


Изучение спецификации модели Claude 3: что это значит для vision AI

Ознакомьтесь с картой модели Claude 3 и ее влиянием на разработку Vision AI.

Ознакомьтесь с картой модели Claude 3 и ее влиянием на разработку Vision AI.
В последние годы Vision AI добился значительных успехов, произведя революцию в различных отраслях, от здравоохранения до розничной торговли. Понимание базовых моделей и их документации имеет решающее значение для эффективного использования этих достижений. Одним из таких важных инструментов в арсенале разработчика искусственного интеллекта (ИИ) является карта модели, которая предлагает всесторонний обзор характеристик и производительности модели ИИ.
В этой статье мы рассмотрим карту моделей Claude 3, разработанную компанией Anthropic, и ее последствия для развития ИИ Vision. Claude 3 - это новое семейство больших мультимодальных моделей, состоящее из трех вариантов: Claude 3 Opus - самая мощная модель; Claude 3 Sonnet, в которой сбалансированы производительность и скорость; и Claude 3 Haiku - самый быстрый и экономичный вариант. Каждая модель оснащена новыми возможностями технического зрения, позволяющими обрабатывать и анализировать данные изображений.
Что такое карточка модели? Карточка модели — это подробный документ, который предоставляет информацию о разработке, обучении и оценке модели машинного обучения. Она направлена на повышение прозрачности, подотчетности и этичного использования ИИ путем предоставления четкой информации о функциональности модели, предполагаемых вариантах использования и потенциальных ограничениях. Это может быть достигнуто путем предоставления более подробных данных о модели, таких как ее метрики оценки и ее сравнение с предыдущими моделями и другими конкурентами.
Метрики оценки имеют решающее значение для оценки производительности модели. В карте модели Claude 3 перечислены такие метрики, как точность, прецизионность, полнота и F1-мера, что дает четкое представление о сильных сторонах модели и областях, требующих улучшения. Эти метрики сравниваются с отраслевыми стандартами, демонстрируя конкурентоспособную производительность Claude 3.
Кроме того, Claude 3 опирается на сильные стороны своих предшественников, включая достижения в архитектуре и методах обучения. В карте модели Claude 3 сравнивается с более ранними версиями, выделяя улучшения в точности, эффективности и применимости к новым вариантам использования.
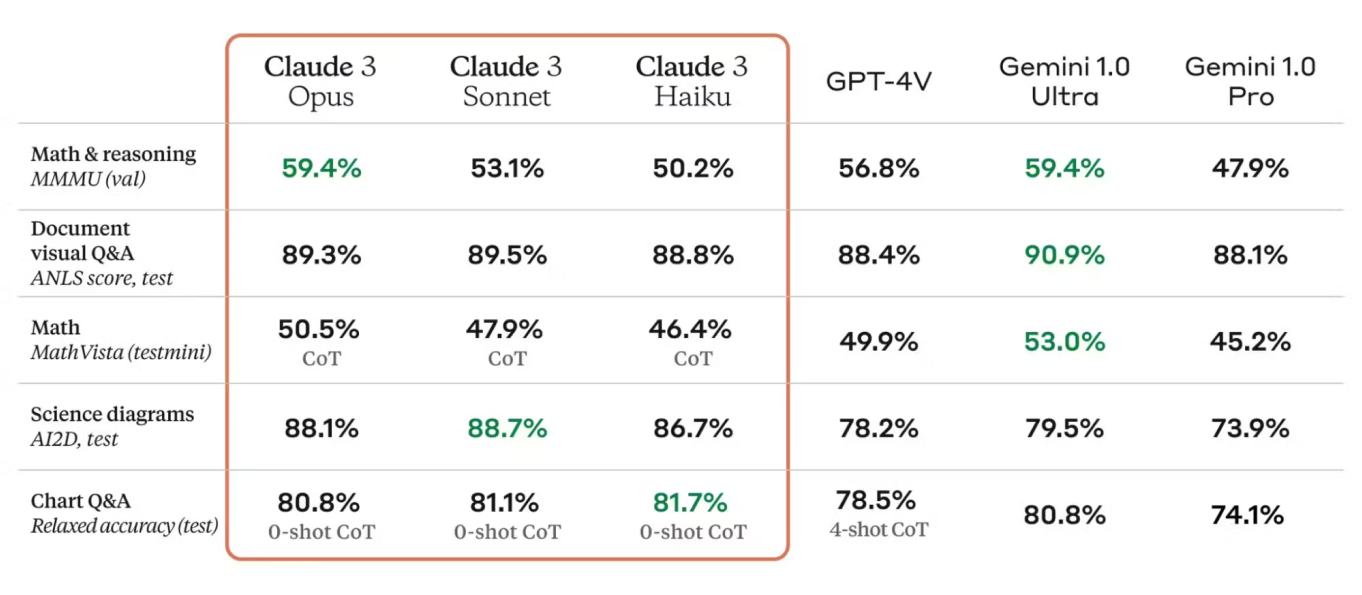
Архитектура и процесс обучения Claude 3 обеспечивают надежную производительность в различных задачах обработки естественного языка (NLP) и визуальных задачах. Он стабильно достигает высоких результатов в бенчмарках, демонстрируя свою способность эффективно выполнять сложные анализы языка.
Обучение Claude 3 на разнообразных наборах данных и использование методов увеличения данных обеспечивают его устойчивость и способность к обобщению в различных сценариях. Это делает модель универсальной и эффективной в широком спектре приложений.
Несмотря на то, что результаты Claude 3 заслуживают внимания, по своей сути это большая языковая модель (LLM). Хотя LLM, подобные Claude 3, могут выполнять различные задачи компьютерного зрения, они не были специально разработаны для таких задач, как обнаружение объектов, создание граничных блоков и сегментация изображений. В результате их точность в этих областях может не соответствовать точности моделей, специально созданных для компьютерного зрения, таких как Ultralytics YOLOv8. Тем не менее, LLM отлично работают в других областях, особенно в обработке естественного языка (NLP), где Claude 3 демонстрирует значительную силу, объединяя простые визуальные задачи с человеческими рассуждениями.

