



Meta의 새로운 Llama 3.1 오픈 소스 모델 제품군을 살펴보세요. 다재다능한 8B, 다방면에 뛰어난 70B, 그리고 현재까지 가장 크고 발전된 플래그십 모델인 405B를 특징으로 합니다.

Meta의 새로운 Llama 3.1 오픈 소스 모델 제품군을 살펴보세요. 다재다능한 8B, 다방면에 뛰어난 70B, 그리고 현재까지 가장 크고 발전된 플래그십 모델인 405B를 특징으로 합니다.
2024년 7월 23일, Meta는 다재다능한 8B, 유능한 70B, Llama 3.1 405B 모델을 특징으로 하는 새로운 Llama 3.1 오픈 소스 모델 제품군을 출시했으며, 최신 모델은 현재까지 가장 큰 오픈 소스 대규모 언어 모델(LLM)로 두각을 나타내고 있습니다.
이러한 새로운 모델이 이전 모델과 차별화되는 점이 무엇인지 궁금할 수 있습니다. 이 기사를 자세히 살펴보면 Llama 3.1 모델의 릴리스가 AI 기술의 중요한 이정표임을 알 수 있습니다. 새로 출시된 모델은 자연어 처리에서 상당한 개선을 제공하며, 이전 버전에서는 볼 수 없었던 새로운 기능과 향상된 기능을 제공합니다. 이 릴리스는 복잡한 작업에 AI를 활용하는 방식을 바꾸어 연구원과 개발자 모두에게 강력한 도구 세트를 제공할 것을 약속합니다.
이번 글에서는 Llama 3.1 모델 제품군을 살펴보고 아키텍처, 주요 개선 사항, 실제 사용 사례 및 성능에 대한 자세한 비교를 분석합니다.
Meta의 최신 대규모 언어 모델인 Llama 3.1은 OpenAI의 Chat GPT-4o, Anthropic Claude 3.5 Sonnet과 같은 최상위 모델과 경쟁하며 AI 환경에서 상당한 진전을 이루고 있습니다.
이전 Llama 3 모델의 마이너 업데이트로 간주될 수 있지만, Meta는 새로운 모델 제품군에 몇 가지 주요 개선 사항을 도입하여 한 단계 더 발전시켰습니다. 제공 사항:
위의 모든 것 외에도 새로운 Llama 3.1 모델 제품군은 4,050억 개의 매개변수 모델을 통해 큰 발전을 이루었습니다. 이 엄청난 파라미터 수는 AI 개발에서 상당한 도약을 의미하며, 복잡한 텍스트를 이해하고 생성하는 모델의 능력을 크게 향상시킵니다. 405B 모델에는 광범위한 파라미터가 포함되어 있으며, 각 파라미터는 모델이 학습하는 동안 학습하는 신경망의 weights and biases 나타냅니다. 이를 통해 이 모델은 더 복잡한 언어 패턴을 포착할 수 있으며, 대규모 언어 모델에 대한 새로운 표준을 제시하고 AI 기술의 미래 잠재력을 보여줍니다. 이 대규모 모델은 다양한 작업에서 성능을 향상시킬 뿐만 아니라 텍스트 생성 및 이해 측면에서 AI가 달성할 수 있는 것의 한계를 뛰어넘습니다.
Llama 3.1은 최신 대규모 언어 모델의 초석인 디코더 전용 트랜스포머 모델 아키텍처를 활용합니다. 이 아키텍처는 복잡한 언어 작업을 처리하는 데 효율성과 효과가 뛰어난 것으로 알려져 있습니다. 트랜스포머를 사용함으로써 Llama 3.1은 인간과 유사한 텍스트를 이해하고 생성하는 데 탁월하며, LSTM 및 GRU와 같은 이전 아키텍처를 사용하는 모델보다 상당한 이점을 제공합니다.
또한, Llama 3.1 모델 제품군은 MoE(Mixture of Experts) 아키텍처를 활용하여 훈련 효율성과 안정성을 향상시킵니다. MoE 아키텍처를 피하면 MoE가 모델 안정성 및 성능에 영향을 줄 수 있는 복잡성을 야기할 수 있으므로 보다 일관되고 안정적인 훈련 프로세스를 보장합니다.
