


La evolución de la detección de objetos y los modelos YOLO de Ultralytics

Acompáñenos en este repaso a la evolución de la detección de objetos. Nos centraremos en cómo han avanzado los modelos YOLO (You Only Look Once) en los últimos años.

Acompáñenos en este repaso a la evolución de la detección de objetos. Nos centraremos en cómo han avanzado los modelos YOLO (You Only Look Once) en los últimos años.
La visión artificial es un subcampo de la inteligencia artificial (IA) que se centra en enseñar a las máquinas a ver y comprender imágenes y vídeos, de forma similar a como los humanos perciben el mundo real. Si bien el reconocimiento de objetos o la identificación de acciones es algo natural para los humanos, estas tareas requieren técnicas de visión artificial específicas y especializadas cuando se trata de máquinas. Por ejemplo, una tarea clave en la visión artificial es la detección de objetos, que implica identificar y localizar objetos dentro de imágenes o vídeos.
Desde la década de 1960, los investigadores han trabajado para mejorar la detect objetos por ordenador. Los primeros métodos, como la comparación de plantillas, consistían en deslizar una plantilla predefinida por una imagen para encontrar coincidencias. Aunque innovadores, estos métodos tenían dificultades con los cambios de tamaño, orientación e iluminación de los objetos. Hoy disponemos de modelos avanzados como Ultralytics YOLO11 que pueden detect incluso objetos pequeños y parcialmente ocultos, conocidos como objetos ocluidos, con una precisión impresionante.
A medida que la visión por ordenador sigue evolucionando, es importante echar la vista atrás para ver cómo se han desarrollado estas tecnologías. En este artículo, exploraremos la evolución de la detección de objetos y arrojaremos luz sobre la transformación de los modelosYOLO (You Only Look Once). Empecemos.
Antes de adentrarnos en la detección de objetos, echemos un vistazo a los orígenes de la visión por ordenador. Los orígenes de la visión por ordenador se remontan a finales de los años 50 y principios de los 60, cuando los científicos empezaron a estudiar cómo procesa el cerebro la información visual. En experimentos con gatos, los investigadores David Hubel y Torsten Wiesel descubrieron que el cerebro reacciona ante patrones simples como bordes y líneas. Esto constituyó la base de la idea que subyace a la extracción de rasgos: el concepto de que los sistemas visuales detect y reconocen rasgos básicos en las imágenes, como los bordes, antes de pasar a patrones más complejos.

