


PaliGemma 2 da Google: informações sobre modelos VLM avançados

Junte-se a nós para vermos mais de perto os novos modelos de linguagem de visão da Google: PaliGemma 2. Estes modelos podem ajudar a compreender e analisar imagens e texto.

Junte-se a nós para vermos mais de perto os novos modelos de linguagem de visão da Google: PaliGemma 2. Estes modelos podem ajudar a compreender e analisar imagens e texto.
Em 5 de dezembro de 2024, Google apresentou o PaliGemma 2, a versão mais recente do seu modelo de visão-linguagem (VLM) de ponta. O PaliGemma 2 foi concebido para lidar com tarefas que combinam imagens e texto, como a criação de legendas, a resposta a perguntas visuais e a deteção de objectos em imagens.
Baseado no PaliGemma original, que já era uma ferramenta poderosa para legendas multilíngues e reconhecimento de objetos, o PaliGemma 2 traz várias melhorias importantes. Estas incluem tamanhos de modelo maiores, suporte para imagens de maior resolução e melhor desempenho em tarefas visuais complexas. Essas atualizações o tornam ainda mais flexível e eficaz para uma ampla gama de usos.
Neste artigo, analisaremos mais de perto o PaliGemma 2, incluindo como ele funciona, seus principais recursos e as aplicações onde ele se destaca. Vamos começar!
O PaliGemma 2 é construído sobre duas tecnologias principais: o codificador de visão SigLIP e o modelo de linguagem Gemma 2. O codificador SigLIP processa dados visuais, como imagens ou vídeos, e divide-os em recursos que o modelo pode analisar. Enquanto isso, o Gemma 2 lida com texto, permitindo que o modelo compreenda e gere linguagem multilingue. Juntos, eles formam um VLM, projetado para interpretar e conectar informações visuais e de texto de forma integrada.
O que torna o PaliGemma 2 um grande avanço é a sua escalabilidade e versatilidade. Ao contrário da versão original, o PaliGemma 2 vem em três tamanhos: 3 bilhões (3B), 10 bilhões (10B) e 28 bilhões (28B) de parâmetros. Esses parâmetros são como as configurações internas do modelo, ajudando-o a aprender e processar dados de forma eficaz. Ele também suporta diferentes resoluções de imagem (por exemplo, 224 x 224 pixels para tarefas rápidas e 896 x 896 para análises detalhadas), tornando-o adaptável para várias aplicações.
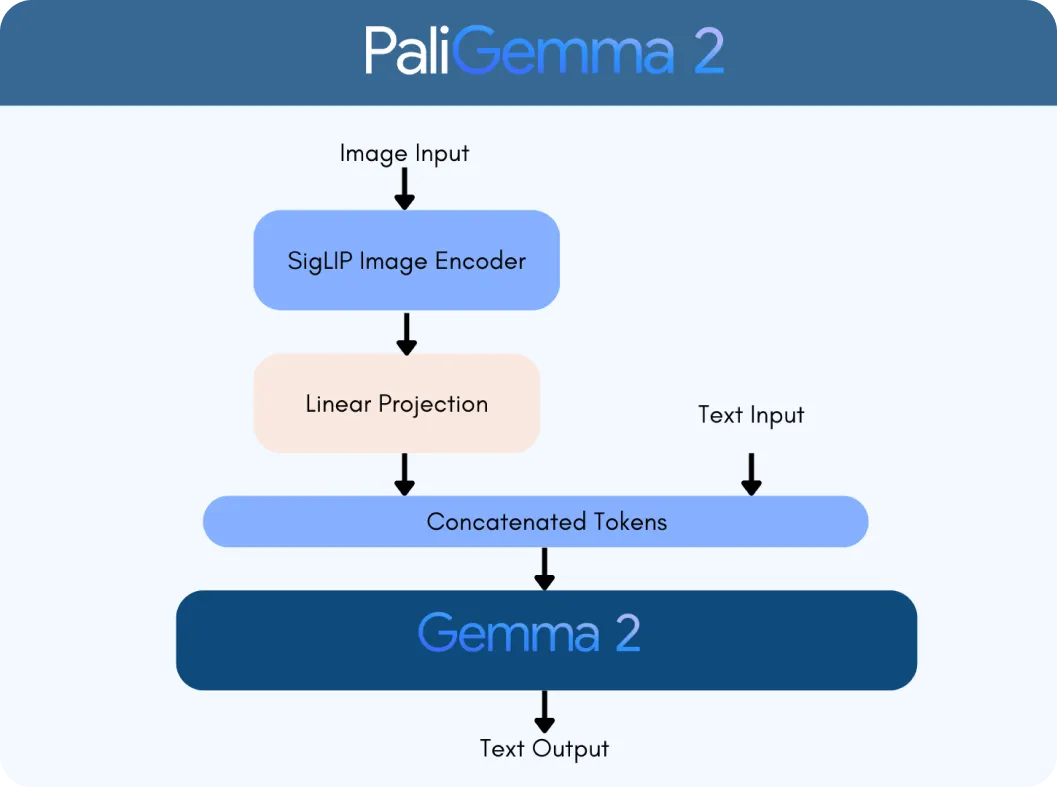
A integração dos recursos avançados de linguagem do Gemma 2 com o processamento de imagem do SigLIP torna o PaliGemma 2 significativamente mais inteligente. Ele pode lidar com tarefas como:
O PaliGemma 2 vai além do processamento de imagens e texto separadamente - ele junta-os de forma significativa. Por exemplo, pode compreender relações numa cena, como reconhecer que "O gato está sentado na mesa", ou identificar objetos enquanto adiciona contexto, como reconhecer um ponto de referência famoso.
Em seguida, vamos analisar um exemplo usando o gráfico mostrado na imagem abaixo para entender melhor como o PaliGemma 2 processa dados visuais e textuais. Digamos que você carregue este gráfico e pergunte ao modelo: "O que este gráfico representa?"

