



探索 Meta 全新的 Llama 3.1 开源模型系列,包括通用的 8B、全能的 70B 以及旗舰版的 405B,这是他们迄今为止最大、最先进的模型。

探索 Meta 全新的 Llama 3.1 开源模型系列,包括通用的 8B、全能的 70B 以及旗舰版的 405B,这是他们迄今为止最大、最先进的模型。
2024 年 7 月 23 日,Meta 发布了新的 Llama 3.1 开源模型系列,其中包括通用的 8B、强大的 70B 和 Llama 3.1 405B 模型,其中最新的模型是迄今为止最大的开源大型语言模型 (LLM)。
您可能想知道这些新模型与之前的模型有何不同。正如我们将在本文中深入探讨的那样,您会发现 Llama 3.1 模型的发布标志着 AI 技术的一个重要里程碑。新发布的模型在自然语言处理方面提供了显着改进;此外,它们还引入了早期版本中没有的新功能和增强功能。此次发布有望改变我们利用 AI 执行复杂任务的方式,为研究人员和开发人员提供一套强大的工具。
在本文中,我们将探讨 Llama 3.1 系列模型,深入研究它们的架构、主要改进、实际用途以及对其性能的详细比较。
Meta 的最新大型语言模型 Llama 3.1 在人工智能领域取得了长足进步,其能力可与 OpenAI 的 Chat GPT-4o和Anthropic的 Claude 3.5 Sonnet 等顶级模型相媲美。
即使它可能被认为是先前Llama 3模型的一个小更新,Meta 通过对新模型系列引入一些关键改进,使其更进一步,提供:
除上述所有功能外,全新的 Llama 3.1 模型系列还拥有令人印象深刻的 4050 亿个参数模型,这是一项重大进步。这一可观的参数数代表了人工智能发展的重大飞跃,大大增强了模型理解和生成复杂文本的能力。405B 模型包含大量参数,每个参数指的是模型在训练过程中学习的神经网络中的weights and biases 。这使得该模型能够捕捉到更复杂的语言模式,为大型语言模型设定了新标准,并展示了人工智能技术的未来潜力。这个大型模型不仅提高了在各种任务中的性能,还推动了人工智能在文本生成和理解方面的发展。
Llama 3.1 利用解码器专用的 transformer模型架构,这是现代大型语言模型的基石。这种架构以其处理复杂语言任务的效率和有效性而闻名。转换器的使用使 Llama 3.1 在理解和生成类人文本方面表现出色,与使用 LSTM 和 GRU 等旧架构的模型相比具有显著优势。
此外,Llama 3.1 模型系列采用了混合专家(MoE)架构,从而提高了训练效率和稳定性。避免使用 MoE 架构可确保更一致和可靠的训练过程,因为 MoE 有时会引入可能影响模型稳定性和性能的复杂性。
