En cliquant sur « Accepter tous les cookies », vous acceptez le stockage de cookies sur votre appareil pour améliorer la navigation sur le site, analyser son utilisation et contribuer à nos efforts de marketing. Plus d’infos
Paramètres des cookies
En cliquant sur « Accepter tous les cookies », vous acceptez le stockage de cookies sur votre appareil pour améliorer la navigation sur le site, analyser son utilisation et contribuer à nos efforts de marketing. Plus d’infos
Découvrez la nouvelle famille de modèles open source Llama 3.1 de Meta, comprenant le modèle polyvalent 8B, le modèle complet 70B et le modèle phare 405B, leur modèle le plus grand et le plus avancé à ce jour.
Le 23 juillet 2024, Meta a publié la nouvelle famille de modèles open source Llama 3.1, comprenant les modèles polyvalents 8B, 70B et Llama 3.1 405B, ce dernier se distinguant comme le plus grand modèle de langage (LLM) open source à ce jour.
Vous vous demandez peut-être ce qui distingue ces nouveaux modèles de leurs prédécesseurs. Eh bien, en explorant cet article, vous découvrirez que la sortie des modèles Llama 3.1 marque une étape importante dans la technologie de l'IA. Les modèles nouvellement publiés offrent des améliorations significatives dans le traitement du langage naturel ; de plus, ils introduisent de nouvelles fonctionnalités et améliorations qui ne se trouvent pas dans les versions antérieures. Cette sortie promet de changer la façon dont nous exploitons l'IA pour les tâches complexes, en fournissant un ensemble d'outils puissant aux chercheurs et aux développeurs.
Dans cet article, nous allons explorer la famille de modèles Llama 3.1, en nous penchant sur leur architecture, leurs principales améliorations, leurs utilisations pratiques et une comparaison détaillée de leurs performances.
Qu'est-ce que Llama 3.1 ?
Le dernier grand modèle linguistique de Meta, Llama 3.1, fait des progrès significatifs dans le paysage de l'IA, rivalisant avec les capacités de modèles de premier plan tels que Chat GPT-4o d'OpenAI et Claude 3.5 Sonnet d'Anthropic.
Bien qu'il puisse être considéré comme une mise à jour mineure du modèle Llama 3 précédent, Meta a franchi une nouvelle étape en introduisant des améliorations clés à la nouvelle famille de modèles, offrant :
Prise en charge de huit langues : L'English, l'allemand, le français, l'italien, le portugais, l'hindi, l'espagnol et le thaï, ce qui leur permet d'atteindre un public mondial.
128 000 jetons de fenêtre de contexte : Permet aux modèles de gérer des entrées beaucoup plus longues et de maintenir le contexte sur des conversations ou des documents étendus.
Meilleures capacités de raisonnement : Permettre aux modèles d'être plus polyvalents et capables de gérer efficacement des tâches complexes.
Sécurité rigoureuse : Des tests ont été mis en œuvre pour atténuer les risques, réduire les biais et prévenir les résultats nuisibles, favorisant ainsi une utilisation responsable de l'IA.
En plus de tout ce qui précède, la nouvelle famille de modèles Llama 3.1 présente une avancée majeure avec son impressionnant modèle de 405 milliards de paramètres. Ce nombre considérable de paramètres représente un bond en avant dans le développement de l'IA, améliorant considérablement la capacité du modèle à comprendre et à générer des textes complexes. Le modèle 405B comprend un large éventail de paramètres, chacun d'entre eux faisant référence aux weights and biases du réseau neuronal que le modèle apprend au cours de la formation. Cela permet au modèle de saisir des modèles linguistiques plus complexes, établissant une nouvelle norme pour les modèles linguistiques de grande taille et mettant en évidence le potentiel futur de la technologie de l'IA. Ce modèle à grande échelle permet non seulement d'améliorer les performances dans un large éventail de tâches, mais aussi de repousser les limites de ce que l'IA peut réaliser en termes de génération et de compréhension de texte.
Architecture du modèle
Llama 3.1 exploite l'architecture de modèle transformer à décodeur uniquement, une pierre angulaire des grands modèles de langage modernes. Cette architecture est réputée pour son efficacité et son efficience dans la gestion des tâches linguistiques complexes. L'utilisation de transformers permet à Llama 3.1 d'exceller dans la compréhension et la génération de texte de type humain, offrant un avantage significatif par rapport aux modèles qui utilisent des architectures plus anciennes telles que les LSTM et les GRU.