O processo começa com o codificador de visão SigLIP do PaliGemma 2 para analisar imagens e extrair as principais caraterísticas. No caso de um gráfico, isto inclui a identificação de elementos como eixos, pontos de dados e rótulos. O codificador é treinado para capturar padrões amplos e detalhes finos. Também utiliza o reconhecimento ótico de caracteres (OCR) para detect e processar qualquer texto incorporado na imagem. Estas caraterísticas visuais são convertidas em tokens, que são representações numéricas que o modelo pode processar. Estes tokens são depois ajustados utilizando uma camada de projeção linear, uma técnica que garante que podem ser combinados sem problemas com dados textuais.
Ao mesmo tempo, o modelo de linguagem Gemma 2 processa a consulta que o acompanha para determinar o seu significado e intenção. O texto da consulta é convertido em tokens, e estes são combinados com os tokens visuais do SigLIP para criar uma representação multimodal, um formato unificado que liga dados visuais e textuais.
Utilizando esta representação integrada, o PaliGemma 2 gera uma resposta passo a passo através da descodificação autorregressiva, um método onde o modelo prevê uma parte da resposta de cada vez com base no contexto que já processou.
Agora que entendemos como funciona, vamos explorar os principais recursos que tornam o PaliGemma 2 um modelo de visão-linguagem confiável:
Analisar a arquitetura da primeira versão do PaliGemma é uma boa maneira de ver as melhorias do PaliGemma 2. Uma das mudanças mais notáveis é a substituição do modelo de linguagem Gemma original pelo Gemma 2, que traz melhorias substanciais tanto no desempenho quanto na eficiência.
O Gemma 2, disponível nos tamanhos de 9B e 27B parâmetros, foi projetado para oferecer precisão e velocidade líderes na sua classe, ao mesmo tempo que reduz os custos de implementação. Ele consegue isso através de uma arquitetura redesenhada, otimizada para a eficiência da inferência em várias configurações de hardware, desde GPUs poderosas até configurações mais acessíveis.
Como resultado, o PaliGemma 2 é um modelo altamente preciso. A versão de 10B do PaliGemma 2 alcança uma pontuação de Sentença de Não Implicação (NES) mais baixa, de 20,3, em comparação com os 34,3 do modelo original, o que significa menos erros factuais nas suas saídas. Estes avanços tornam o PaliGemma 2 mais escalável, preciso e adaptável a uma gama mais vasta de aplicações, desde legendagem detalhada a resposta a perguntas visuais.
O PaliGemma 2 tem o potencial de redefinir indústrias, combinando perfeitamente a compreensão visual e da linguagem. Por exemplo, no que diz respeito à acessibilidade, pode gerar descrições detalhadas de objetos, cenas e relações espaciais, fornecendo assistência crucial a indivíduos com deficiência visual. Esta capacidade ajuda os utilizadores a compreender melhor os seus ambientes, oferecendo maior independência quando se trata de tarefas quotidianas.