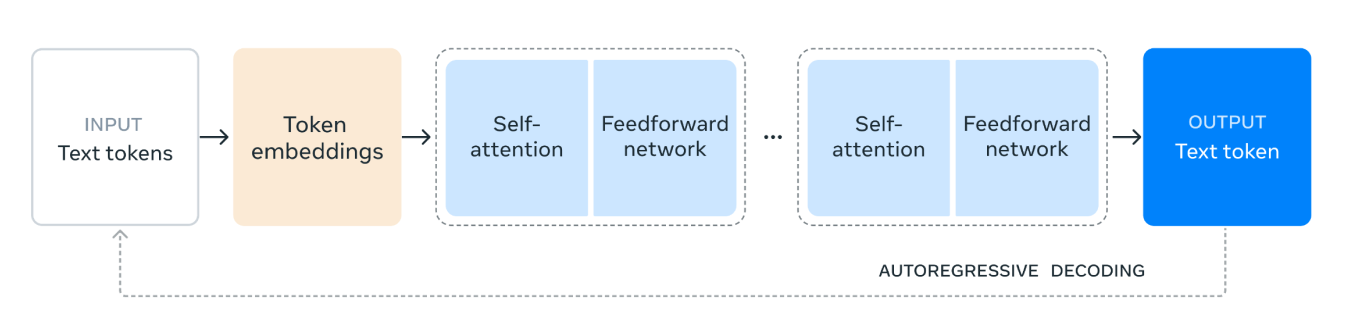
Llama 3.1 模型架构的工作原理如下:
1. 输入文本 Token:该过程从输入开始,输入由文本 token 组成。这些 token 是文本的单个单元,例如模型将处理的单词或子词。
2. Token Embeddings(词嵌入): 然后,文本 tokens 被转换为 token embeddings(词嵌入)。Embeddings 是 tokens 的密集向量表示,可捕获其语义意义以及文本中的关系。 这种转换至关重要,因为它允许模型处理数值数据。
3. Self-Attention Mechanism(自注意力机制): 自注意力允许模型在编码每个 token 时权衡输入序列中不同 token 的重要性。 这种机制有助于模型理解 token 之间的上下文和关系,而不管它们在序列中的位置如何。 在自注意力机制中,输入序列中的每个 token 都表示为一个数字向量。 这些向量用于创建三种不同类型的表示:queries(查询)、keys(键)和 values(值)。
模型通过比较查询向量和键向量来计算每个 token 应该给予其他 token 多少注意力。 这种比较会产生分数,表明每个 token 相对于其他 token 的相关性。
4.前馈网络:在自我关注过程之后,数据会经过一个前馈网络。该网络是一个全连接的神经网络,可对数据进行非线性转换,帮助模型识别和学习复杂的模式。
5. Repeated Layers(重复层): 自注意力和前馈网络层被多次堆叠。 这种重复应用允许模型捕获数据中更复杂的依赖关系和模式。
6. Output Text Token(输出文本 Token): 最后,处理后的数据用于生成输出文本 token。 此 token 是模型根据输入上下文对序列中下一个单词或子词的预测。
基准测试表明,Llama 3.1不仅能与这些最先进的模型相媲美,而且在某些任务中还能超越它们,展现出其卓越的性能。
Llama 3.1 模型已经在超过 150 个基准数据集上进行了广泛的评估,并与其他领先的大型语言模型进行了严格的比较。 Llama 3.1 405B 模型被认为是新发布系列中最强大的模型,已经与 OpenAI 的 GPT-4 和 Claude 3.5 Sonnet 等行业巨头进行了基准测试。 这些比较的结果表明,Llama 3.1 展现出了竞争优势,展示了其在各种任务中的卓越性能和能力。
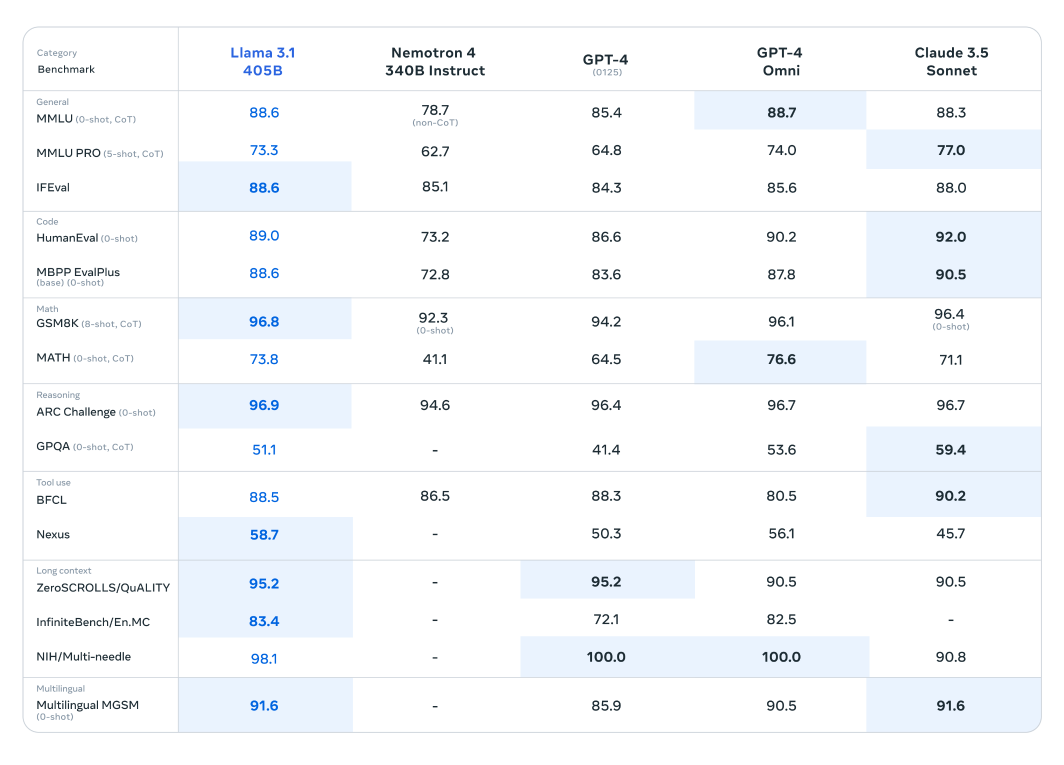
该模型令人印象深刻的参数数量和先进的架构使其在复杂的理解和文本生成方面表现出色,通常在特定基准测试中超越其竞争对手。这些评估突出了 Llama 3.1 在大型语言模型领域树立新标准的潜力,为研究人员和开发人员提供了用于各种应用的强大工具。
