



Découvrez comment Mask R-CNN peut être utilisé pour segment avec précision des objets dans des images et des vidéos pour diverses applications dans différents secteurs.

Découvrez comment Mask R-CNN peut être utilisé pour segment avec précision des objets dans des images et des vidéos pour diverses applications dans différents secteurs.
Les innovations telles que les robots dans les entrepôts, les voitures autonomes se déplaçant en toute sécurité dans les rues animées, les drones vérifiant les récoltes et les systèmes d'IA inspectant les produits dans les usines deviennent de plus en plus courantes à mesure que l'adoption de l'IA augmente. Une technologie clé à l'origine de ces innovations est la vision par ordinateur, une branche de l'IA qui permet aux machines de comprendre et d'interpréter les données visuelles.
Par exemple, la détection d'objets est une tâche de vision par ordinateur qui aide à identifier et à localiser les objets dans les images à l'aide de boîtes englobantes. Bien que les boîtes englobantes offrent des informations utiles, elles ne fournissent qu'une estimation approximative de la position d'un objet et ne peuvent pas capturer sa forme ou ses limites exactes. Cela les rend moins efficaces dans les applications qui nécessitent une identification précise.
Pour résoudre ce problème, les chercheurs ont développé des modèles de segmentation qui capturent les contours exacts des objets, fournissant des détails au niveau des pixels pour une détection et une analyse plus précises.
Mask R-CNN est l'un de ces modèles. Introduit en 2017 par Facebook AI Research (FAIR), il s'appuie sur des modèles antérieurs tels que R-CNN, Fast R-CNN et Faster R-CNN. Étape importante dans l'histoire de la vision par ordinateur, Mask R-CNN a ouvert la voie à des modèles plus avancés, tels que Ultralytics YOLO11.
Dans cet article, nous examinerons ce qu'est le R-CNN du masque, comment il fonctionne, ses applications et les améliorations qui lui ont succédé et qui ont conduit à YOLO11.
Mask R-CNN, qui signifie Mask Region-based Convolutional Neural Network (réseau neuronal convolutif basé sur les régions avec masques), est un modèle d'apprentissage profond conçu pour les tâches de vision par ordinateur telles que la détection d'objets et la segmentation d'instances.
La segmentation d'instances va au-delà de la détection d'objets traditionnelle en identifiant non seulement les objets dans une image, mais aussi en délimitant avec précision chacun d'eux. Elle attribue une étiquette unique à chaque objet détecté et capture sa forme exacte au niveau du pixel. Cette approche détaillée permet de distinguer clairement les objets qui se chevauchent et de traiter avec précision les formes complexes.
Mask R-CNN s'appuie sur Faster R-CNN, qui détecte et étiquette les objets, mais ne définit pas leurs formes exactes. Mask R-CNN améliore ce point en identifiant les pixels exacts qui composent chaque objet, ce qui permet une analyse d'image beaucoup plus détaillée et précise.

Mask R-CNN adopte une approche progressive pour detect et segment objets avec précision. Il commence par extraire les caractéristiques clés à l'aide d'un réseau neuronal profond (un modèle multicouche qui apprend à partir des données), puis identifie les zones d'objets potentiels à l'aide d'un réseau de proposition de régions (un composant qui suggère des régions d'objets probables), et enfin affine ces zones en créant des masques de segmentation détaillés (contours précis d'objets) qui capturent la forme exacte de chaque objet.
Ensuite, nous allons passer en revue chaque étape pour mieux comprendre comment fonctionne Mask R-CNN.