Além da acessibilidade, o PaliGemma 2 está causando impacto em vários setores, incluindo:
Para experimentar o PaliGemma 2, pode começar com a demonstração interactiva do Hugging Face. Esta permite-lhe explorar as suas capacidades em tarefas como a legendagem de imagens e a resposta a perguntas visuais. Basta carregar uma imagem e fazer perguntas ao modelo sobre a mesma ou pedir uma descrição da cena.
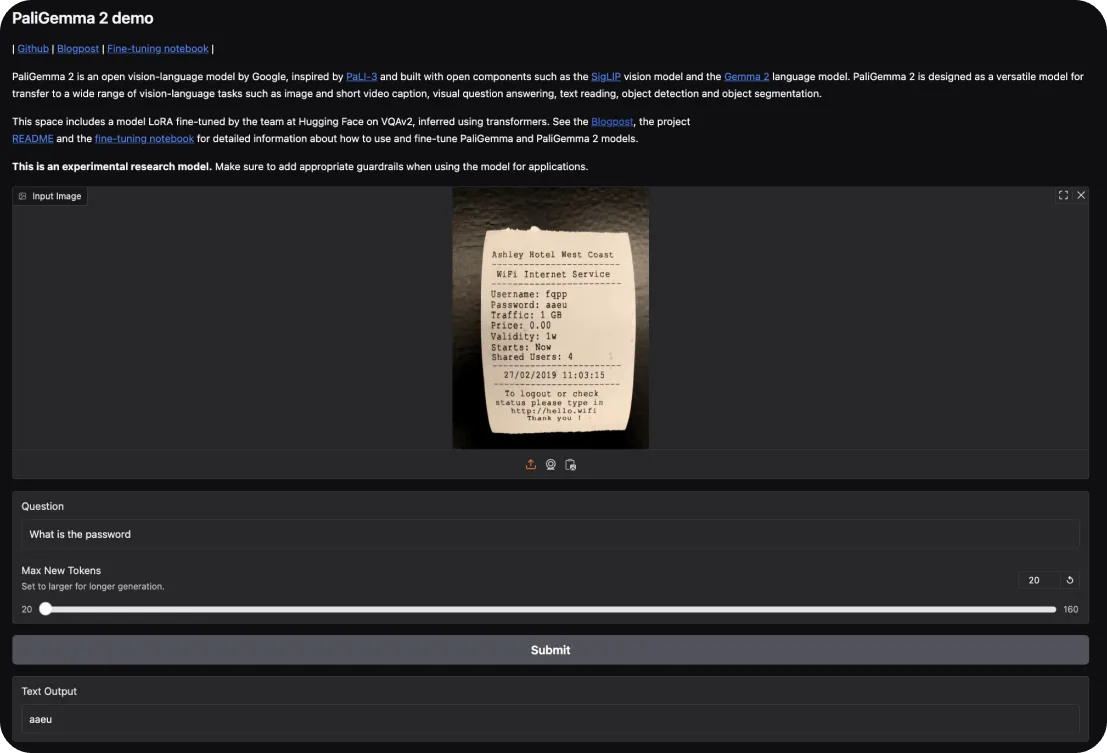
Se quiser aprofundar, aqui está como pode colocar a mão na massa:
Tendo entendido como começar com o PaliGemma 2, vamos dar uma olhada mais de perto em seus principais pontos fortes e fracos para ter em mente ao usar esses modelos.
Veja o que faz o PaliGemma 2 se destacar como um modelo de visão-linguagem:
Enquanto isso, aqui estão algumas áreas onde o PaliGemma 2 pode enfrentar limitações:
O PaliGemma 2 é um avanço fascinante na modelagem de visão-linguagem, oferecendo escalabilidade aprimorada, flexibilidade de ajuste fino e precisão. Pode servir como uma ferramenta valiosa para aplicações que vão desde soluções de acessibilidade e comércio eletrónico até diagnósticos de saúde e educação.
Embora tenha limitações, como requisitos computacionais e dependência de dados de alta qualidade, seus pontos fortes o tornam uma escolha prática para lidar com tarefas complexas que integram dados visuais e textuais. O PaliGemma 2 pode fornecer uma base robusta para pesquisadores e desenvolvedores explorarem e expandirem o potencial da IA em aplicações multimodais.
Participe da conversa sobre IA conferindo nosso repositório GitHub e comunidade. Leia sobre como a IA está avançando na agricultura e na área da saúde! 🚀


