Al hacer clic en “Aceptar todas las cookies”, aceptas el almacenamiento de cookies en tu dispositivo para mejorar la navegación del sitio, analizar el uso del sitio y ayudar en nuestros esfuerzos de marketing. Más información
Configuración de cookies
Al hacer clic en “Aceptar todas las cookies”, aceptas el almacenamiento de cookies en tu dispositivo para mejorar la navegación del sitio, analizar el uso del sitio y ayudar en nuestros esfuerzos de marketing. Más información
Explore la nueva familia de modelos de código abierto Llama 3.1 de Meta, que incluye el versátil 8B, el completo 70B y el insignia 405B, su modelo más grande y avanzado hasta la fecha.
El 23 de julio de 2024, Meta lanzó la nueva familia de modelos de código abierto Llama 3.1, que incluye el versátil 8B, el capaz 70B y los modelos Llama 3.1 405B, destacando este último como el modelo de lenguaje grande (LLM) de código abierto más grande hasta la fecha.
Puede que se pregunte qué diferencia a estos nuevos modelos de sus predecesores. Bueno, a medida que profundicemos en este artículo, descubrirá que el lanzamiento de los modelos Llama 3.1 marca un hito significativo en la tecnología de IA. Los modelos recién lanzados ofrecen mejoras significativas en el procesamiento del lenguaje natural; además, introducen nuevas características y mejoras que no se encuentran en versiones anteriores. Este lanzamiento promete cambiar la forma en que aprovechamos la IA para tareas complejas, proporcionando un potente conjunto de herramientas para investigadores y desarrolladores por igual.
En este artículo, exploraremos la familia de modelos Llama 3.1, profundizando en su arquitectura, mejoras clave, usos prácticos y una comparación detallada de su rendimiento.
¿Qué es Llama 3.1?
El último gran modelo lingüístico de Meta, Llama 3.1, está avanzando a pasos agigantados en el panorama de la IA, rivalizando con las capacidades de modelos de primer nivel como Chat GPT-4o de OpenAI y Claude 3.5 Sonnet de Anthropic.
Aunque pueda considerarse una actualización menor del modelo anterior Llama 3, Meta lo ha llevado un paso más allá introduciendo algunas mejoras clave en la nueva familia de modelos, ofreciendo:
Compatible con ocho idiomas: Entre ellos, English, alemán, francés, italiano, portugués, hindi, español y tailandés, lo que amplía su alcance a un público mundial.
128.000 tokens de ventana de contexto: Permiten que los modelos gestionen entradas mucho más largas y mantengan el contexto durante conversaciones o documentos extensos.
Mejores capacidades de razonamiento: Permite que los modelos sean más versátiles y capaces de gestionar tareas complejas de forma eficaz.
Seguridad rigurosa: Se han implementado pruebas para mitigar los riesgos, reducir los sesgos y prevenir los resultados perjudiciales, promoviendo el uso responsable de la IA.
Además de todo lo anterior, la nueva familia de modelos Llama 3.1 destaca un gran avance con su impresionante modelo de 405.000 millones de parámetros. Este importante número de parámetros representa un gran avance en el desarrollo de la inteligencia artificial y mejora enormemente la capacidad del modelo para comprender y generar textos complejos. El modelo 405B incluye una amplia gama de parámetros, cada uno de los cuales hace referencia a los weights and biases de la red neuronal que el modelo aprende durante el entrenamiento. Esto permite al modelo captar patrones lingüísticos más intrincados, estableciendo un nuevo estándar para los grandes modelos lingüísticos y mostrando el potencial futuro de la tecnología de IA. Este modelo a gran escala no sólo mejora el rendimiento en una amplia gama de tareas, sino que también amplía los límites de lo que la IA puede lograr en términos de generación y comprensión de textos.
Arquitectura del modelo
Llama 3.1 aprovecha la arquitectura de modelo transformer de solo decodificador, una piedra angular para los modelos de lenguaje grandes modernos. Esta arquitectura es reconocida por su eficiencia y eficacia en el manejo de tareas complejas de lenguaje. El uso de transformers permite a Llama 3.1 sobresalir en la comprensión y generación de texto similar al humano, proporcionando una ventaja significativa sobre los modelos que utilizan arquitecturas más antiguas como LSTM y GRU.
