



RCNN ve nesne algılama üzerindeki etkisi hakkında bilgi edinin. RCNN'nin temel bileşenlerini, uygulamalarını ve Hızlı RCNN ve YOLO gibi tekniklerin geliştirilmesindeki rolünü ele alacağız.

RCNN ve nesne algılama üzerindeki etkisi hakkında bilgi edinin. RCNN'nin temel bileşenlerini, uygulamalarını ve Hızlı RCNN ve YOLO gibi tekniklerin geliştirilmesindeki rolünü ele alacağız.
Nesne alg ılama, otonom sürüş, gözetim ve tıbbi görüntüleme gibi uygulamalar için görüntülerdeki veya videolardaki nesneleri tanıyabilen ve konumlandırabilen bir bilgisayarla görme görevidir. Viola-Jones dedektörü ve Destek Vektör Makineleri (SVM) ile Yönlendirilmiş Gradyanların Histogramı (HOG) gibi daha önceki nesne algılama yöntemleri, el yapımı özelliklere ve kayan pencerelere dayanıyordu. Bu yöntemler genellikle çeşitli şekil ve boyutlarda birden fazla nesnenin bulunduğu karmaşık sahnelerdeki nesneleri doğru bir şekilde detect etmekte zorlanıyordu.
Bölge tabanlı Evrişimsel Sinir Ağları (R-CNN) nesne algılama yöntemimizi değiştirmiştir. Bilgisayarla görme tarihinde önemli bir kilometre taşıdır. gibi modellerin nasıl çalıştığını anlamak için YOLOv8 ortaya çıktığında, öncelikle R-CNN gibi modelleri anlamamız gerekir.
Ross Girshick ve ekibi tarafından oluşturulan R-CNN model mimarisi, bölge önerileri oluşturur, önceden eğitilmiş bir Evrişimsel Sinir Ağı (CNN) ile özellikleri çıkarır, nesneleri sınıflandırır ve sınırlayıcı kutuları iyileştirir. Bu göz korkutucu görünebilir, ancak bu makalenin sonunda R-CNN'nin nasıl çalıştığı ve neden bu kadar etkili olduğu konusunda net bir anlayışa sahip olacaksınız. Hadi bir göz atalım!
R-CNN modelinin nesne algılama süreci üç ana adım içerir: bölge önerileri oluşturma, özellikleri çıkarma ve nesneleri sınıflandırırken sınırlayıcı kutularını iyileştirme. Her adımı inceleyelim.
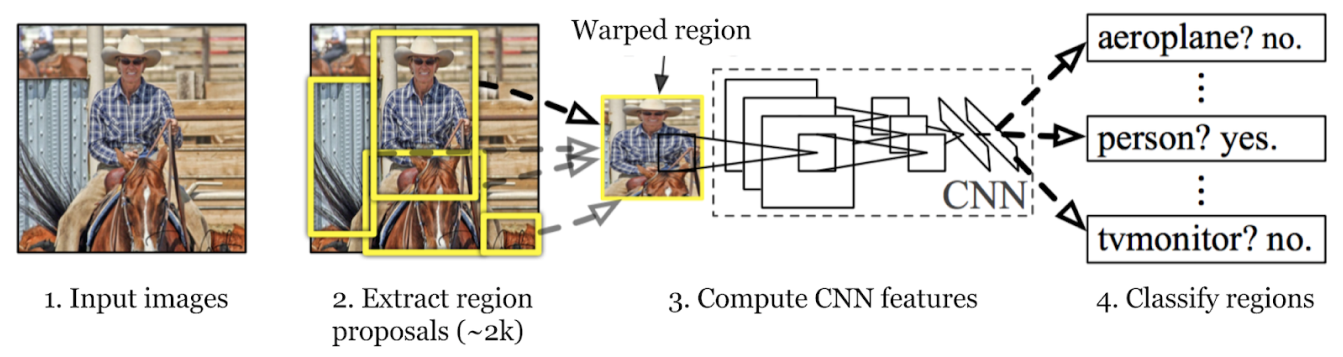
İlk adımda, R-CNN modeli çok sayıda bölge önerisi oluşturmak için görüntüyü tarar. Bölge önerileri, nesneler içerebilecek potansiyel alanlardır. Seçici Arama gibi yöntemler, görüntünün renk, doku ve şekil gibi çeşitli yönlerine bakmak ve onu farklı parçalara ayırmak için kullanılır. Seçici Arama, görüntüyü daha küçük parçalara bölerek başlar, ardından benzer olanları birleştirerek daha büyük ilgi alanları oluşturur. Bu işlem, yaklaşık 2.000 bölge önerisi oluşturulana kadar devam eder.