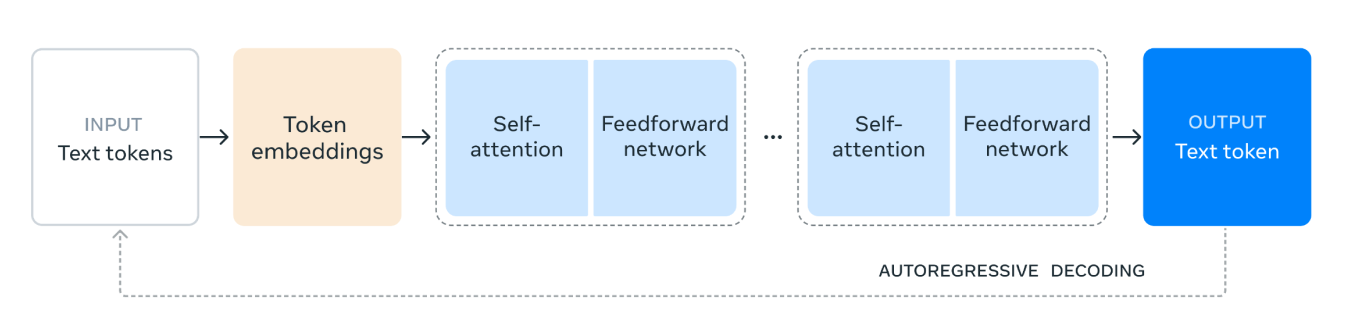
Llama 3.1 모델 아키텍처는 다음과 같이 작동합니다.
1. 입력 텍스트 토큰: 프로세스는 텍스트 토큰으로 구성된 입력으로 시작됩니다. 이러한 토큰은 모델이 처리할 단어 또는 서브워드와 같은 텍스트의 개별 단위입니다.
2. 토큰 임베딩: 텍스트 토큰은 토큰 임베딩으로 변환됩니다. 임베딩은 텍스트 내에서 토큰의 의미론적 의미와 관계를 캡처하는 토큰의 조밀한 벡터 표현입니다. 이 변환은 모델이 수치 데이터로 작업할 수 있도록 하므로 매우 중요합니다.
3. Self-Attention 메커니즘: Self-Attention을 통해 모델은 각 토큰을 인코딩할 때 입력 시퀀스에서 서로 다른 토큰의 중요도를 평가할 수 있습니다. 이 메커니즘은 모델이 시퀀스에서 위치에 관계없이 토큰 간의 컨텍스트와 관계를 이해하는 데 도움이 됩니다. Self-Attention 메커니즘에서 입력 시퀀스의 각 토큰은 숫자 벡터로 표시됩니다. 이러한 벡터는 쿼리, 키 및 값의 세 가지 다른 유형의 표현을 만드는 데 사용됩니다.
모델은 쿼리 벡터와 키 벡터를 비교하여 각 토큰이 다른 토큰에 얼마나 많은 주의를 기울여야 하는지 계산합니다. 이 비교를 통해 각 토큰이 다른 토큰과 관련하여 얼마나 중요한지를 나타내는 점수가 생성됩니다.
4. 피드포워드 네트워크: 자가 주의 프로세스가 끝나면 데이터는 피드포워드 네트워크를 통과합니다. 이 네트워크는 완전히 연결된 신경망으로, 데이터에 비선형 변환을 적용하여 모델이 복잡한 패턴을 인식하고 학습할 수 있도록 도와줍니다.
5. 반복 레이어: Self-Attention 및 피드포워드 네트워크 레이어가 여러 번 쌓입니다. 이 반복적인 적용을 통해 모델은 데이터에서 더 복잡한 종속성 및 패턴을 캡처할 수 있습니다.
6. 출력 텍스트 토큰: 마지막으로 처리된 데이터는 출력 텍스트 토큰을 생성하는 데 사용됩니다. 이 토큰은 입력 컨텍스트를 기반으로 시퀀스에서 다음 단어 또는 서브워드에 대한 모델의 예측입니다.