Además, la familia de modelos Llama 3.1 utiliza la arquitectura Mixture of Experts (MoE), que mejora la eficiencia y la estabilidad del entrenamiento. Evitar la arquitectura MoE asegura un proceso de entrenamiento más consistente y fiable, ya que MoE a veces puede introducir complejidades que pueden impactar la estabilidad y el rendimiento del modelo.
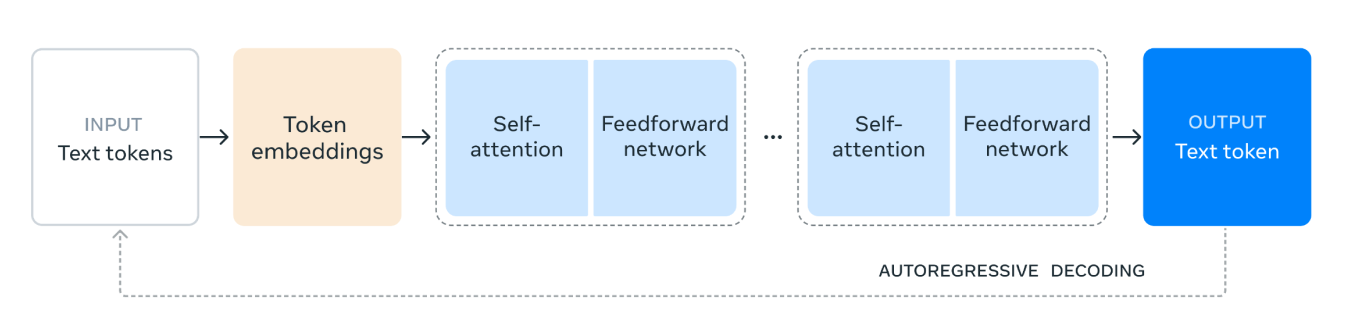
Fig. 1. Un diagrama que ilustra la arquitectura del modelo transformer Llama 3.1.
La arquitectura del modelo Llama 3.1 funciona de la siguiente manera:
1. Tokens de texto de entrada: El proceso comienza con la entrada, que consiste en tokens de texto. Estos tokens son unidades individuales de texto, como palabras o subpalabras, que el modelo procesará.
2. Incrustaciones de tokens: Los tokens de texto se convierten entonces en incrustaciones de tokens. Las incrustaciones son representaciones vectoriales densas de los tokens que capturan su significado semántico y sus relaciones dentro del texto. Esta transformación es crucial, ya que permite al modelo trabajar con datos numéricos.
3. Mecanismo de autoatención: La autoatención permite al modelo ponderar la importancia de diferentes tokens en la secuencia de entrada al codificar cada token. Este mecanismo ayuda al modelo a comprender el contexto y las relaciones entre los tokens, independientemente de sus posiciones en la secuencia. En el mecanismo de autoatención, cada token en la secuencia de entrada se representa como un vector de números. Estos vectores se utilizan para crear tres tipos diferentes de representaciones: consultas, claves y valores.
El modelo calcula cuánta atención debe prestar cada token a otros tokens comparando los vectores de consulta con los vectores clave. Esta comparación da como resultado puntuaciones que indican la relevancia de cada token en relación con los demás.
4. Red de alimentación: Tras el proceso de autoatención, los datos pasan por una red de alimentación. Esta red es una red neuronal totalmente conectada que aplica transformaciones no lineales a los datos, lo que ayuda al modelo a reconocer y aprender patrones complejos.
5. Capas repetidas: Las capas de autoatención y de red neuronal feedforward se apilan varias veces. Esta aplicación repetida permite al modelo capturar dependencias y patrones más complejos en los datos.
6. Token de texto de salida: Finalmente, los datos procesados se utilizan para generar el token de texto de salida. Este token es la predicción del modelo para la siguiente palabra o subpalabra en la secuencia, basándose en el contexto de entrada.