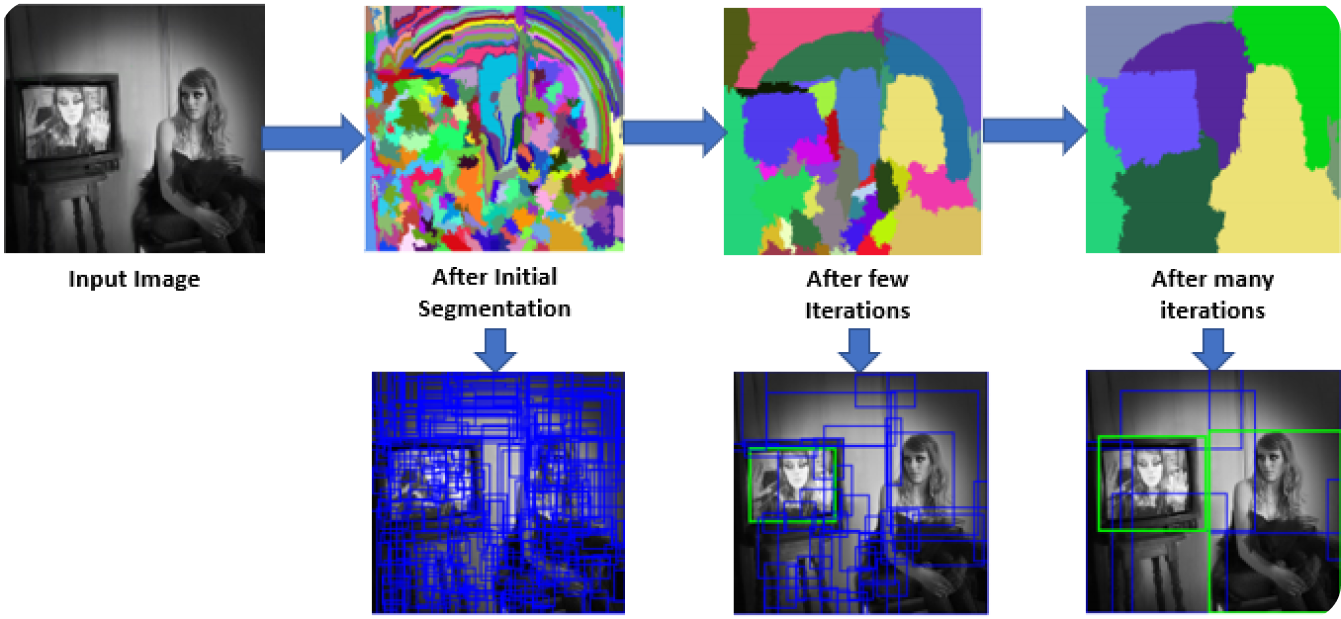
Bu bölge önerileri, bir nesnenin bulunabileceği tüm olası noktaları belirlemeye yardımcı olur. Sonraki adımlarda, model tüm görüntü yerine bu belirli alanlara odaklanarak en alakalı alanları verimli bir şekilde işleyebilir. Bölge önerilerini kullanmak, eksiksizliği hesaplama verimliliği ile dengeler.