Casi al mismo tiempo, surgió una nueva tecnología que podía convertir imágenes físicas en formatos digitales, lo que despertó el interés en cómo las máquinas podían procesar la información visual. En 1966, el Proyecto de Visión de Verano del Instituto Tecnológico de Massachusetts (MIT) impulsó aún más las cosas. Si bien el proyecto no tuvo éxito completo, su objetivo era crear un sistema que pudiera separar el primer plano del fondo en imágenes. Para muchos en la comunidad de Vision AI, este proyecto marca el inicio oficial de la visión artificial como un campo científico.
A medida que la visión por ordenador avanzaba a finales de los 90 y principios de los 2000, los métodos de detección de objetos pasaron de técnicas básicas como la coincidencia de plantillas a enfoques más avanzados. Uno de los métodos más populares fue la cascada de Haar, muy utilizada para tareas como la detección de rostros. Funcionaba escaneando imágenes con una ventana deslizante, buscando características específicas como bordes o texturas en cada sección de la imagen y combinando después estas características para detect objetos como caras. Haar Cascade era mucho más rápido que los métodos anteriores.
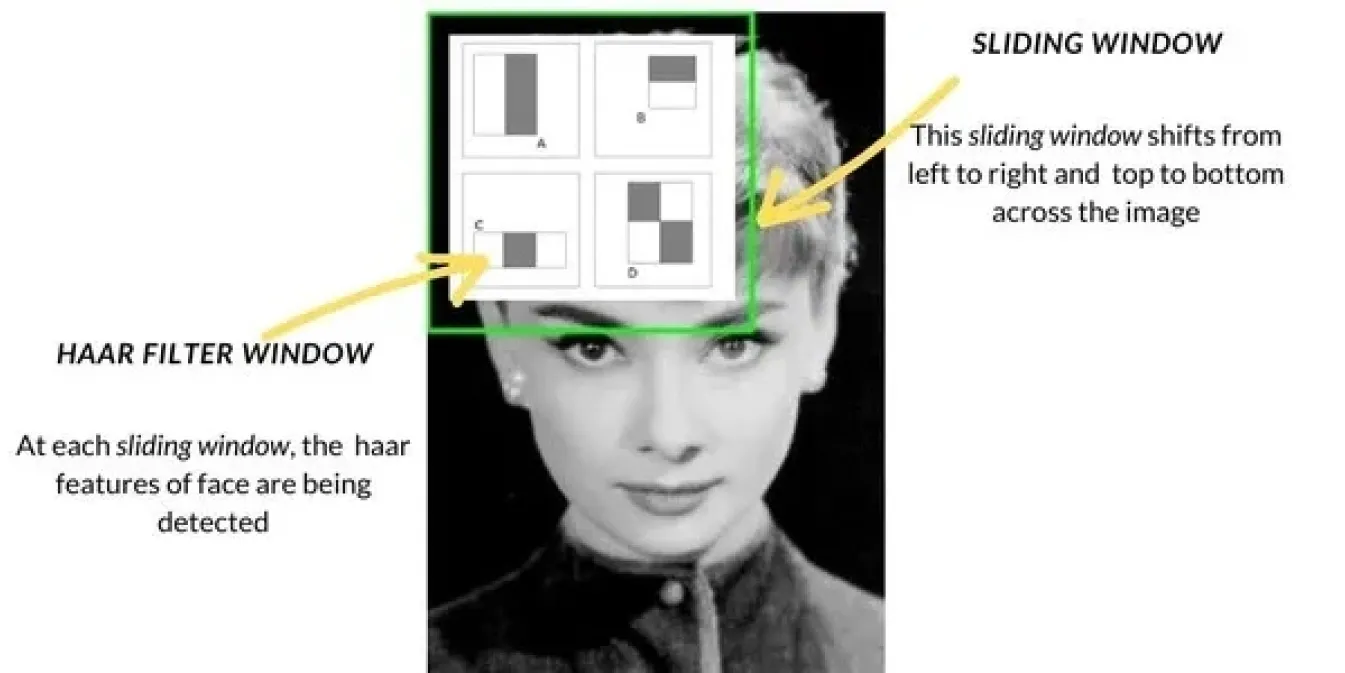
Junto con estos, también se introdujeron métodos como el Histograma de Gradientes Orientados (HOG) y las Máquinas de Vectores de Soporte (SVM). HOG utilizó la técnica de la ventana deslizante para analizar cómo cambiaban la luz y las sombras en pequeñas secciones de una imagen, lo que ayudó a identificar objetos basándose en sus formas. Luego, las SVM clasificaron estas características para determinar la identidad del objeto. Estos métodos mejoraron la precisión, pero aún tenían dificultades en entornos del mundo real y eran más lentos en comparación con las técnicas actuales.
En la década de 2010, el auge del aprendizaje profundo y las redes neuronales convolucionales (CNN) trajo un cambio importante en la detección de objetos. Las CNN hicieron posible que las computadoras aprendieran automáticamente características importantes de grandes cantidades de datos, lo que hizo que la detección fuera mucho más precisa.
Los primeros modelos como R-CNN (Redes Neuronales Convolucionales Basadas en Regiones) fueron una gran mejora en la precisión, lo que ayudó a identificar objetos con mayor precisión que los métodos anteriores.
Sin embargo, estos modelos eran lentos porque procesaban las imágenes en varias etapas, lo que los hacía poco prácticos para aplicaciones en tiempo real en áreas como los coches autónomos o la videovigilancia.
Con el objetivo de acelerar los procesos, se desarrollaron modelos más eficientes. Modelos como Fast R-CNN y Faster R-CNN ayudaron a refinar la forma en que se elegían las regiones de interés y a reducir el número de pasos necesarios para la detección. Si bien esto hizo que la detección de objetos fuera más rápida, aún no era lo suficientemente veloz para muchas aplicaciones del mundo real que necesitaban resultados instantáneos. La creciente demanda de detección en tiempo real impulsó el desarrollo de soluciones aún más rápidas y eficientes que pudieran equilibrar tanto la velocidad como la precisión.

YOLO es un modelo de detección de objetos que redefine la visión por ordenador al permitir la detección en tiempo real de múltiples objetos en imágenes y vídeos, lo que lo hace bastante único respecto a los métodos de detección anteriores. En lugar de analizar cada objeto detectado individualmente, la arquitectura deYOLO trata la detección de objetos como una única tarea, prediciendo tanto la ubicación como la clase de los objetos de una sola vez mediante CNN.
El modelo funciona dividiendo una imagen en una cuadrícula, y cada parte se encarga de detectar objetos en su área respectiva. Realiza múltiples predicciones para cada sección y filtra los resultados menos fiables, quedándose solo con los precisos.