De plus, la famille de modèles Llama 3.1 utilise l'architecture Mixture of Experts (MoE), ce qui améliore l'efficacité et la stabilité de l'entraînement. Éviter l'architecture MoE garantit un processus d'entraînement plus cohérent et fiable, car MoE peut parfois introduire des complexités qui peuvent avoir un impact sur la stabilité et les performances du modèle.
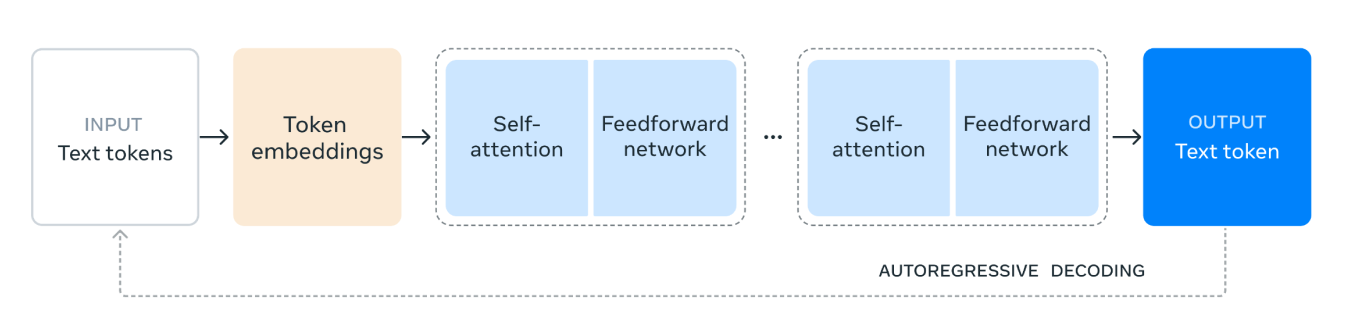
Fig. 1. Un diagramme illustrant l'architecture du modèle de transformateur Llama 3.1.
L'architecture du modèle Llama 3.1 fonctionne comme suit :
1. Jetons de texte en entrée : Le processus commence par l'entrée, constituée de jetons de texte. Ces jetons sont des unités de texte individuelles, telles que des mots ou des sous-mots, que le modèle traitera.
2. Intégrations de jetons : Les jetons de texte sont ensuite convertis en intégrations de jetons. Les intégrations sont des représentations vectorielles denses des jetons qui capturent leur signification sémantique et leurs relations au sein du texte. Cette transformation est cruciale car elle permet au modèle de fonctionner avec des données numériques.
3. Mécanisme d'auto-attention : L'auto-attention permet au modèle de pondérer l'importance des différents jetons dans la séquence d'entrée lors du codage de chaque jeton. Ce mécanisme aide le modèle à comprendre le contexte et les relations entre les jetons, quelles que soient leurs positions dans la séquence. Dans le mécanisme d'auto-attention, chaque jeton de la séquence d'entrée est représenté sous forme de vecteur de nombres. Ces vecteurs sont utilisés pour créer trois types de représentations différents : les requêtes, les clés et les valeurs.
Le modèle calcule l'attention que chaque jeton doit accorder aux autres jetons en comparant les vecteurs de requête avec les vecteurs clés. Cette comparaison donne des scores qui indiquent la pertinence de chaque jeton par rapport aux autres.
4. Réseau d'anticipation: Après le processus d'auto-attention, les données passent par un réseau d'anticipation. Ce réseau est un réseau neuronal entièrement connecté qui applique des transformations non linéaires aux données, ce qui aide le modèle à reconnaître et à apprendre des modèles complexes.
5. Couches répétées : Les couches de réseau d'auto-attention et feedforward sont empilées plusieurs fois. Cette application répétée permet au modèle de capturer des dépendances et des schémas plus complexes dans les données.
6. Jetons de texte de sortie : Enfin, les données traitées sont utilisées pour générer le jeton de texte de sortie. Ce jeton est la prédiction du modèle pour le mot ou le sous-mot suivant dans la séquence, basée sur le contexte d'entrée.