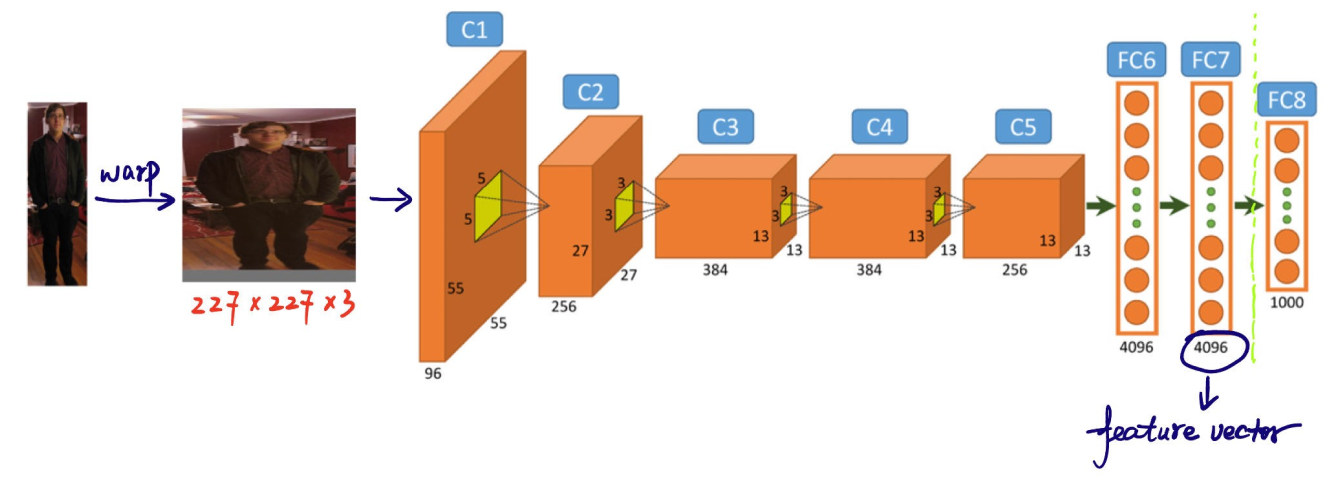
R-CNN modelinin nesne tespiti sürecindeki bir sonraki adım, bölge önerilerinden özellikleri çıkarmaktır. Her bölge önerisi, CNN'in beklediği tutarlı bir boyuta (örneğin, 224x224 piksel) yeniden boyutlandırılır. Yeniden boyutlandırma, CNN'in her öneriyi verimli bir şekilde işlemesine yardımcı olur. Eğrilmeden önce, daha iyi özellik çıkarımı için daha fazla çevre bilgisi sağlamak amacıyla her bölge önerisinin boyutu, bölgenin etrafında 16 piksel ek bağlam içerecek şekilde biraz genişletilir.
Yeniden boyutlandırıldıktan sonra bu bölge önerileri, genellikle ImageNet gibi büyük bir veri kümesi üzerinde önceden eğitilmiş olan AlexNet gibi bir CNN'e beslenir. CNN, kenarlar, dokular ve desenler gibi önemli ayrıntıları yakalayan yüksek boyutlu özellik vektörlerini çıkarmak için her bölgeyi işler. Bu özellik vektörleri, bölgelerdeki temel bilgileri yoğunlaştırır. Ham görüntü verilerini, modelin daha fazla analiz için kullanabileceği bir biçime dönüştürürler. Sonraki aşamalarda nesnelerin doğru bir şekilde sınıflandırılması ve konumlandırılması, görsel bilgilerin anlamlı verilere dönüştürülmesine bağlıdır.
Üçüncü adım, bu bölgelerdeki nesneleri classify . Bu, teklifler içinde bulunan her nesnenin kategorisinin veya sınıfının belirlenmesi anlamına gelir. Çıkarılan özellik vektörleri daha sonra bir makine öğrenimi sınıflandırıcısından geçirilir.
R-CNN durumunda, Destek Vektör Makineleri (SVM'ler) yaygın olarak bu amaç için kullanılır. Her SVM, özellik vektörlerini analiz ederek ve belirli bir bölgenin o sınıfın bir örneğini içerip içermediğine karar vererek belirli bir nesne sınıfını tanımak için eğitilir. Esasen, her nesne kategorisi için, her bölge teklifini o belirli nesne için kontrol eden özel bir sınıflandırıcı vardır.