La introducción de YOLO en las aplicaciones de visión por ordenador hizo que la detección de objetos fuera mucho más rápida y eficaz que los modelos anteriores. Gracias a su velocidad y precisión, YOLO se convirtió rápidamente en una opción popular para soluciones en tiempo real en sectores como la fabricación, la sanidad y la robótica.
Otro aspecto importante es que, como YOLO era de código abierto, los desarrolladores e investigadores pudieron mejorarlo continuamente, dando lugar a versiones aún más avanzadas.
Los modelos YOLO han mejorado constantemente con el tiempo, aprovechando los avances de cada versión. Además de mejorar el rendimiento, estas mejoras han facilitado el uso de los modelos a personas con distintos niveles de experiencia técnica.
Por ejemplo, cuando Ultralytics YOLOv5 el despliegue de modelos se simplificó con PyTorchpermitiendo a un mayor número de usuarios trabajar con IA avanzada. Unió precisión y facilidad de uso, dando a más personas la capacidad de implementar la detección de objetos sin necesidad de ser expertos en codificación.
Ultralytics YOLOv8 continuó este progreso añadiendo compatibilidad con tareas como la segmentación de instancias y flexibilizando los modelos. YOLO es ahora más fácil de utilizar tanto en aplicaciones básicas como en otras más complejas, por lo que resulta útil en una amplia gama de escenarios.
Con el último modelo Ultralytics YOLO11se han realizado nuevas optimizaciones. Al reducir el número de parámetros y mejorar la precisión, ahora es más eficiente para tareas en tiempo real. Tanto si eres un desarrollador experimentado como si eres nuevo en la IA, YOLO11 ofrece un enfoque avanzado para la detección de objetos que es fácilmente accesible.
YOLO11, presentado en el evento híbrido anual de Ultralytics, YOLO Vision 2024 (YV24), admite las mismas tareas de visión por ordenador que YOLOv8, como la detección de objetos, la segmentación de instancias, la clasificación de imágenes y la estimación de poses. Por tanto, los usuarios pueden cambiar fácilmente a este nuevo modelo sin necesidad de ajustar sus flujos de trabajo. Además, la arquitectura mejorada de YOLO11hace que las predicciones sean aún más precisas. De hecho, YOLO11m alcanza una precisión media superiormAP) en el conjunto de datosCOCO con un 22% menos de parámetros que YOLOv8m.
YOLO11 también está diseñado para funcionar con eficacia en diversas plataformas, desde teléfonos inteligentes y otros dispositivos periféricos hasta sistemas en la nube más potentes. Esta flexibilidad garantiza un rendimiento fluido en diferentes configuraciones de hardware para aplicaciones en tiempo real. Además, YOLO11 es más rápido y eficiente, lo que reduce los costes computacionales y acelera los tiempos de inferencia. Tanto si utiliza el paquetePython Ultralytics como el Ultralytics HUB sin código, es fácil integrar YOLO11 en sus flujos de trabajo actuales.
El impacto de la detección avanzada de objetos en las aplicaciones en tiempo real y la IA en los bordes ya se deja sentir en todos los sectores. A medida que sectores como el del petróleo y el gas, la sanidad y el comercio dependen cada vez más de la IA, la demanda de detección de objetos rápida y precisa sigue aumentando. YOLO11 pretende dar respuesta a esta demanda permitiendo una detección de alto rendimiento incluso en dispositivos con una potencia de cálculo limitada.
A medida que crece la IA, es probable que los modelos de detección de objetos como YOLO11 se vuelvan aún más esenciales para la toma de decisiones en tiempo real en entornos donde la velocidad y la precisión son fundamentales. Con mejoras continuas en el diseño y la adaptabilidad, el futuro de la detección de objetos parece que traerá aún más innovaciones en una gran variedad de aplicaciones.
La detección de objetos ha recorrido un largo camino, evolucionando desde métodos sencillos hasta las técnicas avanzadas de aprendizaje profundo que vemos hoy en día. Los modelos YOLO han estado en el centro de este progreso, ofreciendo una detección en tiempo real más rápida y precisa en diferentes sectores. YOLO11 se basa en este legado, mejorando la eficiencia, reduciendo los costes computacionales y mejorando la precisión, por lo que es una opción fiable para una variedad de aplicaciones en tiempo real. Con los continuos avances en IA y visión por ordenador, el futuro de la detección de objetos parece prometedor, con espacio para aún más mejoras en velocidad, precisión y adaptabilidad.
¿Tienes curiosidad por la IA? ¡Mantente conectado con nuestra comunidad para seguir aprendiendo! Consulta nuestro repositorio de GitHub para descubrir cómo estamos utilizando la IA para crear soluciones innovadoras en industrias como la manufactura y la sanidad. 🚀
.webp)

.webp)