


Erkundung der Funktionsweise von Computer Vision Anwendungen

Tauchen Sie mit uns tief in die Anwendungen von Computer Vision ein. Wir werden auch verschiedene Computer-Vision-Aufgaben wie Objekterkennung und Segmentierung durchgehen.

Tauchen Sie mit uns tief in die Anwendungen von Computer Vision ein. Wir werden auch verschiedene Computer-Vision-Aufgaben wie Objekterkennung und Segmentierung durchgehen.
Als wir uns mit der Geschichte der Computer-Vision-Modelle befasst haben, haben wir gesehen, wie sich die Computer-Vision entwickelt hat und welcher Weg zu den fortschrittlichen Vision-Modellen geführt hat, die wir heute haben. Moderne Modelle wie Ultralytics YOLOv8 unterstützen mehrere Computer-Vision-Aufgaben und werden in verschiedenen spannenden Anwendungen eingesetzt.
In diesem Artikel werfen wir einen Blick auf die Grundlagen von Computer Vision und Vision-Modellen. Wir werden behandeln, wie sie funktionieren und welche vielfältigen Anwendungen sie in verschiedenen Branchen haben. Innovationen im Bereich Computer Vision sind allgegenwärtig und gestalten unsere Welt im Stillen. Lasst sie uns nacheinander aufdecken!
Künstliche Intelligenz (KI) ist ein Überbegriff, der viele Technologien umfasst, die darauf abzielen, einen Teil der menschlichen Intelligenz nachzubilden. Ein solches Teilgebiet der KI ist Computer Vision. Computer Vision konzentriert sich darauf, Maschinen Augen zu geben, die ihre Umgebung sehen, beobachten und verstehen können.
Genau wie beim menschlichen Sehen geht es bei Computer-Vision-Lösungen darum, Objekte zu unterscheiden, Entfernungen zu berechnen und Bewegungen detect . Im Gegensatz zum Menschen, der über lebenslange Erfahrungen verfügt, die ihm beim Sehen und Verstehen helfen, sind Computer jedoch auf riesige Datenmengen, hochauflösende Kameras und komplexe Algorithmen angewiesen.
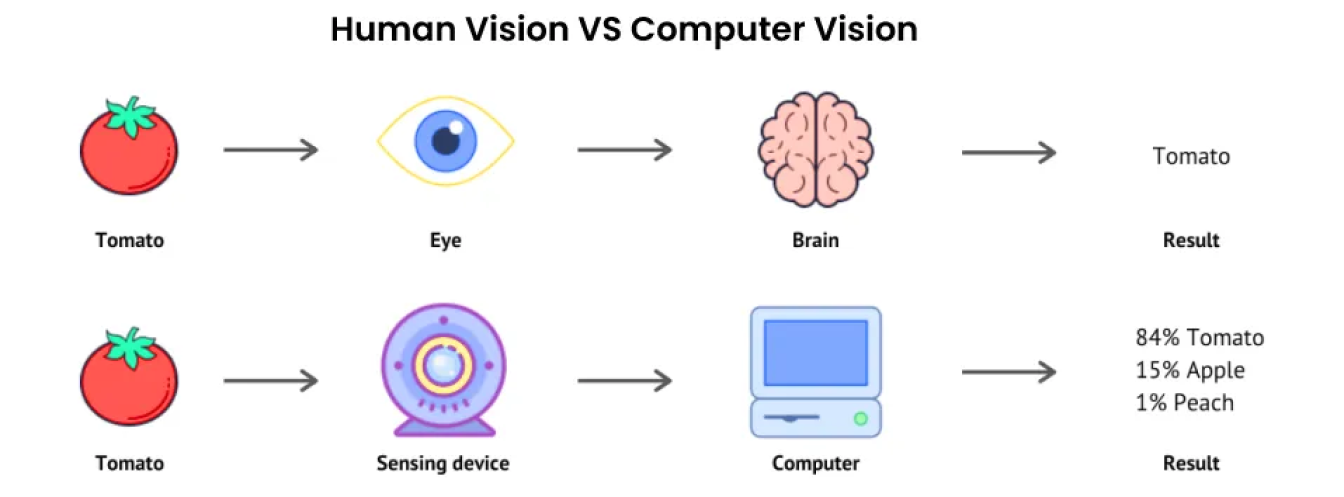
Computer-Vision-Systeme können visuelle Daten wie Bilder und Videos mit unglaublicher Geschwindigkeit und Genauigkeit verarbeiten und analysieren. Die Fähigkeit, riesige Mengen an visuellen Informationen schnell und genau zu analysieren, macht Computer Vision zu einem leistungsstarken Werkzeug in verschiedenen Branchen, von der Fertigung bis zum Gesundheitswesen.