Performances de la famille de modèles LLama 3.1 et comparaisons avec d'autres modèles
Les tests de référence révèlent que Llama 3.1 non seulement se mesure à ces modèles de pointe, mais les surpasse également dans certaines tâches, démontrant ainsi ses performances supérieures.
Llama 3.1 405B : Haute capacité
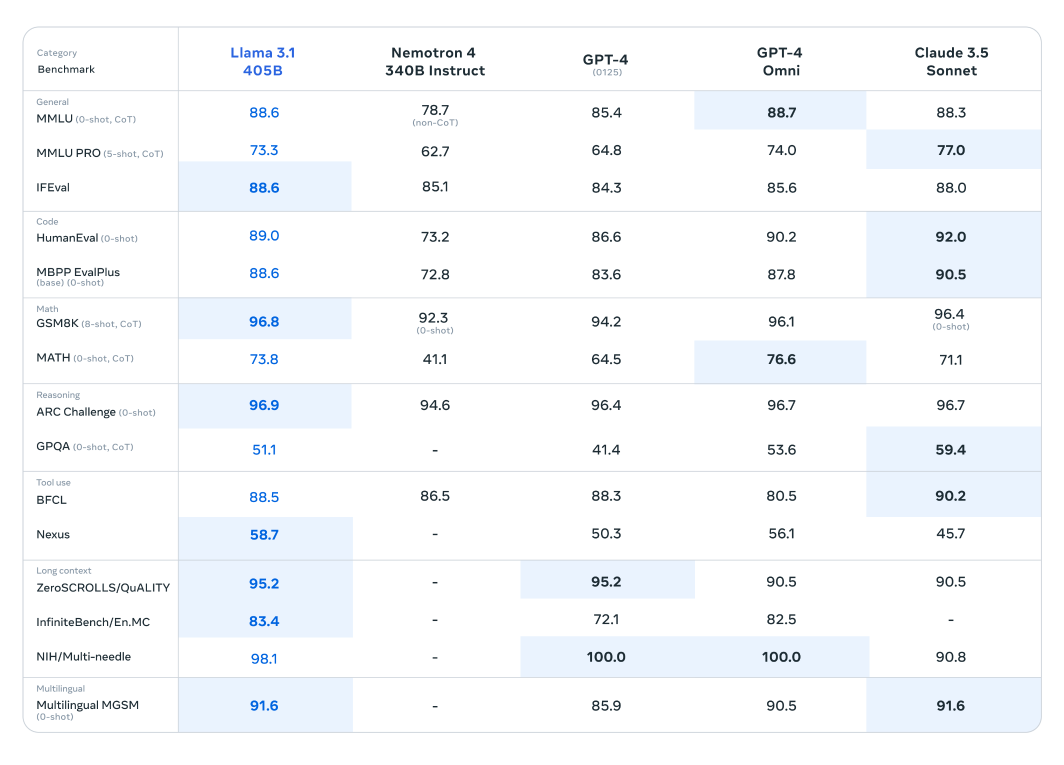
Le modèle Llama 3.1 a subi une évaluation approfondie sur plus de 150 ensembles de données de référence, où il a été rigoureusement comparé à d'autres grands modèles de langage de premier plan. Le modèle Llama 3.1 405B, reconnu comme le plus performant de la série nouvellement publiée, a été comparé à des titans de l'industrie tels que GPT-4 d'OpenAI et Claude 3.5 Sonnet. Les résultats de ces comparaisons révèlent que Llama 3.1 démontre un avantage concurrentiel, mettant en évidence ses performances et ses capacités supérieures dans diverses tâches.
Fig. 2. Un tableau comparant les performances du modèle Llama 3.1 405B à celles de modèles similaires.
Le nombre impressionnant de paramètres et l'architecture avancée de ce modèle lui permettent d'exceller dans la compréhension complexe et la génération de texte, dépassant souvent ses concurrents dans des benchmarks spécifiques. Ces évaluations soulignent le potentiel de Llama 3.1 à établir de nouvelles normes dans le domaine des grands modèles linguistiques, en fournissant aux chercheurs et aux développeurs un outil puissant pour diverses applications.