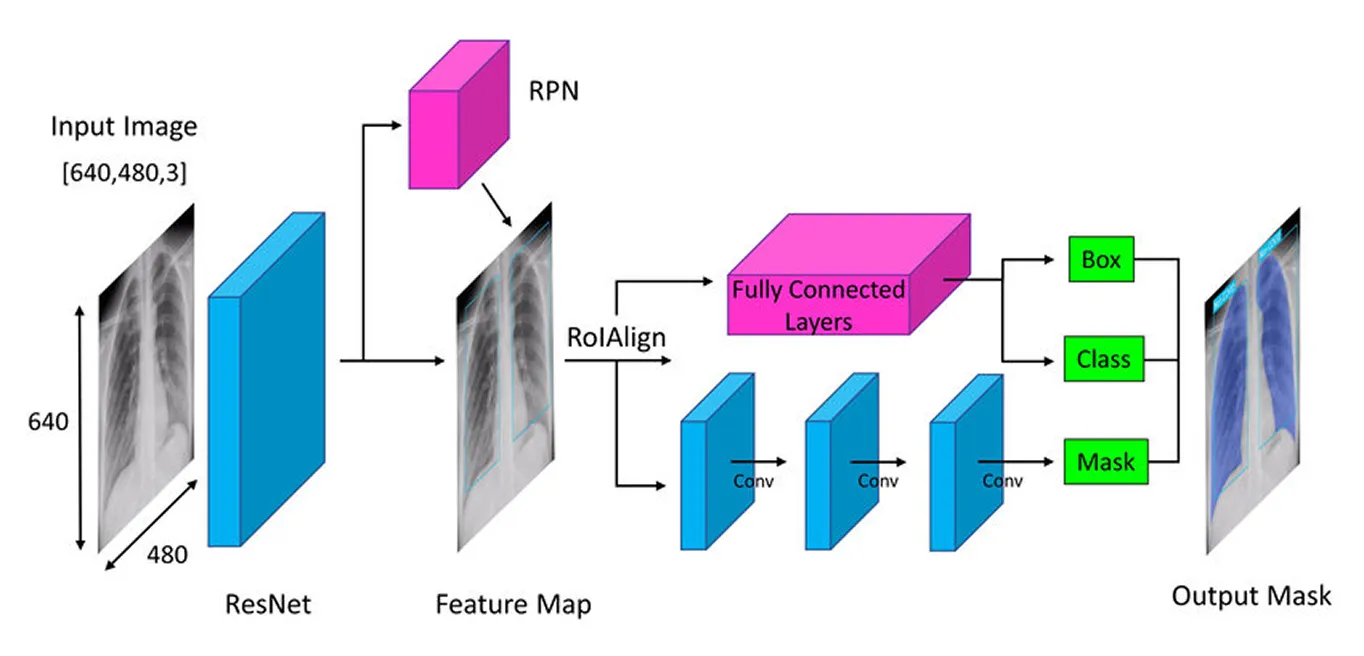
La première étape de l'architecture de Mask R-CNN consiste à décomposer l'image en ses parties clés afin que le modèle puisse comprendre ce qu'elle contient. C'est comme lorsque vous regardez une photo et que vous remarquez naturellement des détails tels que les formes, les couleurs et les bords. Le modèle fait quelque chose de similaire en utilisant un réseau neuronal profond appelé "backbone" (souvent ResNet-50 ou ResNet-101), qui agit comme ses yeux pour scanner l'image et relever les détails clés.
Étant donné que les objets dans les images peuvent être très petits ou très grands, Mask R-CNN utilise un réseau de pyramides de caractéristiques (Feature Pyramid Network). C'est comme avoir différentes loupes qui permettent au modèle de voir à la fois les détails fins et l'ensemble, garantissant ainsi que les objets de toutes tailles sont remarqués.
Une fois ces caractéristiques importantes extraites, le modèle passe à la localisation des objets potentiels dans l'image, préparant ainsi le terrain pour une analyse plus approfondie.
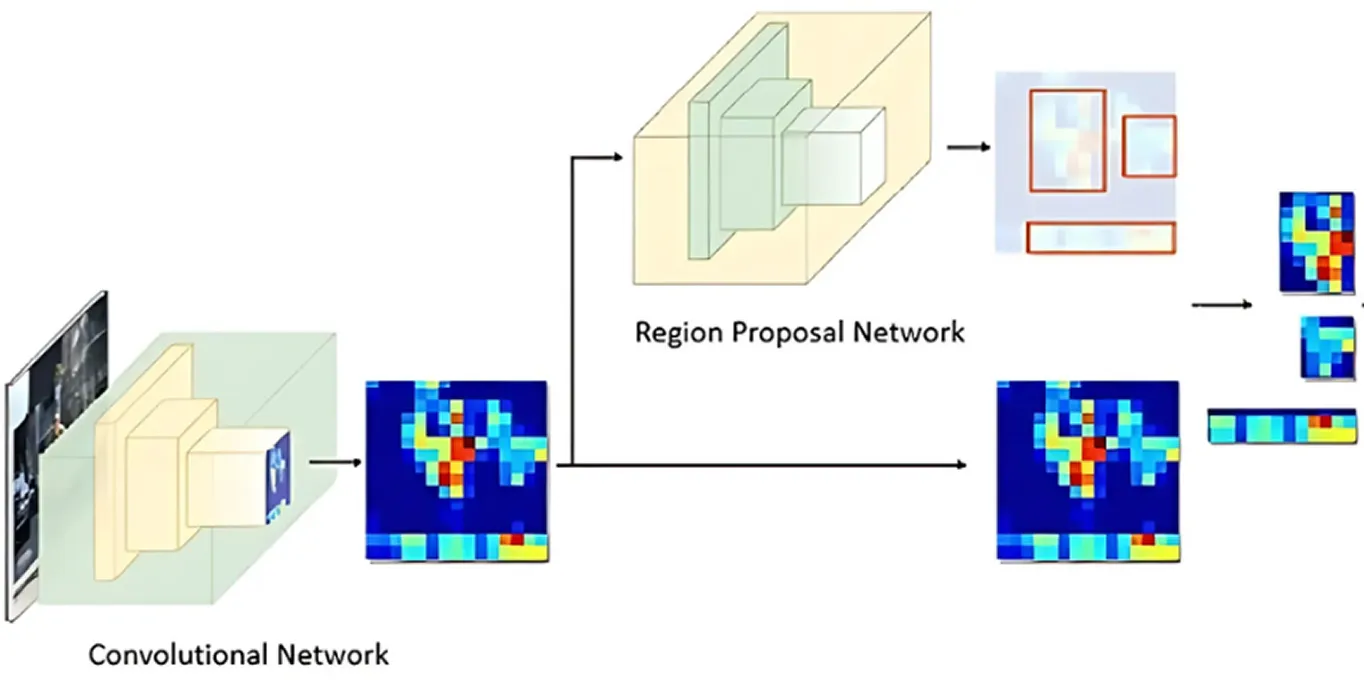
Une fois que l'image a été traitée pour en extraire les caractéristiques clés, le réseau de proposition de régions prend le relais. Cette partie du modèle examine l'image et suggère les zones susceptibles de contenir des objets.
Il le fait en générant plusieurs emplacements d'objets possibles appelés ancres. Le réseau évalue ensuite ces ancres et sélectionne les plus prometteuses pour une analyse plus approfondie. De cette façon, le modèle se concentre uniquement sur les zones les plus susceptibles d'être intéressantes, plutôt que de vérifier chaque point de l'image.