Computer-Vision-Modelle sind der Kern jeder Computer-Vision-Anwendung. Im Wesentlichen handelt es sich um Rechenalgorithmen, die auf Deep-Learning-Techniken basieren und darauf ausgelegt sind, Maschinen die Fähigkeit zu geben, visuelle Informationen zu interpretieren und zu verstehen. Vision-Modelle ermöglichen entscheidende Computer-Vision-Aufgaben, die von der Bildklassifizierung bis zur Objekterkennung reichen. Werfen wir einen genaueren Blick auf einige dieser Aufgaben und ihre Anwendungsfälle im Detail.
Bei der Bildklassifizierung geht es um die Einteilung und Kennzeichnung von Bildern in vordefinierte Klassen oder Kategorien. Ein Bildverarbeitungsmodell wie YOLOv8 kann auf großen Datensätzen mit beschrifteten Bildern trainiert werden. Während des Trainings lernt das Modell, die mit jeder Klasse verbundenen Muster und Merkmale zu erkennen. Einmal trainiert, kann es die Kategorie neuer, ungesehener Bilder vorhersagen, indem es deren Merkmale analysiert und mit den gelernten Mustern vergleicht.
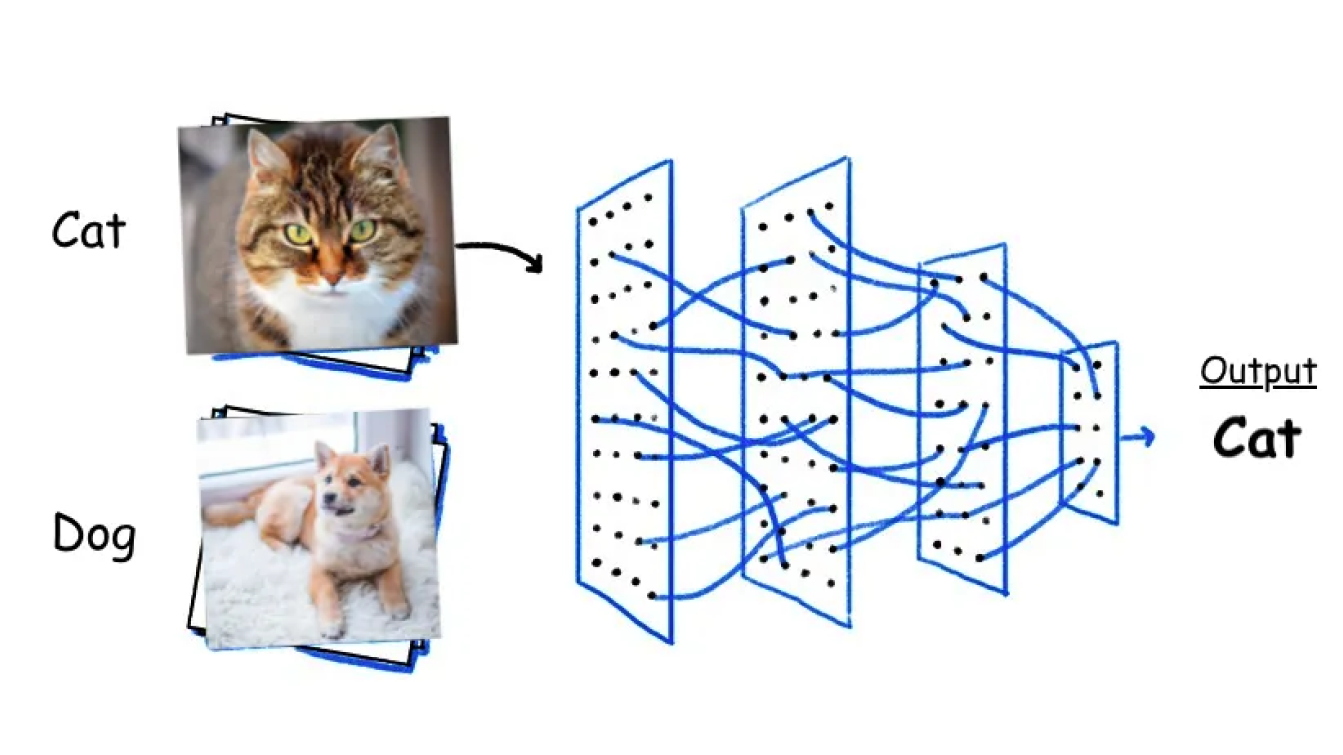
Es gibt verschiedene Arten der Bildklassifizierung. Bei medizinischen Bildern kann man beispielsweise die binäre Klassifizierung verwenden, um die Bilder in zwei Gruppen einzuteilen, z. B. gesund oder krank. Eine andere Art ist die Multiklassenklassifizierung. Sie kann dabei helfen, Bilder in viele Gruppen classify , z. B. die verschiedenen Tiere auf einem Bauernhof wie Schweine, Ziegen und Kühe zu klassifizieren. Wenn Sie Tiere in Gruppen und Untergruppen classify möchten, z. B. in Säugetiere und Vögel und dann weiter in Arten wie Löwen, Tiger, Adler und Spatzen, ist die hierarchische Klassifizierung die beste Option.