Eğitim sırasında, sınıflandırıcılara pozitif ve negatif örneklerle etiketlenmiş veriler verilir:
Sınıflandırıcılar, bu örnekler arasında ayrım yapmayı öğrenir. Sınırlayıcı kutu regresyonu, başlangıçta önerilen sınırlayıcı kutuları gerçek nesne sınırlarıyla daha iyi eşleşecek şekilde ayarlayarak, tespit edilen nesnelerin konumunu ve boyutunu daha da iyileştirir. R-CNN modeli, sınıflandırma ve sınırlayıcı kutu regresyonunu birleştirerek nesneleri tanımlayabilir ve doğru bir şekilde konumlandırabilir.
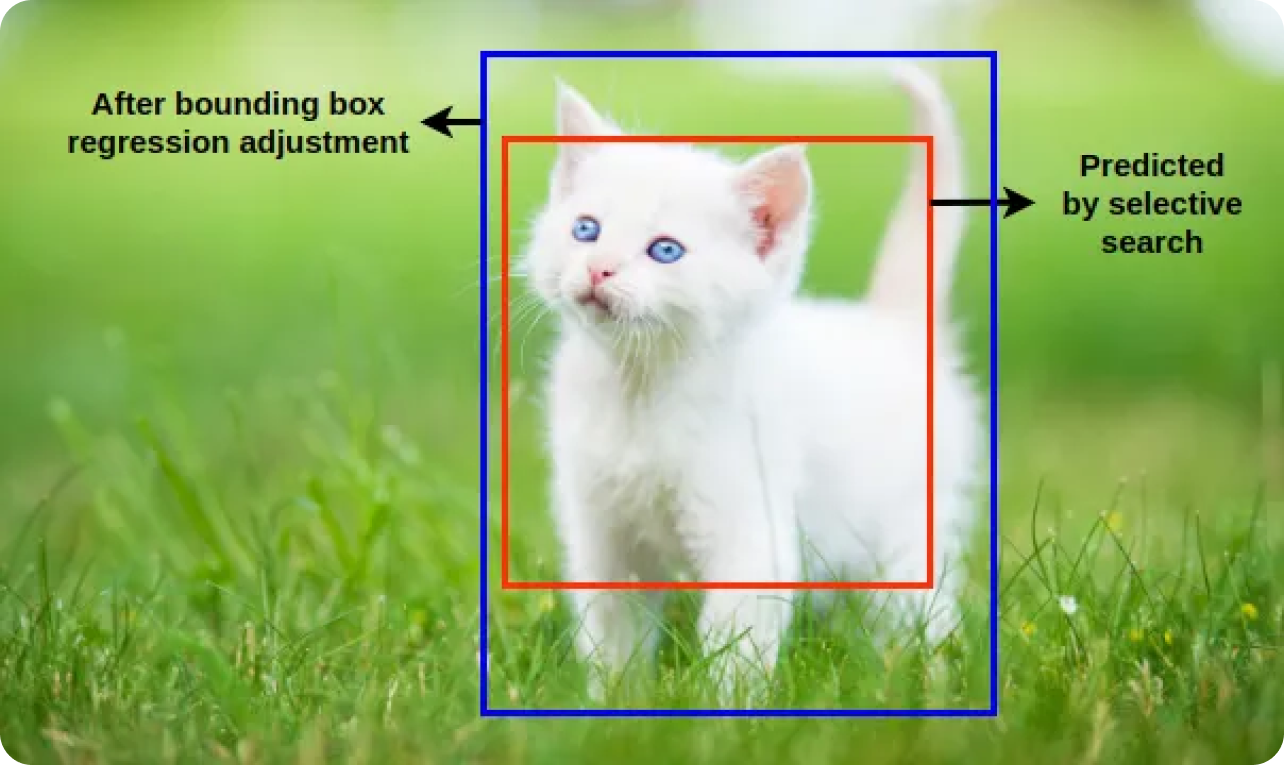
Sınıflandırma ve sınırlayıcı kutu regresyonu adımlarından sonra, model genellikle aynı nesne için birden fazla örtüşen sınırlayıcı kutu üretir. Bu tespitleri iyileştirmek ve en doğru kutuları tutmak için Maksimum Olmayan BastırmaNMS) uygulanır. Model, NMS uygulayarak gereksiz ve örtüşen kutuları ortadan kaldırır ve yalnızca en emin tespitleri tutar.
