



Llama 3 de Meta a été lancé récemment et a suscité un grand enthousiasme au sein de la communauté de l’IA. Découvrons Llama 3, la dernière avancée de Meta AI.

Llama 3 de Meta a été lancé récemment et a suscité un grand enthousiasme au sein de la communauté de l’IA. Découvrons Llama 3, la dernière avancée de Meta AI.
Lorsque nous avons fait le tour des innovations en matière d’intelligence artificielle (IA) du premier trimestre 2024, nous avons constaté que les LLM, ou grands modèles linguistiques, étaient lancés à tout va par différentes organisations. Poursuivant cette tendance, le 18 avril 2024, Meta a lancé Llama 3, un LLM open source de pointe de nouvelle génération.
Vous vous dites peut-être : Ce n’est qu’un LLM de plus. Pourquoi la communauté de l’IA est-elle si enthousiaste à ce sujet ?
Bien que vous puissiez affiner des modèles comme GPT-3 ou Gemini pour obtenir des réponses personnalisées, ils n’offrent pas une transparence totale concernant leur fonctionnement interne, comme leurs données d’entraînement, les paramètres de leurs modèles ou leurs algorithmes. En revanche, Llama 3 de Meta est plus transparent, son architecture et ses poids étant disponibles au téléchargement. Pour la communauté de l’IA, cela signifie une plus grande liberté d’expérimentation.
Dans cet article, nous allons découvrir ce que Llama 3 peut faire, comment il a été créé et son impact sur le domaine de l’IA. Passons directement au vif du sujet !
Avant de plonger dans Llama 3, revenons sur ses versions antérieures.
Meta a lancé Llama 1 en février 2023, disponible en quatre variantes avec des paramètres allant de 7 milliards à 64 milliards. En apprentissage automatique, les "paramètres" font référence aux éléments du modèle qui sont appris à partir des données d'entraînement. En raison de son nombre de paramètres plus faible, Llama 1 avait parfois du mal à comprendre les nuances et donnait des réponses incohérentes.
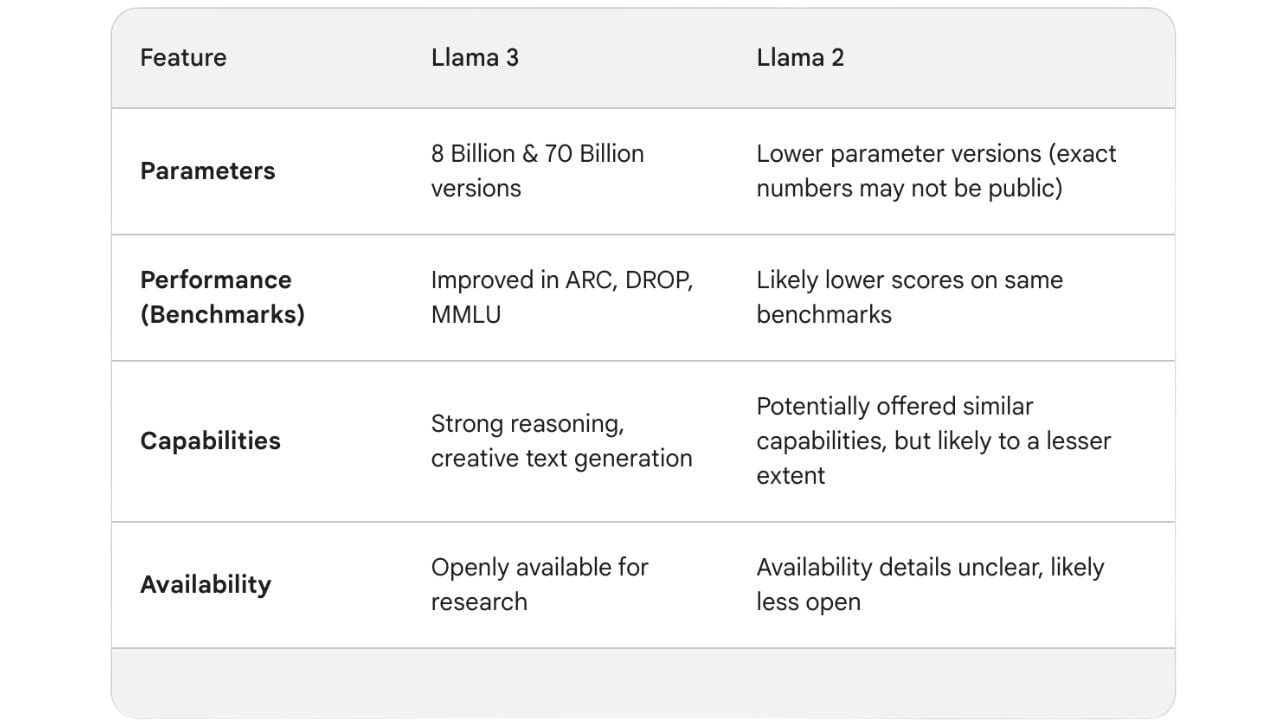
Peu de temps après Llama 1, Meta a lancé Llama 2 en juillet 2023. Il a été entraîné sur 2 billions de tokens. Un token représente un élément de texte, comme un mot ou une partie de mot, utilisé comme unité de données de base pour le traitement dans le modèle. Le modèle comprenait également des améliorations telles qu'une fenêtre contextuelle doublée de 4096 tokens pour comprendre des passages plus longs et plus d'un million d'annotations humaines pour réduire les erreurs. Malgré ces améliorations, Llama 2 nécessitait encore beaucoup de puissance de calcul, ce que Meta visait à corriger avec Llama 3.
Llama 3 est disponible en quatre variantes qui ont été entraînées sur un nombre impressionnant de 15 billions de tokens. Plus de 5 % de ces données d'entraînement (environ 800 millions de tokens) représentaient des données dans 30 langues différentes. Toutes les variantes de Llama 3 peuvent être exécutées sur différents types de matériel grand public et ont une longueur de contexte de 8 000 tokens.