Une fois les zones clés identifiées, l'étape suivante consiste à affiner les détails extraits de ces régions. Les modèles précédents utilisaient une méthode appelée ROI Pooling (Region of Interest Pooling) pour saisir les caractéristiques de chaque zone, mais cette technique entraînait parfois de légers défauts d'alignement lors du redimensionnement des régions, ce qui la rendait moins efficace, en particulier pour les objets plus petits ou se chevauchant.
Mask R-CNN améliore ce point en utilisant une technique appelée ROI Align (Region of Interest Align). Au lieu d'arrondir les coordonnées comme le fait ROI Pooling, ROI Align utilise l'interpolation bilinéaire pour estimer les valeurs des pixels avec plus de précision. L'interpolation bilinéaire est une méthode qui calcule une nouvelle valeur de pixel en faisant la moyenne des valeurs de ses quatre voisins les plus proches, ce qui crée des transitions plus douces. Cela permet de maintenir les caractéristiques correctement alignées avec l'image originale, ce qui se traduit par une détection et une segmentation des objets plus précises.
Par exemple, lors d'un match de football, deux joueurs se tenant près l'un de l'autre peuvent être confondus l'un avec l'autre parce que leurs boîtes englobantes se chevauchent. ROI Align permet de les séparer en conservant la distinction de leurs formes.
