



探索视觉模型的历史、成就、挑战和未来方向。

探索视觉模型的历史、成就、挑战和未来方向。
想象一下,走进一家商店,摄像头识别您的面部,分析您的情绪,并实时推荐根据您的喜好量身定制的产品。这不是科幻小说,而是现代视觉模型实现的现实。根据《财富商业洞察》的一份报告,2023 年全球计算机视觉市场规模估值为 203.1 亿美元,预计将从 2024 年的 254.1 亿美元增长到 2032 年的 1757.2 亿美元,这反映了这项技术在各个行业的快速发展和日益普及。
计算机视觉领域使计算机能够detect、识别和分析图像中的物体。与其他人工智能相关领域类似,计算机视觉在过去几十年中经历了快速发展,取得了显著进步。
计算机视觉的历史悠久。早期,计算机视觉模型能够检测简单的形状和边缘,通常仅限于识别几何图案或区分明暗区域等基本任务。然而,今天的模型可以执行复杂的任务,例如实时目标检测、面部识别,甚至可以以极高的准确性和效率解读面部表情中的情绪。这种巨大的进步突出了在计算能力、算法复杂性和用于训练的大量数据的可用性方面取得的令人难以置信的进步。
在本文中,我们将探讨计算机视觉发展史上的重要里程碑。我们将回顾其早期发展,深入研究卷积神经网络 (CNN) 的变革性影响,并考察随后的重大进展。
与其他人工智能领域一样,计算机视觉的早期发展始于基础研究和理论工作。一个重要的里程碑是 Lawrence G. Roberts 在 20 世纪 60 年代初的论文“三维固体的机器感知”中记录的关于 3D 目标识别的开创性工作。他的贡献为该领域未来的发展奠定了基础。
早期的计算机视觉研究侧重于边缘检测和特征提取等图像处理技术。20 世纪 60 年代末开发的索贝尔算子等算法,是最早通过计算图像强度梯度来detect 边缘的算法之一。

诸如 Sobel 和 Canny 边缘检测器之类的技术在识别图像中的边界方面发挥了关键作用,这对于识别对象和理解场景至关重要。
在 20 世纪 70 年代,模式识别成为计算机视觉的一个关键领域。研究人员开发了识别图像中的形状、纹理和对象的方法,这为更复杂的视觉任务铺平了道路。