Les variantes du modèle sont disponibles en deux tailles : 8B et 70B, indiquant respectivement 8 milliards et 70 milliards de paramètres. Il existe également deux versions, base et instruct. "Base" fait référence à la version pré-entraînée standard. "Instruct" est une version affinée optimisée pour des applications ou des domaines spécifiques grâce à un entraînement supplémentaire sur des données pertinentes.
Voici les variantes du modèle Llama 3 :
Comme pour toute autre avancée de Meta AI, des mesures rigoureuses de contrôle de la qualité ont été mises en place pour maintenir l'intégrité des données et minimiser les biais lors du développement de Llama 3. Ainsi, le produit final est un modèle puissant qui a été créé de manière responsable.
L'architecture du modèle Llama 3 se distingue par son accent sur l'efficacité et la performance dans les tâches de traitement du langage naturel. Construit sur un framework basé sur Transformer, il met l'accent sur l'efficacité computationnelle, en particulier lors de la génération de texte, en utilisant une architecture de décodeur uniquement.
Le modèle génère des sorties basées uniquement sur le contexte précédent sans encodeur pour encoder les entrées, ce qui le rend beaucoup plus rapide.

Les modèles Llama 3 disposent d'un tokenizer avec un vocabulaire de 128K tokens. Un vocabulaire plus grand signifie que les modèles peuvent mieux comprendre et traiter le texte. De plus, les modèles utilisent désormais l'attention de requête groupée (GQA) pour améliorer l'efficacité de l'inférence. GQA est une technique que vous pouvez considérer comme un projecteur qui aide les modèles à se concentrer sur les parties pertinentes des données d'entrée pour générer des réponses plus rapides et plus précises.
Voici quelques détails plus intéressants sur l'architecture du modèle de Llama 3 :
Pour entraîner les plus grands modèles Llama 3, trois types de parallélisation ont été combinés : la parallélisation des données, la parallélisation des modèles et la parallélisation des pipelines.
La parallélisation des données répartit les données d'apprentissage sur plusieurs GPU, tandis que la parallélisation du modèle partitionne l'architecture du modèle afin d'utiliser la puissance de calcul de chaque GPU. La parallélisation du pipeline divise le processus de formation en étapes séquentielles, optimisant ainsi le calcul et la communication.
L'implémentation la plus efficace a atteint une utilisation remarquable des calculs, dépassant 400 TFLOPS par GPU lors de l'entraînement sur 16 000 GPU simultanément. Ces entraînements ont été effectués sur deux grappes de GPU construites sur mesure, chacune comprenant 24 000 GPU. Cette infrastructure de calcul importante a fourni la puissance nécessaire pour entraîner efficacement les modèles Llama 3 à grande échelle.
Pour maximiser le temps de fonctionnement des GPU , une nouvelle pile de formation avancée a été développée, automatisant la détection, le traitement et la maintenance des erreurs. La fiabilité du matériel et les mécanismes de détection ont été considérablement améliorés afin d'atténuer les risques de corruption silencieuse des données. En outre, de nouveaux systèmes de stockage évolutifs ont été mis au point pour réduire les frais généraux liés aux points de contrôle et aux retours en arrière.
