referred to as ROI Align (Region of Interest Align). Instead of rounding off coordinates like ROI Pooling does, ROI Align uses bilinear interpolation to estimate pixel values more precisely. Bilinear interpolation is a method that calculates a new pixel value by averaging the values of its four nearest neighbors, which creates smoother transitions. This keeps the features properly aligned with the original image, resulting in more accurate object detection and segmentation.
For example, in a football match, two players standing close together might be mistaken for one another because their bounding boxes overlap. ROI Align helps separate them by keeping their shapes distinct.
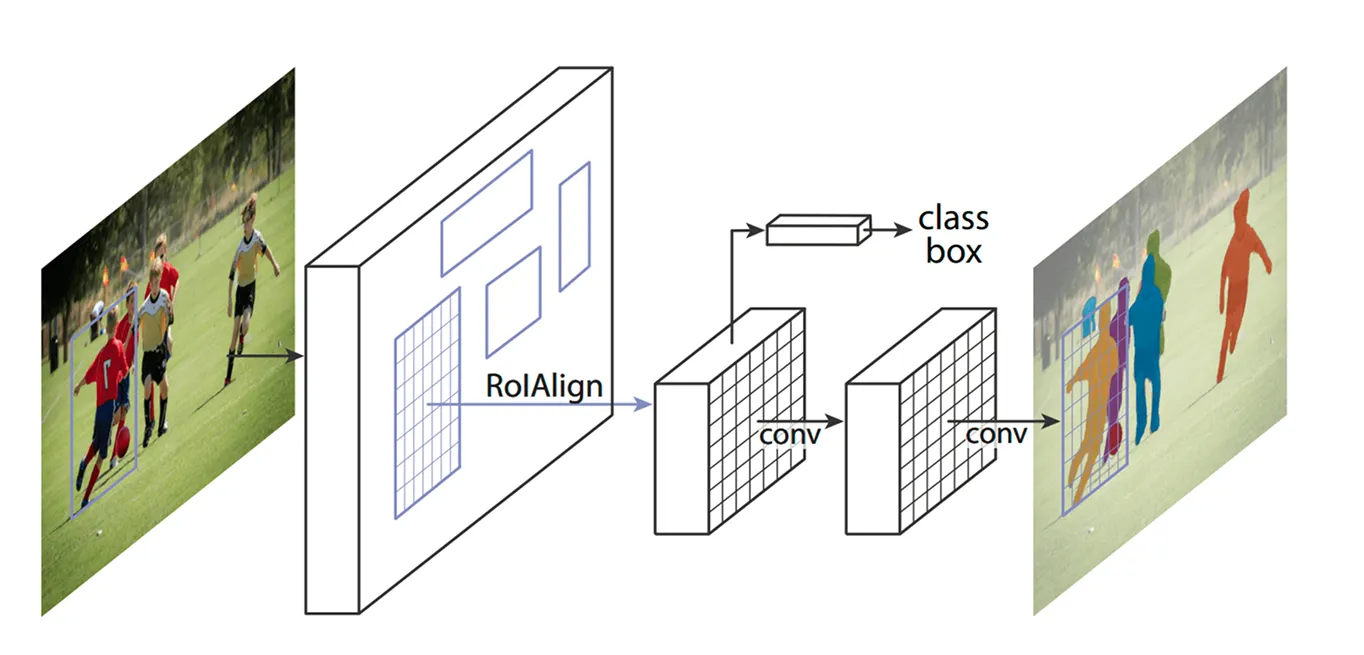
Once ROI Align processes the image, the next step is to classify objects and fine-tune their locations. The model looks at each extracted region and decides what object it contains. It assigns a probability score to different categories and picks the best match.
At the same time, it adjusts the bounding boxes to better fit the objects. The initial boxes may not be ideally placed, so this helps improve accuracy by making sure each box tightly surrounds the detected object.
Finally, Mask R-CNN takes an extra step: it generates a detailed segmentation mask for each object in parallel.
When this model came out, it was met with a lot of excitement from the AI community and was soon used in various applications. Its ability to detect and segment objects in real time made it a game changer across different industries.
For example, tracking endangered animals in the wild is a challenging task. Many species move through dense forests, making it hard for conservationists to keep track of them. Traditional methods use camera traps, drones, and satellite images, but sorting through all this data by hand is time-consuming. Misidentifications and missed sightings can slow down conservation efforts.
By recognizing unique features like tiger stripes, giraffe spots, or the shape of an elephant’s ears, Mask R-CNN can detect and segment animals in images and videos with greater accuracy. Even when animals are partly hidden by trees or standing close together, the model can separate them and identify each one individually, making wildlife monitoring faster and more reliable.