Llama 3.1 70B : Milieu de gamme
Les modèles Llama plus petits et plus légers démontrent également des performances remarquables par rapport à leurs homologues. Le modèle Llama 3.1 70B a été évalué par rapport à des modèles plus grands tels que Mistral 8x22B et GPT-3.5 Turbo. Par exemple, le modèle Llama 3.1 70B démontre constamment des performances supérieures dans les ensembles de données de raisonnement tels que l'ensemble de données ARC Challenge et les ensembles de données de codage tels que les ensembles de données HumanEval. Ces résultats soulignent la polyvalence et la robustesse de la série Llama 3.1 dans différentes tailles de modèles, ce qui en fait un outil précieux pour un large éventail d'applications.
Llama 3.1 8B : Léger
De plus, le modèle Llama 3.1 8B a été comparé à des modèles de taille similaire, notamment Gemma 2 9B et Mistral 7B. Ces comparaisons révèlent que le modèle Llama 3.1 8B surpasse ses concurrents dans divers ensembles de données de référence dans différents genres tels que l'ensemble de données GPQA pour le raisonnement et le MBPP EvalPlus pour le codage, démontrant ainsi son efficacité et sa capacité malgré son nombre de paramètres plus petit.
Fig 3. Un tableau comparant les performances des modèles Llama 3.1 70B et 8B à des modèles similaires.
Comment pouvez-vous bénéficier des modèles de la famille Llama 3.1 ?
Meta a permis d'appliquer les nouveaux modèles de diverses manières pratiques et bénéfiques pour les utilisateurs :
Ajustement fin
Les utilisateurs peuvent désormais affiner les derniers modèles Llama 3.1 pour des cas d'utilisation spécifiques. Ce processus implique l'entraînement du modèle sur de nouvelles données externes auxquelles il n'a pas été exposé auparavant, améliorant ainsi ses performances et son adaptabilité pour des applications ciblées. Le fine-tuning donne au modèle un avantage significatif en lui permettant de mieux comprendre et de générer du contenu pertinent pour des domaines ou des tâches spécifiques.
Intégration dans un système RAG
Les modèles Llama 3.1 peuvent désormais être intégrés de manière transparente dans les systèmes de génération augmentée par récupération (RAG). Cette intégration permet au modèle d'exploiter dynamiquement des sources de données externes, améliorant ainsi sa capacité à fournir des réponses précises et contextuellement pertinentes. En récupérant des informations à partir de grands ensembles de données et en les intégrant dans le processus de génération, Llama 3.1 améliore considérablement ses performances dans les tâches à forte intensité de connaissances, offrant aux utilisateurs des résultats plus précis et plus éclairés.
Génération de données synthétiques
Vous pouvez également utiliser le modèle de 405 milliards de paramètres pour générer des données synthétiques de haute qualité, améliorant ainsi les performances des modèles spécialisés pour des cas d'utilisation spécifiques. Cette approche exploite les vastes capacités de Llama 3.1 pour produire des données ciblées et pertinentes, améliorant ainsi la précision et l'efficacité des applications d'IA personnalisées.
Les points clés
La sortie de Llama 3.1 représente un bond en avant significatif dans le domaine des grands modèles de langage, témoignant de l'engagement de Meta à faire progresser la technologie de l'IA.
Avec un nombre de paramètres important, un entraînement approfondi sur divers ensembles de données et un accent mis sur des processus d'entraînement robustes et stables, Llama 3.1 établit de nouvelles références en matière de performances et de capacités dans le traitement du langage naturel. Que ce soit dans la génération de texte, la synthèse ou les tâches conversationnelles complexes, Llama 3.1 démontre un avantage concurrentiel par rapport aux autres modèles de pointe. Ce modèle repousse non seulement les limites de ce que l'IA peut réaliser aujourd'hui, mais prépare également le terrain pour les innovations futures dans le paysage en constante évolution de l'intelligence artificielle.
Chez Ultralytics, nous nous efforçons de repousser les limites de la technologie de l'IA. Pour explorer nos solutions d'IA de pointe et suivre nos dernières innovations, consultez notre dépôt GitHub. Rejoignez notre communauté dynamique sur Discord et découvrez comment nous révolutionnons des secteurs tels que les voitures autonomes et la fabrication! 🚀