Возможности NLP (обработки естественного языка) относятся к способности модели ИИ понимать человеческий язык и отвечать на него. Эта возможность широко используется в приложениях Claude 3 в визуальной области, позволяя ему предоставлять контекстно-обогащенные описания, интерпретировать сложные визуальные данные и повышать общую производительность в задачах Vision AI.
Одной из впечатляющих возможностей Claude 3, особенно при использовании для задач Vision AI, является его способность обрабатывать и преобразовывать низкокачественные изображения с трудночитаемым почерком в текст. Эта функция демонстрирует расширенные возможности обработки и многомодального рассуждения модели. В этом разделе мы рассмотрим, как Claude 3 выполняет эту задачу, выделив основные механизмы и последствия для разработки Vision AI.
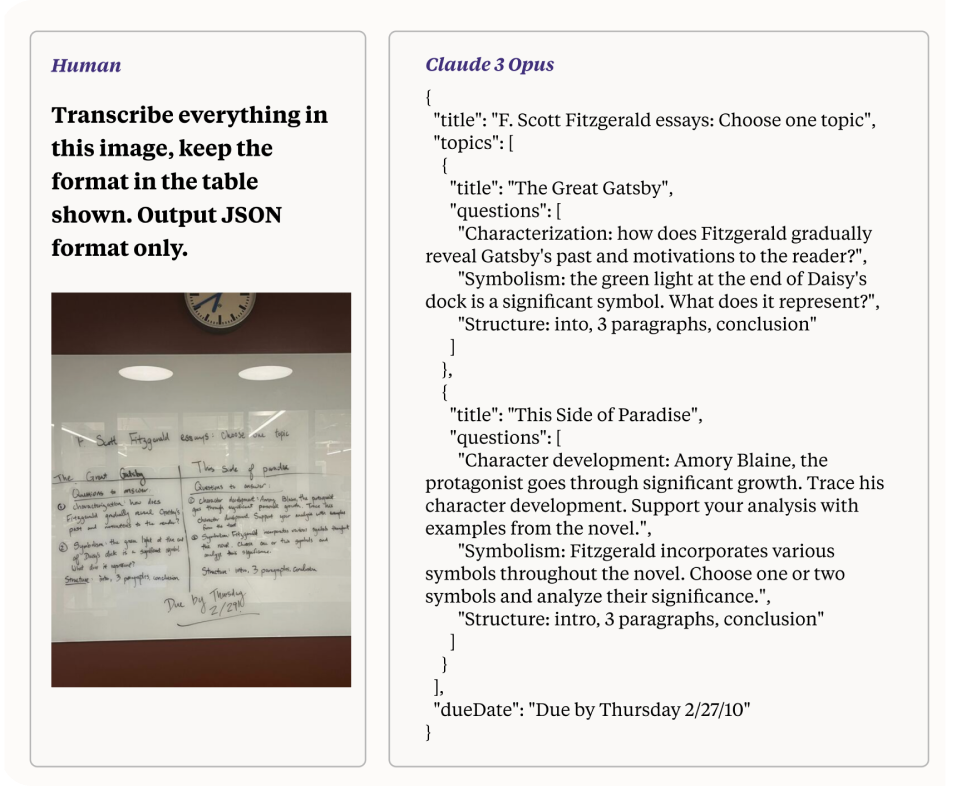
Преобразование фотографии низкого качества с трудночитаемым почерком в текст — сложная задача, включающая в себя несколько проблем:
Как упоминалось ранее, модели Claude 3 решают эти проблемы с помощью комбинации передовых методов в области компьютерного зрения и обработки естественного языка (NLP).
Архитектура Claude 3 позволяет ему выполнять сложные задачи рассуждения, используя визуальные входные данные. Например, как показано на рисунке 1, модель может интерпретировать диаграммы и графики, например, определять страны G7 на диаграмме об использовании Интернета, извлекать соответствующие данные и выполнять вычисления для анализа тенденций. Эти многоступенчатые рассуждения, такие как вычисление статистических различий в использовании Интернета среди возрастных групп, повышают точность и полезность модели в реальных приложениях.