Despite its historical significance in object detection and segmentation, Mask R-CNN also comes with some key drawbacks. Here are some challenges related to Mask R-CNN:
Mask R-CNN was great for segmentation tasks, but many industries were looking to adopt computer vision while prioritizing speed and real-time performance. This requirement led researchers to develop one-stage models that detect objects in a single pass, greatly improving efficiency.
Unlike Mask R-CNN’s multi-step process, one-stage computer vision models like YOLO (You Only Look Once) focus on real-time computer vision tasks. Instead of handling detection and segmentation separately, YOLO models can analyze an image in one go. This makes it ideal for applications such as autonomous driving, healthcare, manufacturing, and robotics, where fast decision-making is crucial.
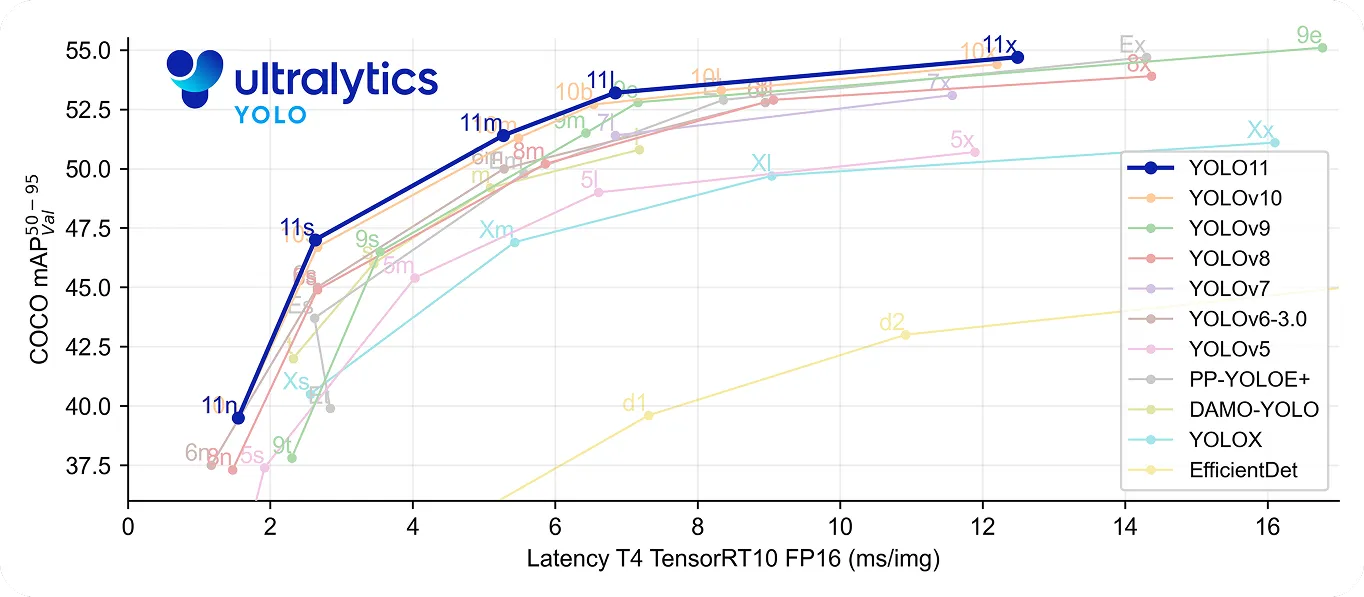
In particular, YOLO11 takes this a step further by being both fast and accurate. It uses 22% fewer parameters than YOLOv8m but still achieves a higher mean average precision (mAP) on the COCO dataset, meaning it detects objects more precisely. Its improved processing speed makes it a good choice for real-time applications where every millisecond matters.
Looking back at the history of computer vision, Mask R-CNN is recognized as a major breakthrough in object detection and segmentation. It delivers very precise results even in complex settings, thanks to its detailed multi-step process.
However, this same process makes it slower compared to real-time models like YOLO. As the need for speed and efficiency grows, many applications now use one-stage models like Ultralytics YOLO11, which offer fast and accurate object detection. While Mask R-CNN is important with respect to understanding the evolution of computer vision, the trend toward real-time solutions highlights the growing demand for quicker and more efficient computer vision solutions.
Join our growing community! Explore our GitHub repository to learn more about AI. Ready to start your own computer vision projects? Check out our licensing options. Discover AI in agriculture and Vision AI in healthcare by visiting our solutions pages!