Rendimiento de la familia de modelos LLama 3.1 y comparaciones con otros modelos
Las pruebas de referencia revelan que Llama 3.1 no solo se mantiene a la altura de estos modelos de última generación, sino que también los supera en ciertas tareas, lo que demuestra su rendimiento superior.
Llama 3.1 405B: Alta capacidad
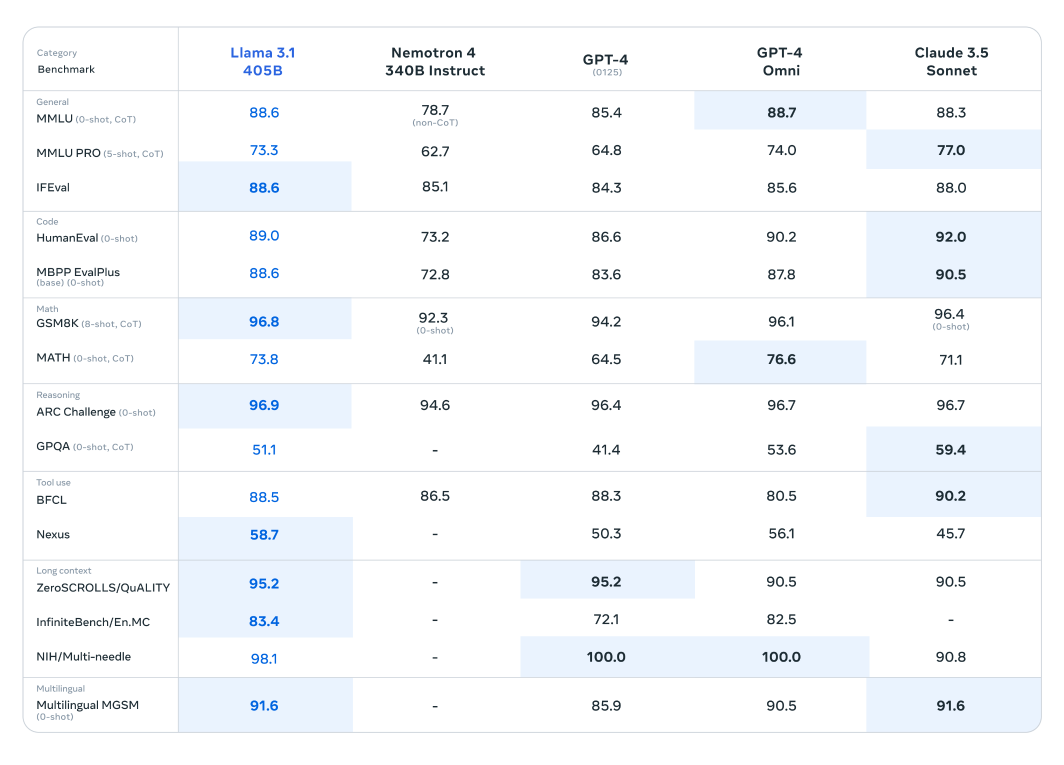
El modelo Llama 3.1 se ha sometido a una evaluación exhaustiva en más de 150 conjuntos de datos de referencia, donde se ha comparado rigurosamente con otros modelos de lenguaje grandes líderes. El modelo Llama 3.1 405B, reconocido como el más capaz de la serie recién lanzada, se ha comparado con titanes de la industria como GPT-4 de OpenAI y Claude 3.5 Sonnet. Los resultados de estas comparaciones revelan que Llama 3.1 demuestra una ventaja competitiva, mostrando su rendimiento y capacidades superiores en diversas tareas.
Fig 2. Una tabla que compara el rendimiento del modelo Llama 3.1 405B con modelos similares.
El impresionante número de parámetros y la arquitectura avanzada de este modelo le permiten sobresalir en la comprensión compleja y la generación de texto, a menudo superando a sus competidores en benchmarks específicos. Estas evaluaciones resaltan el potencial de Llama 3.1 para establecer nuevos estándares en el campo de los modelos de lenguaje grandes, proporcionando a investigadores y desarrolladores una herramienta poderosa para diversas aplicaciones.