NMS , tüm sınırlayıcı kutuların güven puanlarını (tespit edilen bir nesnenin gerçekte ne kadar olası olduğunu gösterir) değerlendirerek ve daha yüksek puanlı kutularla önemli ölçüde örtüşenleri bastırarak çalışır.

İşte NMS'deki adımların bir dökümü:
Hepsini bir araya getirmek gerekirse, R-CNN modeli, bölge önerileri oluşturarak, CNN ile özellikleri çıkararak, nesneleri sınıflandırarak ve sınırlayıcı kutu regresyonu ile konumlarını iyileştirerek ve yalnızca en doğru tespitleri koruyan Maksimum Olmayan BastırmaNMS) kullanarak nesneleri tespit eder.
R-CNN, nesne algılama tarihinde bir dönüm noktası olan modeldir, çünkü doğruluğu ve performansı büyük ölçüde artıran yeni bir yaklaşım getirmiştir. R-CNN'den önce, nesne algılama modelleri hız ve hassasiyeti dengelemede zorlanıyordu. R-CNN'nin bölge önerileri oluşturma ve özellik çıkarımı için CNN'leri kullanma yöntemi, görüntüler içindeki nesnelerin hassas bir şekilde lokalize edilmesini ve tanımlanmasını sağlar.
R-CNN, Fast R-CNN, Faster R-CNN ve Mask R-CNN gibi modellerin önünü açarak verimliliği ve doğruluğu daha da artırdı. Derin öğrenmeyi bölge tabanlı analizle birleştirerek, R-CNN bu alanda yeni bir standart belirledi ve çeşitli gerçek dünya uygulamaları için olanaklar yarattı.
R-CNN'nin ilginç bir kullanım alanı da tıbbi görüntülemedir. R-CNN modelleri, MRI ve CT taramaları gibi tıbbi taramalarda beyin tümörleri gibi farklı tümör türlerini detect etmek ve classify için kullanılmıştır. Tıbbi görüntülemede R-CNN modelinin kullanılması teşhis doğruluğunu artırır ve radyologların maligniteleri erken bir aşamada tanımlamasına yardımcı olur. R-CNN'nin küçük ve erken evre tümörleri bile detect etme yeteneği, kanser gibi hastalıkların tedavisinde ve prognozunda önemli bir fark yaratabilir.
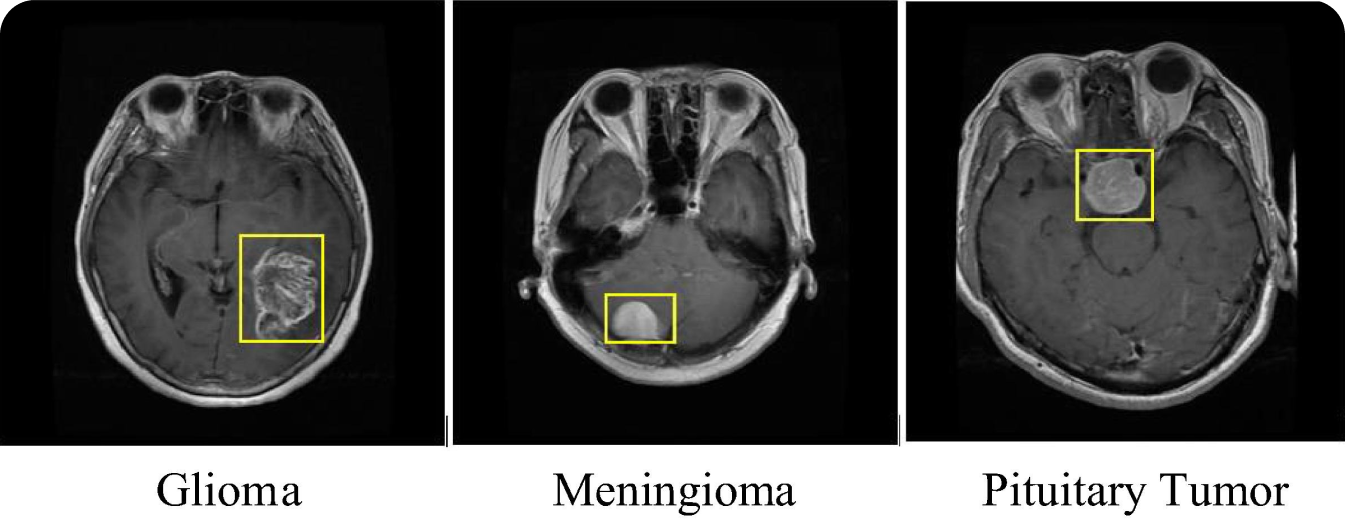
R-CNN modeli, tümör tespitine ek olarak diğer tıbbi görüntüleme görevlerine de uygulanabilir. Örneğin, kırıkları belirleyebilir, göz taramalarında retina hastalıklarını detect edebilir ve pnömoni ve COVID-19 gibi durumlar için akciğer görüntülerini analiz edebilir. Tıbbi sorun ne olursa olsun, erken teşhis daha iyi hasta sonuçlarına yol açabilir. Sağlık hizmeti sağlayıcıları, R-CNN'nin anomalileri tanımlama ve lokalize etme konusundaki hassasiyetini uygulayarak tıbbi teşhislerin güvenilirliğini ve hızını artırabilir. Teşhis sürecini kolaylaştıran nesne tespiti sayesinde hastalar zamanında ve doğru tedavi planlarından faydalanabilir.