早期的一种模式识别方法涉及模板匹配,即将图像与一组模板进行比较,以找到最佳匹配。这种方法受到其对尺度、旋转和噪声变化的敏感性的限制。
早期的计算机视觉系统受到当时有限的计算能力的制约。20世纪60年代和70年代的计算机体积庞大、价格昂贵,且处理能力有限。
深度学习和卷积神经网络 (CNN) 标志着计算机视觉领域的一个关键时刻。这些进步极大地改变了计算机解释和分析视觉数据的方式,从而实现了以前认为不可能的各种应用。
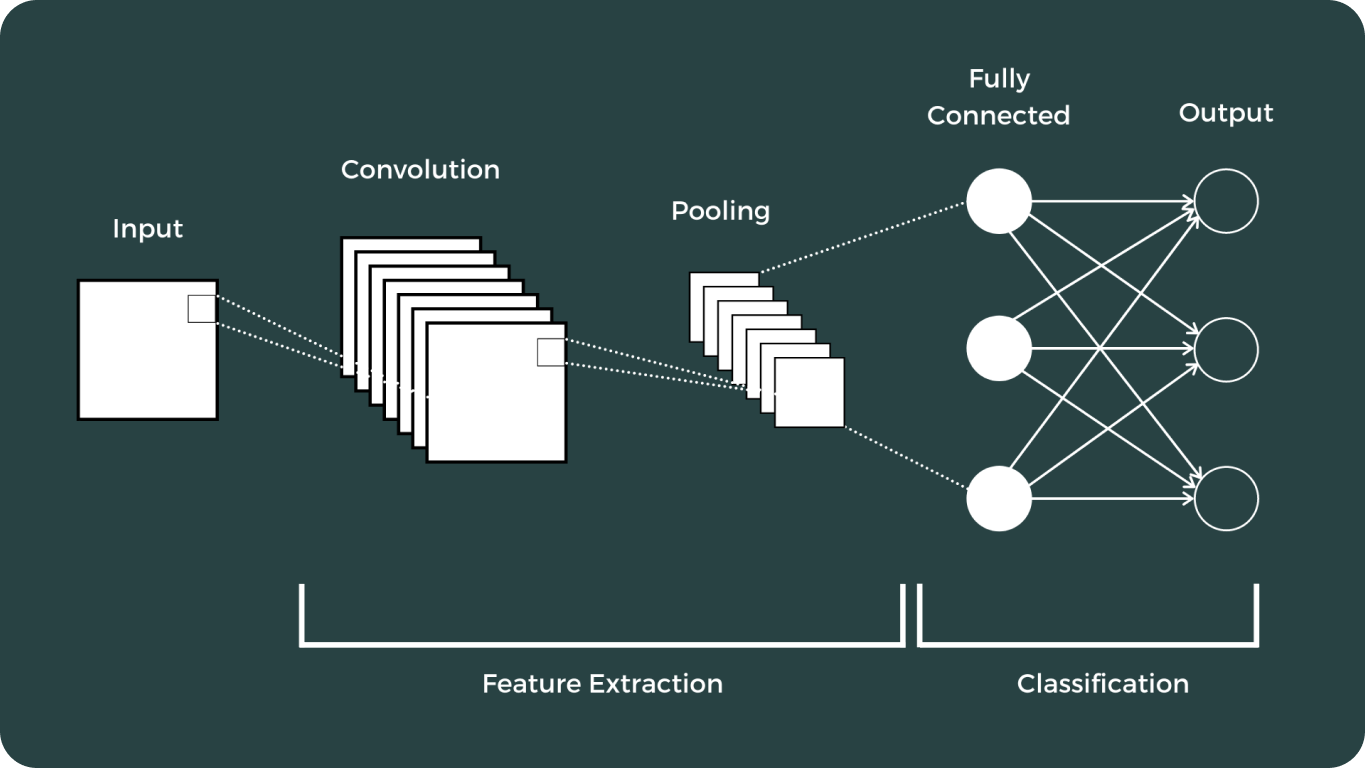
视觉模型的发展历程非常广泛,其中一些最著名的模型包括:
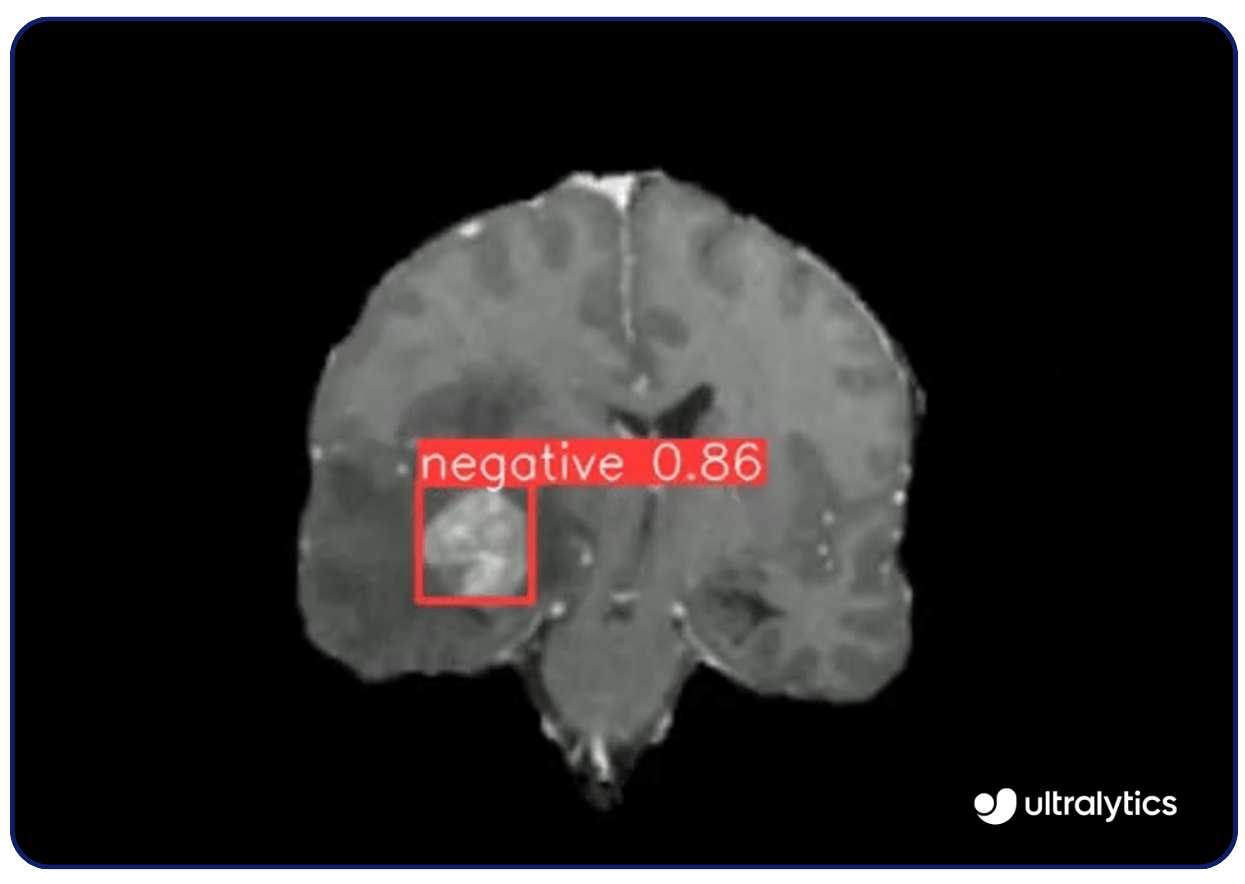
计算机视觉的用途非常广泛。例如,视觉模型 Ultralytics YOLOv8等视觉模型可用于医学成像,detect 癌症和糖尿病视网膜病变等疾病。它们能高精度地分析 X 射线、核磁共振成像和 CT 扫描,及早发现异常。这种早期检测能力可以及时干预并改善患者的治疗效果。
计算机视觉模型通过分析野生动物栖息地的图像和视频,帮助监测和保护濒危物种。它们可以识别和track 动物行为,提供有关其数量和活动的数据。这项技术为保护老虎和大象等物种的保护战略和决策提供了依据。
在视觉 AI 的帮助下,可以监控其他环境威胁,例如野火和森林砍伐,从而确保地方当局能够快速响应。