Llama 3.1 70B: Gama media
Los modelos Llama, más pequeños y ligeros, también demuestran un rendimiento notable en comparación con sus homólogos. El modelo Llama 3.1 70B se ha evaluado con modelos más grandes como Mistral 8x22B y GPT-3.5 Turbo. Por ejemplo, el modelo Llama 3.1 70B demuestra sistemáticamente un rendimiento superior en los conjuntos de datos de razonamiento, como el conjunto de datos ARC Challenge, y en los conjuntos de datos de codificación, como el conjunto de datos HumanEval. Estos resultados destacan la versatilidad y robustez de la serie Llama 3.1 en diferentes tamaños de modelo, lo que la convierte en una herramienta valiosa para una amplia gama de aplicaciones.
Llama 3.1 8B: Ligero
Además, el modelo Llama 3.1 8B se ha comparado con modelos de tamaño similar, incluyendo Gemma 2 9B y Mistral 7B. Estas comparaciones revelan que el modelo Llama 3.1 8B supera a sus competidores en varios conjuntos de datos de referencia en diferentes géneros, como el conjunto de datos GPQA para el razonamiento y el MBPP EvalPlus para la codificación, mostrando su eficiencia y capacidad a pesar de su menor número de parámetros.
Fig. 3. Una tabla que compara el rendimiento de los modelos Llama 3.1 de 70B y 8B con modelos similares.
¿Cómo puede beneficiarse de los modelos de la familia Llama 3.1?
Meta ha permitido que los nuevos modelos se apliquen de diversas maneras prácticas y beneficiosas para los usuarios:
Ajuste fino
Los usuarios ahora pueden ajustar los últimos modelos Llama 3.1 para casos de uso específicos. Este proceso implica el entrenamiento del modelo con nuevos datos externos a los que no ha estado expuesto previamente, mejorando así su rendimiento y adaptabilidad para aplicaciones específicas. El ajuste fino proporciona al modelo una ventaja significativa al permitirle comprender y generar mejor contenido relevante para dominios o tareas específicos.
Integración en un sistema RAG
Los modelos Llama 3.1 ahora se pueden integrar perfectamente en sistemas de Generación Aumentada por Recuperación (RAG). Esta integración permite que el modelo aproveche las fuentes de datos externas de forma dinámica, mejorando su capacidad para proporcionar respuestas precisas y contextualmente relevantes. Al recuperar información de grandes conjuntos de datos e incorporarla al proceso de generación, Llama 3.1 mejora significativamente su rendimiento en tareas intensivas en conocimiento, ofreciendo a los usuarios resultados más precisos e informados.
Generación de datos sintéticos
También puede utilizar el modelo de 405 mil millones de parámetros para generar datos sintéticos de alta calidad, mejorando el rendimiento de modelos especializados para casos de uso específicos. Este enfoque aprovecha las amplias capacidades de Llama 3.1 para producir datos específicos y relevantes, mejorando así la precisión y eficiencia de las aplicaciones de IA personalizadas.
Conclusiones clave
El lanzamiento de Llama 3.1 representa un avance significativo en el campo de los modelos de lenguaje grandes, mostrando el compromiso de Meta con el avance de la tecnología de IA.
Con su considerable número de parámetros, su amplio entrenamiento en diversos conjuntos de datos y su enfoque en procesos de entrenamiento robustos y estables, Llama 3.1 establece nuevos puntos de referencia para el rendimiento y la capacidad en el procesamiento del lenguaje natural. Ya sea en la generación de texto, el resumen o las tareas conversacionales complejas, Llama 3.1 demuestra una ventaja competitiva sobre otros modelos líderes. Este modelo no solo supera los límites de lo que la IA puede lograr hoy en día, sino que también sienta las bases para futuras innovaciones en el panorama en constante evolución de la inteligencia artificial.
En Ultralytics, nos dedicamos a ampliar los límites de la tecnología de IA. Para explorar nuestras soluciones de IA de vanguardia y mantenerse al día de nuestras últimas innovaciones, consulte nuestro repositorio de GitHub. Únete a nuestra vibrante comunidad en Discord y descubre cómo estamos revolucionando sectores como el de los coches autónomos y la fabricación. 🚀