Objekterkennung ist der Prozess der Identifizierung und Lokalisierung von Objekten in Bildern und Videoframes mithilfe von Computer Vision. Sie besteht aus zwei Aufgaben: der Objektlokalisierung, die Begrenzungsrahmen um Objekte zeichnet, und der Objektklassifizierung, die die Kategorie jedes Objekts identifiziert. Basierend auf den Begrenzungsrahmen-Annotationen kann ein Vision-Modell lernen, Muster und Merkmale zu erkennen, die für jede Objektkategorie spezifisch sind, und das Vorhandensein und die Position dieser Objekte in neuen, unbekannten Bildern vorhersagen.
.png)
Die Objekterkennung hat viele Anwendungsfälle in verschiedenen Branchen, von Sport bis hin zur Meeresbiologie. Zum Beispiel verwendet die Just Walk Out-Technologie von Amazon im Einzelhandel die Objekterkennung, um den Bezahlvorgang zu automatisieren, indem sie die Artikel identifiziert, die Kunden aufnehmen. Eine Kombination aus Computer Vision und Sensordaten ermöglicht es den Kunden, ihre Artikel zu nehmen und zu gehen, ohne in der Schlange zu warten.
Hier ist eine genauere Betrachtung der Funktionsweise:
Semantische Segmentierung und Instanzsegmentierung sind Computer-Vision-Aufgaben, die helfen, Bilder in sinnvolle Segmente zu unterteilen. Die semantische Segmentierung klassifiziert Pixel basierend auf ihrer semantischen Bedeutung und behandelt alle Objekte innerhalb einer Kategorie als eine einzige Entität mit derselben Bezeichnung. Sie eignet sich zur Kennzeichnung von unzählbaren Objekten wie "der Himmel" oder "Ozean" oder Clustern wie "Blätter" oder "Gras".
Die Instanzsegmentierung hingegen kann verschiedene Instanzen derselben Klasse unterscheiden, indem sie jedem erkannten Objekt eine eindeutige Bezeichnung zuweist. Sie können die Instanzsegmentierung verwenden, um zählbare Objekte zu segment , bei denen die Anzahl und die Unabhängigkeit der Objekte wichtig sind. Sie ermöglicht eine genauere Identifizierung und Unterscheidung.
.png)
Der Unterschied zwischen semantischer und instanzieller Segmentierung lässt sich anhand eines Beispiels aus dem Bereich der selbstfahrenden Autos besser verstehen. Die semantische Segmentierung eignet sich hervorragend für Aufgaben, die ein Verständnis des Inhalts einer Szene erfordern, und kann in autonomen Fahrzeugen zur classify Merkmalen auf der Straße, wie Fußgängerüberwegen und Verkehrsschildern, verwendet werden. Die Instanzsegmentierung kann in autonomen Fahrzeugen dazu verwendet werden, zwischen einzelnen Fußgängern, Fahrzeugen und Hindernissen zu unterscheiden.
Pose-Schätzung ist eine Aufgabe der Computer Vision, die sich auf das Erkennen und Verfolgen von Schlüsselpunkten der Posen eines Objekts in Bildern oder Videos konzentriert. Sie wird am häufigsten für die Schätzung der menschlichen Pose verwendet, wobei Schlüsselpunkte Bereiche wie Schultern und Knie umfassen. Die Schätzung der Pose eines Menschen hilft uns, Handlungen und Bewegungen zu verstehen und zu erkennen, die für verschiedene Anwendungen entscheidend sind.