与同类产品相比,更小、更轻量级的Llama模型也表现出卓越的性能。Llama 3.1 70B模型已经过与更大的模型(如Mistral 8x22B和GPT-3.5 Turbo)的评估。例如,Llama 3.1 70B模型在诸如ARC Challenge数据集之类的推理数据集和诸如HumanEval数据集之类的编码数据集中始终表现出卓越的性能。这些结果突出了Llama 3.1系列在不同模型尺寸上的多功能性和稳健性,使其成为各种应用的宝贵工具。
此外,Llama 3.1 8B 模型已经与类似规模的模型进行了基准测试,包括 Gemma 2 9B 和 Mistral 7B。这些比较表明,Llama 3.1 8B 模型在各种基准数据集上优于其竞争对手,例如用于推理的 GPQA 数据集和用于编码的 MBPP EvalPlus,展示了其效率和能力,尽管其参数数量较小。

Meta 已经使新模型能够以各种实用和有益的方式应用于用户:
用户现在可以微调最新的 Llama 3.1 模型,以适应特定的使用场景。此过程包括在模型先前未接触过的新外部数据上进行训练,从而提高其针对目标应用程序的性能和适应性。通过使模型能够更好地理解和生成与特定领域或任务相关的内容,微调为模型提供了显著的优势。
Llama 3.1 模型现在可以无缝集成到检索增强生成 (RAG) 系统中。这种集成使模型能够动态地利用外部数据源,从而增强其提供准确且与上下文相关的响应的能力。通过从大型数据集中检索信息并将其整合到生成过程中,Llama 3.1 显着提高了其在知识密集型任务中的性能,为用户提供更精确和更明智的输出。
您还可以利用拥有 4050 亿参数的模型来生成高质量的合成数据,从而提高特定用例的专用模型的性能。这种方法利用 Llama 3.1 的广泛功能来生成有针对性和相关性的数据,从而提高定制 AI 应用程序的准确性和效率。
Llama 3.1 的发布代表了大型语言模型领域的一个重大飞跃,展示了 Meta 对推进 AI 技术的承诺。
Llama 3.1 凭借其庞大的参数数量、在多样化数据集上的广泛训练以及对稳健和稳定训练过程的关注,为自然语言处理的性能和能力树立了新的基准。无论是在文本生成、摘要还是复杂的对话任务中,Llama 3.1 都展现出优于其他领先模型的竞争优势。该模型不仅突破了当今人工智能可以实现的界限,而且还为人工智能不断发展的未来创新奠定了基础。
在Ultralytics,我们致力于推动人工智能技术的发展。要探索我们最前沿的人工智能解决方案,了解我们的最新创新,请访问我们的 GitHub 存储库。在 Discord上加入我们充满活力的社区,了解我们如何为 自动驾驶汽车和 制造业等行业带来变革!🚀