Ces améliorations ont permis d'atteindre une efficacité globale de temps de formation de plus de 95 %. Combinées, elles ont augmenté l'efficacité de la formation de Llama 3 d'environ trois fois par rapport à Llama 2. Cette efficacité n'est pas seulement impressionnante, elle ouvre de nouvelles possibilités pour les méthodes de formation en IA.
Étant donné que Llama 3 est open source, les chercheurs et les étudiants peuvent étudier son code, mener des expériences et participer à des discussions sur les préoccupations éthiques et les biais. Cependant, Llama 3 ne s'adresse pas uniquement au monde universitaire. Il fait également des vagues dans les applications pratiques. Il devient l'épine dorsale de l'interface de chat Meta AI, s'intégrant de manière transparente dans des plateformes telles que Facebook, Instagram, WhatsApp et Messenger. Avec Meta AI, les utilisateurs peuvent engager des conversations en langage naturel, accéder à des recommandations personnalisées, effectuer des tâches et se connecter facilement avec les autres.

Llama 3 offre des performances exceptionnelles dans plusieurs benchmarks clés qui évaluent la compréhension du langage complexe et les capacités de raisonnement. Voici quelques-uns des benchmarks qui testent divers aspects des capacités de Llama 3 :
Les résultats exceptionnels du Llama 3 dans ces tests le distinguent clairement de ses concurrents tels que le Gemma 7B de Google, le Mistral 7B de Mistral et le Claude 3 Sonnet d'Anthropic. Selon les statistiques publiées, le Llama 3 surpasse ces modèles, en particulier le modèle 70B, dans tous les tests de référence susmentionnés.

Meta élargit la portée de Llama 3 en le rendant disponible sur diverses plateformes pour les utilisateurs généraux et les développeurs. Pour les utilisateurs quotidiens, Llama 3 est intégré aux plateformes populaires de Meta telles que WhatsApp, Instagram, Facebook et Messenger. Les utilisateurs peuvent accéder à des fonctionnalités avancées telles que la recherche en temps réel et la possibilité de générer du contenu créatif directement dans ces applications.
Llama 3 est également intégré aux technologies portables telles que les lunettes intelligentes Ray-Ban Meta et le casque VR Meta Quest pour des expériences interactives.
Llama 3 est disponible sur diverses plateformes pour les développeurs, notamment AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM et Snowflake. Vous pouvez également accéder à ces modèles directement depuis Meta. Le large éventail d'options permet aux développeurs d'intégrer facilement ces capacités de modèles d'IA avancés dans leurs projets, qu'ils préfèrent travailler directement avec Meta ou par le biais d'autres plateformes populaires.
Les avancées en matière d'apprentissage automatique continuent de transformer notre façon d'interagir avec la technologie au quotidien. Llama 3 de Meta montre que les LLM ne se limitent plus à la génération de texte. Les LLM s'attaquent à des problèmes complexes et gèrent plusieurs langues. Dans l'ensemble, Llama 3 rend l'IA plus adaptable et accessible que jamais. Pour l'avenir, les mises à niveau prévues pour Llama 3 promettent encore plus de capacités, comme la gestion de plusieurs modèles et la compréhension de contextes plus larges.
Consultez notre répertoire GitHub et rejoignez notre communauté pour en savoir plus sur l'IA. Visitez nos pages de solutions pour voir comment l'IA est appliquée dans des domaines tels que la fabrication et l'agriculture.



{kind=link}
{kind=link}
{kind=link}