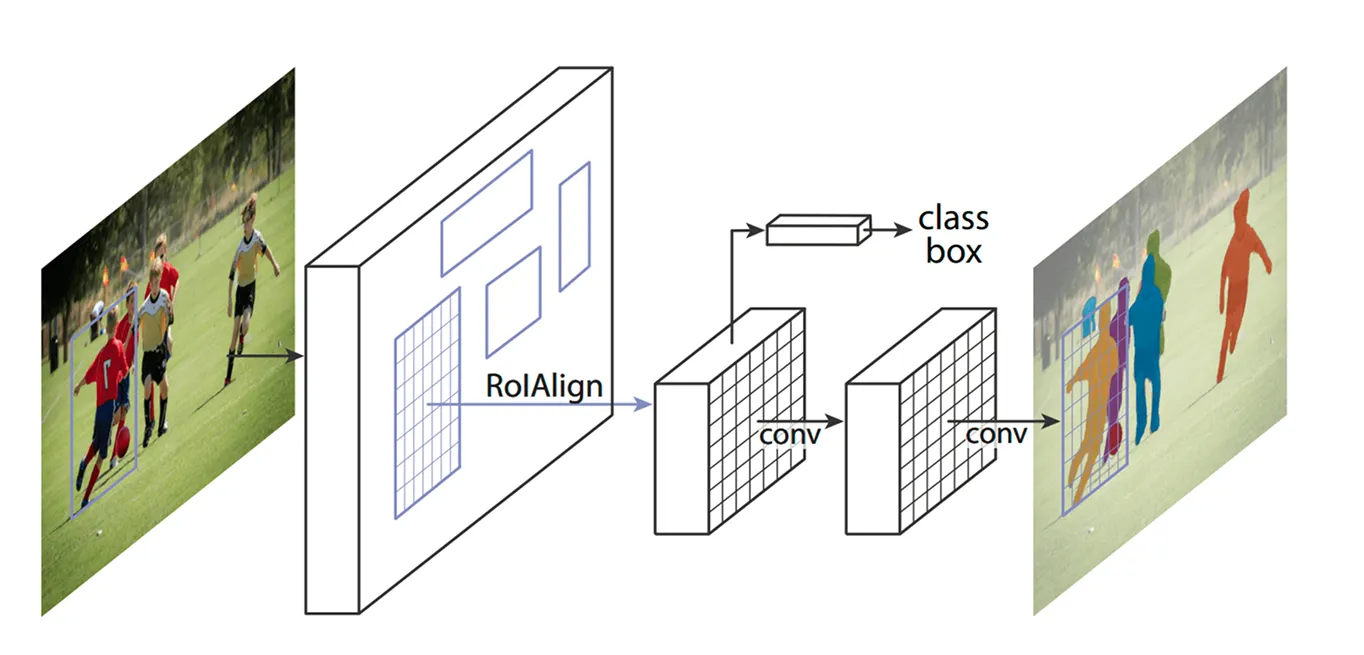
Une fois que ROI Align a traité l'image, l'étape suivante consiste à classify objets et à affiner leur emplacement. Le modèle examine chaque région extraite et détermine l'objet qu'elle contient. Il attribue un score de probabilité aux différentes catégories et choisit la meilleure correspondance.
Parallèlement, il ajuste les boîtes englobantes pour mieux s'adapter aux objets. Les boîtes initiales peuvent ne pas être idéalement placées, ce qui permet d'améliorer la précision en s'assurant que chaque boîte entoure étroitement l'objet détecté.
Enfin, Mask R-CNN franchit une étape supplémentaire : il génère un masque de segmentation détaillé pour chaque objet en parallèle.
Lorsque ce modèle est apparu, il a suscité beaucoup d'enthousiasme de la part de la communauté de l'IA et a rapidement été utilisé dans diverses applications. Sa capacité à detect et à segment objets en temps réel a changé la donne dans différents secteurs.
Par exemple, le suivi des animaux en voie de disparition dans la nature est une tâche difficile. De nombreuses espèces se déplacent dans des forêts denses, ce qui complique la tâche track défenseurs de l'environnement. Les méthodes traditionnelles utilisent des pièges photographiques, des drones et des images satellites, mais le tri manuel de toutes ces données prend beaucoup de temps. Les erreurs d'identification et les observations manquées peuvent ralentir les efforts de conservation.
En reconnaissant des caractéristiques uniques telles que les rayures du tigre, les taches de la girafe ou la forme des oreilles de l'éléphant, Mask R-CNN peut detect et segment animaux dans les images et les vidéos avec une plus grande précision. Même lorsque les animaux sont partiellement cachés par des arbres ou qu'ils sont proches les uns des autres, le modèle peut les séparer et les identifier individuellement, ce qui rend la surveillance de la faune plus rapide et plus fiable.

Malgré son importance historique dans la détection et la segmentation d'objets, Mask R-CNN présente également quelques inconvénients majeurs. Voici quelques défis liés à Mask R-CNN :
Le R-CNN de masque était excellent pour les tâches de segmentation, mais de nombreuses industries cherchaient à adopter la vision par ordinateur tout en privilégiant la vitesse et les performances en temps réel. Cette exigence a conduit les chercheurs à développer des modèles en une seule étape qui detect objets en un seul passage, améliorant ainsi considérablement l'efficacité.