벤치마크 테스트 결과 Llama 3.1은 이러한 최첨단 모델에 뒤지지 않을 뿐만 아니라 특정 작업에서는 성능이 더 뛰어나 우수한 성능을 입증합니다.
Llama 3.1 모델은 150개 이상의 벤치마크 데이터 세트에 걸쳐 광범위한 평가를 거쳤으며, 여기서 다른 주요 대규모 언어 모델과 엄격하게 비교되었습니다. 새로 출시된 시리즈에서 가장 유능한 것으로 인정받는 Llama 3.1 405B 모델은 OpenAI의 GPT-4 및 Claude 3.5 Sonnet과 같은 업계 거물에 대해 벤치마킹되었습니다. 이러한 비교 결과는 Llama 3.1이 경쟁 우위를 입증하여 다양한 작업에서 뛰어난 성능과 기능을 보여줍니다.
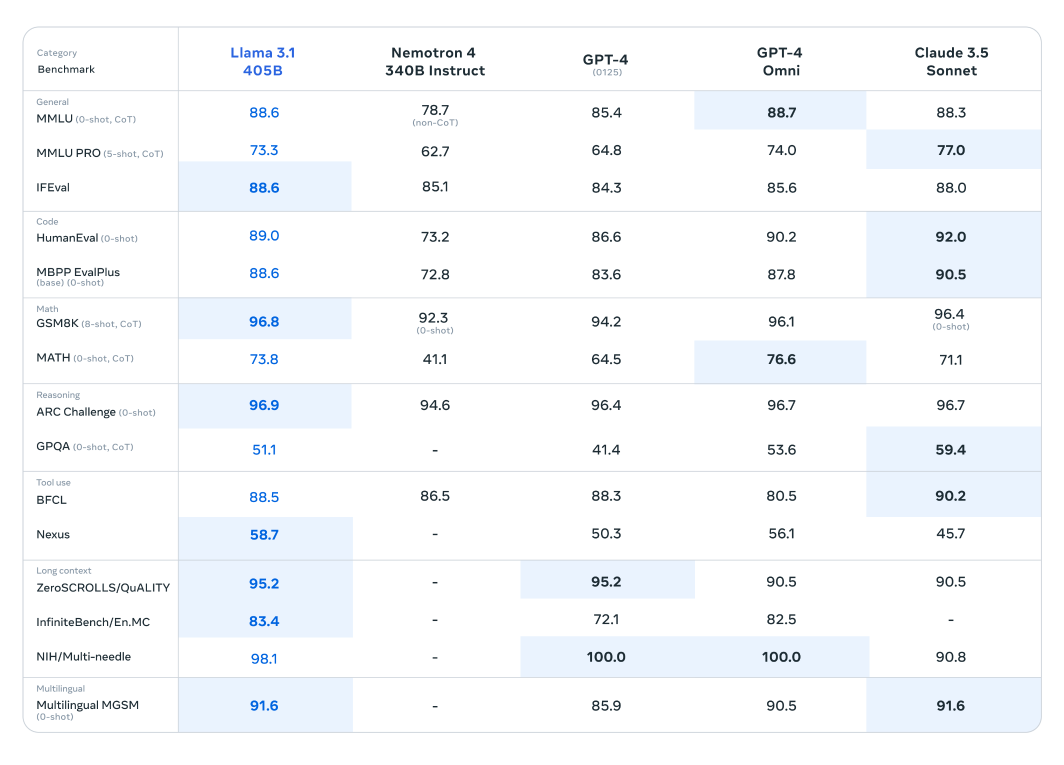
이 모델의 인상적인 매개변수 수와 고급 아키텍처를 통해 복잡한 이해 및 텍스트 생성에 탁월하며 특정 벤치마크에서 경쟁 제품을 능가하는 경우가 많습니다. 이러한 평가는 대규모 언어 모델 분야에서 새로운 표준을 설정하고 연구원과 개발자에게 다양한 애플리케이션을 위한 강력한 도구를 제공할 수 있는 Llama 3.1의 잠재력을 강조합니다.