Claude 3 превосходно преобразует изображения в подробные описания, демонстрируя свои мощные возможности как в компьютерном зрении, так и в обработке естественного языка. Когда Claude 3 получает изображение, он сначала использует сверточные нейронные сети (CNN) для извлечения ключевых признаков и идентификации объектов, закономерностей и контекстных элементов в визуальных данных.
После этого слои-трансформеры анализируют эти признаки, используя механизмы внимания для понимания взаимосвязей и контекста между различными элементами изображения. Этот мультимодальный подход позволяет Claude 3 генерировать точные, контекстуально богатые описания, не только идентифицируя объекты, но и понимая их взаимодействие и значение в сцене.

Большие языковые модели (БЯМ), такие как Claude 3, отлично подходят для обработки естественного языка, а не для компьютерного зрения. Хотя они могут описывать изображения, с такими задачами, как обнаружение объектов и сегментация изображений, лучше справляются модели, ориентированные на зрение, например YOLOv8. Эти специализированные модели оптимизированы для визуальных задач и обеспечивают лучшую производительность при анализе изображений. Кроме того, модель не может выполнять такие задачи, как создание ограничивающих рамок.
Объединение Claude 3 с системами компьютерного зрения может быть сложным и потребовать дополнительных этапов обработки для устранения разрыва между текстом и визуальными данными.
Claude 3 в основном обучается на огромных объемах текстовых данных, что означает, что ему не хватает обширных визуальных наборов данных, необходимых для достижения высокой производительности в задачах компьютерного зрения. В результате, хотя Claude 3 превосходно понимает и генерирует текст, у него нет возможности обрабатывать или анализировать изображения с тем же уровнем мастерства, который можно найти в моделях, специально разработанных для визуальных данных. Это ограничение делает его менее эффективным для приложений, требующих интерпретации или генерации визуального контента.
Как и другие большие языковые модели, Claude 3 настроен на непрерывное совершенствование. Будущие улучшения, вероятно, будут сосредоточены на улучшении визуальных задач, таких как обнаружение изображений и распознавание объектов, а также на достижениях в задачах обработки естественного языка. Это позволит получать более точные и подробные описания объектов и сцен, а также решать другие подобные задачи.
Наконец, текущие исследования Claude 3 будут направлены на повышение интерпретируемости, снижение предвзятости и улучшение обобщения на различных наборах данных. Эти усилия обеспечат надежную работу модели в различных приложениях и укрепят доверие и надежность к ее результатам.
Карточка модели Claude 3 — ценный ресурс для разработчиков и заинтересованных сторон в области Vision AI, предоставляющий подробную информацию об архитектуре, производительности и этических аспектах модели. Содействуя прозрачности и подотчетности, она помогает обеспечить ответственное и эффективное использование технологий ИИ. Поскольку Vision AI продолжает развиваться, роль карточек моделей, таких как Claude 3, будет иметь решающее значение для управления разработкой и укрепления доверия к системам ИИ.
В Ultralytics мы увлечены развитием технологий искусственного интеллекта. Чтобы ознакомиться с нашими решениями в области ИИ и быть в курсе наших последних инноваций, посетите наш репозиторий GitHub. Присоединяйтесь к нашему сообществу в Discord и узнайте, как мы преобразуем такие отрасли, как производство и производство самоуправляемых автомобилей! 🚀