尽管视觉模型已经取得了显著的成就,但由于其极端的复杂性和苛刻的开发性质,它们面临着许多挑战,需要持续的研究和未来的进步。
视觉模型,尤其是深度学习模型,通常被视为透明度有限的“黑盒”。这是因为此类模型非常复杂。缺乏可解释性会阻碍信任和责任,尤其是在医疗保健等关键应用中。
训练和部署最先进的 AI 模型需要大量的计算资源。对于视觉模型来说尤其如此,因为视觉模型通常需要处理大量的图像和视频数据。高清图像和视频是数据密集型训练输入,这增加了计算负担。例如,单个高清图像可能占用几兆字节的存储空间,这使得训练过程资源密集且耗时。
这就需要强大的硬件和优化的计算机视觉算法来处理开发有效视觉模型所涉及的大量数据和复杂计算。对更高效的架构、模型压缩和硬件加速器(如GPU和TPU)的研究是推动视觉模型未来发展的关键领域。
这些改进旨在减少计算需求,提高处理效率。此外,利用先进的预训练模型,如 YOLOv8等先进的预训练模型,可以大大减少对大量训练的需求,从而简化开发流程并提高效率。
如今,视觉模型的应用非常广泛,从医疗保健(如肿瘤检测)到日常用途(如交通监控)。这些先进的模型通过提供前所未有的增强的准确性、效率和能力,为无数行业带来了创新。
随着技术的不断进步,视觉模型在创新和改善生活和工业各个方面的潜力仍然是无限的。这种持续的演变强调了在计算机视觉领域继续进行研究和开发的重要性。
对视觉人工智能的未来充满好奇?如需了解最新进展的更多信息,请访问Ultralytics 文档,并查看Ultralytics GitHub和YOLOv8 GitHub 上的项目。此外,要深入了解人工智能在各行各业的应用,有关自动驾驶汽车和制造业的解决方案页面提供了特别有用的信息。