더 작고 가벼운 Llama 모델은 또한 해당 모델에 비해 놀라운 성능을 보여줍니다. Llama 3.1 70B 모델은 Mistral 8x22B 및 GPT-3.5 Turbo와 같은 더 큰 모델에 대해 평가되었습니다. 예를 들어 Llama 3.1 70B 모델은 ARC Challenge 데이터 세트와 같은 추론 데이터 세트와 HumanEval 데이터 세트와 같은 코딩 데이터 세트에서 지속적으로 우수한 성능을 보여줍니다. 이러한 결과는 다양한 모델 크기에 걸쳐 Llama 3.1 시리즈의 다재다능함과 견고성을 강조하여 광범위한 응용 분야에 유용한 도구입니다.
또한, Llama 3.1 8B 모델은 Gemma 2 9B 및 Mistral 7B을 포함하여 유사한 크기의 모델과 비교되었습니다. 이러한 비교를 통해 Llama 3.1 8B 모델은 추론을 위한 GPQA 데이터 세트 및 코딩을 위한 MBPP EvalPlus와 같은 다양한 장르의 벤치마크 데이터 세트에서 경쟁 제품보다 성능이 우수함을 보여주며, 더 적은 매개변수 수에도 불구하고 효율성과 성능을 입증합니다.

Meta는 사용자를 위해 새 모델을 다양하고 실용적이며 유익한 방식으로 적용할 수 있도록 지원했습니다.
이제 사용자는 특정 사용 사례에 맞게 최신 Llama 3.1 모델을 미세 조정할 수 있습니다. 이 프로세스에는 이전에 노출되지 않은 새로운 외부 데이터에 대해 모델을 훈련하여 특정 애플리케이션에 대한 성능과 적응성을 향상시키는 작업이 포함됩니다. 미세 조정은 모델이 특정 도메인 또는 작업과 관련된 콘텐츠를 더 잘 이해하고 생성할 수 있도록 하여 상당한 이점을 제공합니다.
이제 Llama 3.1 모델을 검색 증강 생성(RAG) 시스템에 원활하게 통합할 수 있습니다. 이러한 통합을 통해 모델은 외부 데이터 소스를 동적으로 활용하여 정확하고 상황에 맞는 응답을 제공하는 능력을 향상시킬 수 있습니다. Llama 3.1은 대규모 데이터 세트에서 정보를 검색하여 생성 프로세스에 통합함으로써 지식 집약적인 작업에서 성능을 크게 향상시켜 사용자에게 더욱 정확하고 정보에 입각한 결과물을 제공합니다.
또한 4,050억 개의 파라미터 모델을 활용하여 고품질 합성 데이터를 생성하고 특정 사용 사례에 대한 특수 모델의 성능을 향상시킬 수 있습니다. 이 접근 방식은 Llama 3.1의 광범위한 기능을 활용하여 타겟팅되고 관련성 높은 데이터를 생성함으로써 맞춤형 AI 애플리케이션의 정확성과 효율성을 향상시킵니다.
Llama 3.1 릴리스는 대규모 언어 모델 분야에서 중요한 도약을 나타내며 AI 기술 발전에 대한 Meta의 의지를 보여줍니다.
Llama 3.1은 상당한 매개변수 수, 다양한 데이터 세트에 대한 광범위한 훈련, 강력하고 안정적인 훈련 프로세스에 대한 집중을 통해 자연어 처리 분야에서 성능과 기능에 대한 새로운 기준을 제시합니다. 텍스트 생성, 요약 또는 복잡한 대화 작업에서 Llama 3.1은 다른 주요 모델보다 경쟁 우위를 입증합니다. 이 모델은 오늘날 AI가 달성할 수 있는 한계를 뛰어넘을 뿐만 아니라 끊임없이 진화하는 인공 지능 환경에서 미래 혁신을 위한 발판을 마련합니다.
Ultralytics AI 기술의 한계를 뛰어넘기 위해 최선을 다하고 있습니다. 최첨단 AI 솔루션을 살펴보고 최신 혁신에 대한 최신 소식을 확인하려면 GitHub 리포지토리를 확인하세요. Discord의 활발한 커뮤니티에 참여하여 자율 주행 자동차 및 제조업과 같은 산업을 어떻게 혁신하고 있는지 알아보세요! 🚀