Die Pose-Schätzung kann im Sport verwendet werden, um die Bewegungen von Athleten zu analysieren. Die NBA nutzt die Pose-Schätzung, um die Bewegungen und Positionen der Spieler während des Spiels zu untersuchen. Durch die Verfolgung von Schlüsselpunkten wie Schultern, Ellbogen, Knien und Knöcheln liefert die Pose-Schätzung detaillierte Einblicke in die Spielerbewegungen. Diese Erkenntnisse helfen Trainern, bessere Strategien zu entwickeln, Trainingsprogramme zu optimieren und Echtzeit-Anpassungen während des Spiels vorzunehmen. Darüber hinaus können die Daten helfen, die Ermüdung der Spieler und das Verletzungsrisiko zu überwachen, um die allgemeine Gesundheit und Leistung der Spieler zu verbessern.
Oriented Bounding Boxes Object Detection (OBB) (Objekterkennung mit ausgerichteten Begrenzungsrahmen) verwendet gedrehte Rechtecke, um Objekte in einem Bild präzise zu identifizieren und zu lokalisieren. Im Gegensatz zu Standard-Begrenzungsrahmen, die an den Bildachsen ausgerichtet sind, werden OBBs gedreht, um der Ausrichtung des Objekts zu entsprechen. Dies macht sie besonders nützlich für Objekte, die nicht perfekt horizontal oder vertikal sind. Sie eignen sich hervorragend, um gedrehte Objekte genau zu lokalisieren und zu isolieren, um Überschneidungen in überfüllten Umgebungen zu vermeiden.
.png)
In der maritimen Überwachung ist die Identifizierung und Verfolgung von Schiffen entscheidend für die Sicherheit und das Ressourcenmanagement. Die OBB-Erkennung kann für die präzise Lokalisierung von Schiffen verwendet werden, selbst wenn diese dicht gedrängt oder in verschiedenen Winkeln ausgerichtet sind. Sie hilft bei der Überwachung von Schifffahrtswegen, der Verwaltung des Seeverkehrs und der Optimierung des Hafenbetriebs. Sie kann auch bei der Katastrophenhilfe unterstützen, indem sie Schäden an Schiffen und Infrastruktur nach Ereignissen wie Hurrikanen oder Ölverschmutzungen schnell identifiziert und bewertet.
Bisher haben wir uns mit Bildverarbeitungsaufgaben beschäftigt, die sich mit Bildern befassen. Bei der Objektverfolgung handelt es sich um eine Bildverarbeitungsaufgabe, mit der ein Objekt über die einzelnen Bilder eines Videos hinweg track kann. Zunächst wird das Objekt im ersten Bild mit Hilfe von Erkennungsalgorithmen identifiziert, und dann wird seine Position kontinuierlich verfolgt, während es sich durch das Video bewegt. Die Objektverfolgung umfasst Techniken wie Objekterkennung, Merkmalsextraktion und Bewegungsvorhersage, um die Verfolgung genau zu halten.

Bildverarbeitungsmodelle wie YOLOv8 können in der Meeresbiologie zur track von Fischen eingesetzt werden. Mit Unterwasserkameras können Forscher die Bewegungen und das Verhalten von Fischen in ihren natürlichen Lebensräumen überwachen. Der Prozess beginnt mit der Erkennung einzelner Fische in den ersten Bildern und verfolgt dann ihre Position im gesamten Video. Die Verfolgung von Fischen hilft Wissenschaftlern, Migrationsmuster, soziales Verhalten und Interaktionen mit der Umwelt zu verstehen. Außerdem unterstützt es nachhaltige Fischereipraktiken, indem es Einblicke in die Verteilung und den Bestand von Fischen gibt.
Computer Vision verändert aktiv die Art und Weise, wie wir Technologie nutzen und mit der Welt interagieren. Durch die Verwendung von Deep-Learning-Modellen und komplexen Algorithmen zum Verständnis von Bildern und Videos hilft Computer Vision den Industrien, viele Prozesse zu rationalisieren. Computer-Vision-Aufgaben wie Objekterkennung und Objektverfolgung ermöglichen es, Lösungen zu entwickeln, die man sich bisher nicht vorstellen konnte. Da sich die Computer-Vision-Technologie ständig verbessert, hält die Zukunft noch viele weitere innovative Anwendungen bereit!
Lasst uns gemeinsam lernen und wachsen! Entdecken Sie unser GitHub-Repository, um unsere Beiträge zur KI zu sehen. Sehen Sie sich an, wie wir Branchen wie selbstfahrende Autos und Landwirtschaft mit KI neu definieren. 🚀
.webp)

.webp)