Etkileyici olmasına rağmen, R-CNN'nin yüksek hesaplama karmaşıklığı ve yavaş çıkarım süreleri gibi bazı dezavantajları vardır. Bu dezavantajlar, R-CNN modelini gerçek zamanlı uygulamalar için uygunsuz hale getirir. Bölge önerilerini ve sınıflandırmaları ayrı adımlara ayırmak, daha az verimli performansa yol açabilir.
Yıllar içinde, bu endişeleri gidermiş çeşitli nesne algılama modelleri ortaya çıktı. Fast R-CNN, bölge önerilerini ve CNN özellik çıkarımını tek bir adımda birleştirerek süreci hızlandırır. Faster R-CNN, öneri oluşturmayı kolaylaştırmak için bir Bölge Önerisi Ağı (RPN) sunarken, Mask R-CNN daha ayrıntılı algılamalar için piksel düzeyinde segmentasyon ekler.

Faster R-CNN ile aynı zamanlarda, YOLO (You Only Look Once) serisi gerçek zamanlı nesne algılamayı geliştirmeye başladı. YOLO modelleri, sınırlayıcı kutuları ve sınıf olasılıklarını ağ üzerinden tek bir geçişte tahmin eder. Örneğin Ultralytics YOLOv8 birçok bilgisayarla görme görevi için gelişmiş özelliklerle gelişmiş doğruluk ve hız sunar.
RCNN, derin öğrenmenin nesne algılamayı nasıl değiştirebileceğini göstererek bilgisayarla görmede oyunu değiştirdi. Başarısı bu alanda pek çok yeni fikre ilham verdi. Daha Hızlı R-CNN ve YOLO gibi yeni modeller RCNN'nin kusurlarını gidermek için ortaya çıkmış olsa da, katkısı hatırlanması gereken büyük bir kilometre taşıdır.
Araştırmalar devam ettikçe, daha da iyi ve daha hızlı nesne algılama modelleri göreceğiz. Bu gelişmeler sadece makinelerin dünyayı nasıl anladığını iyileştirmekle kalmayacak, aynı zamanda birçok sektörde de ilerlemeye yol açacaktır. Nesne algılamanın geleceği heyecan verici görünüyor!
Yapay zeka hakkında keşfetmeye devam etmek ister misiniz? Ultralytics topluluğunun bir parçası olun! En son yapay zeka yeniliklerimizi görmek için GitHub depomuzu keşfedin. Tarım ve üretim gibi çeşitli sektörleri kapsayan yapay zeka çözümlerimize göz atın. Öğrenmek ve ilerlemek için bize katılın!