Contrairement au processus en plusieurs étapes de Mask R-CNN, les modèles de vision par ordinateur en une seule étape comme YOLO (You Only Look Once) se concentrent sur les tâches de vision par ordinateur en temps réel. Au lieu de traiter la détection et la segmentation séparément, les modèles YOLO peuvent analyser une image en une seule fois. Ils sont donc idéaux pour des applications telles que la conduite autonome, les soins de santé, la fabrication et la robotique, où la rapidité de la prise de décision est cruciale.
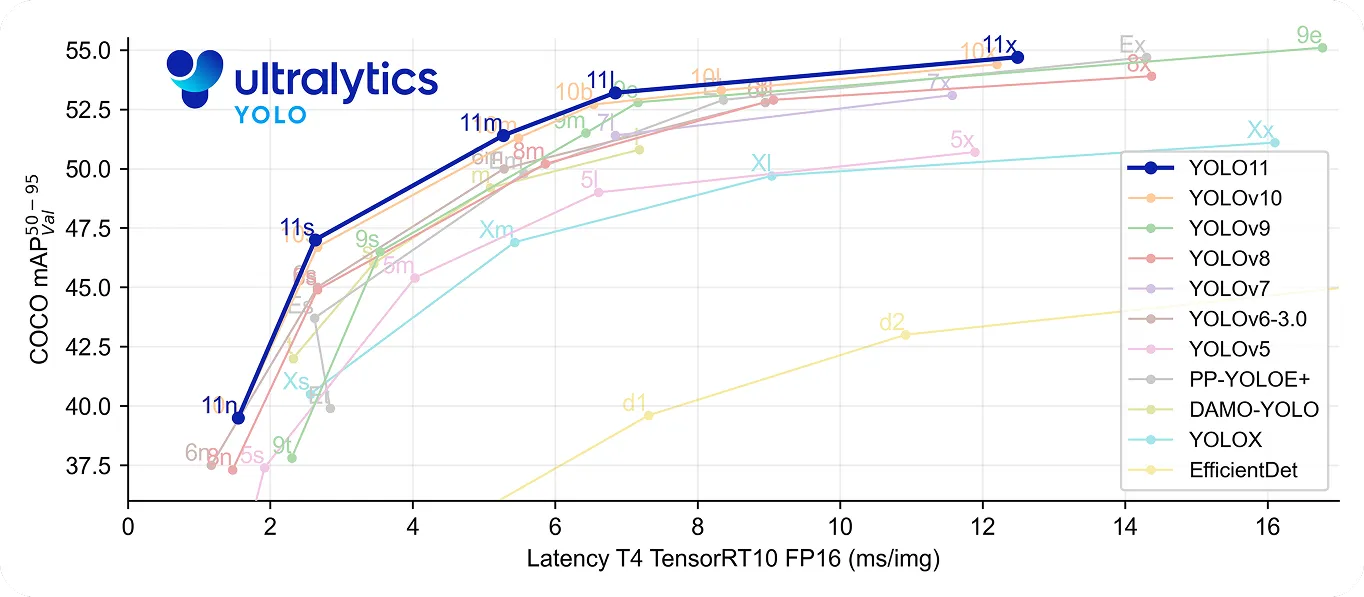
En particulier, YOLO11 va encore plus loin en étant à la fois rapide et précis. Il utilise 22 % de paramètres en moins que YOLOv8m , tout en obtenant une précision moyenne plus élevéemAP sur l'ensemble de données COCO , ce qui signifie qu'il détecte les objets avec plus de précision. Sa vitesse de traitement améliorée en fait un bon choix pour les applications en temps réel où chaque milliseconde compte.
En revenant sur l'histoire de la vision par ordinateur, Mask R-CNN est reconnu comme une avancée majeure dans la détection et la segmentation d'objets. Il fournit des résultats très précis, même dans des environnements complexes, grâce à son processus détaillé en plusieurs étapes.
Cependant, ce même processus le rend plus lent que les modèles en temps réel comme YOLO. Le besoin de rapidité et d'efficacité augmentant, de nombreuses applications utilisent désormais des modèles à une étape comme Ultralytics YOLO11, qui offrent une détection d'objets rapide et précise. Si le R-CNN de Mask est important pour comprendre l'évolution de la vision par ordinateur, la tendance aux solutions en temps réel met en évidence la demande croissante de solutions de vision par ordinateur plus rapides et plus efficaces.
Rejoignez notre communauté grandissante ! Explorez notre dépôt GitHub pour en savoir plus sur l'IA. Prêt à démarrer vos propres projets de vision par ordinateur ? Consultez nos options de licence. Découvrez l'IA dans l'agriculture et la Vision IA dans le secteur de la santé en visitant nos pages de solutions !


