



Explore the history, achievements, challenges, and future directions of vision models.

Explore the history, achievements, challenges, and future directions of vision models.
Imagine walking into a store where a camera identifies your face, analyzes your mood, and suggests products tailored to your preferences—all in real time. This is not science fiction but a reality enabled by modern vision models. According to a report by Fortune Business Insight, the global computer vision market size was valued at USD 20.31 billion in 2023 and is projected to grow from USD 25.41 billion in 2024 to USD 175.72 billion by 2032, reflecting the rapid advancements and increasing adoption of this technology across various industries.
The field of computer vision enables computers to detect, identify, and analyze objects within images. Similar to other AI related fields, computer vision has experienced rapid evolution over the past few decades, achieving remarkable advancements.
The history of computer vision is extensive. In its early years, computer vision models were capable of detecting simple shapes and edges, often limited to basic tasks like recognizing geometric patterns or differentiating between light and dark areas. However, today’s models can perform complex tasks such as real-time object detection, facial recognition, and even interpreting emotions from facial expressions with exceptional accuracy and efficiency. This dramatic progression highlights the incredible strides made in computational power, algorithmic sophistication, and the availability of vast amounts of data for training.
In this article, we will explore the key milestones in the evolution of computer vision. We will journey through its early beginnings, delve into the transformative impact of Convolutional Neural Networks (CNNs), and examine the significant advancements that followed.
As with other AI fields, the early development of computer vision began with foundational research and theoretical work. A significant milestone was Lawrence G. Roberts' pioneering work on 3D object recognition, documented in his thesis "Machine Perception of Three-Dimensional Solids" in the early 1960s. His contributions laid the groundwork for future advancements in the field.
Early computer vision research focused on image processing techniques, such as edge detection and feature extraction. Algorithms like the Sobel operator, developed in the late 1960s, were among the first to detect edges by computing the gradient of image intensity.

Techniques like the Sobel and Canny edge detectors played a crucial role in identifying boundaries within images, which are essential for recognizing objects and understanding scenes.
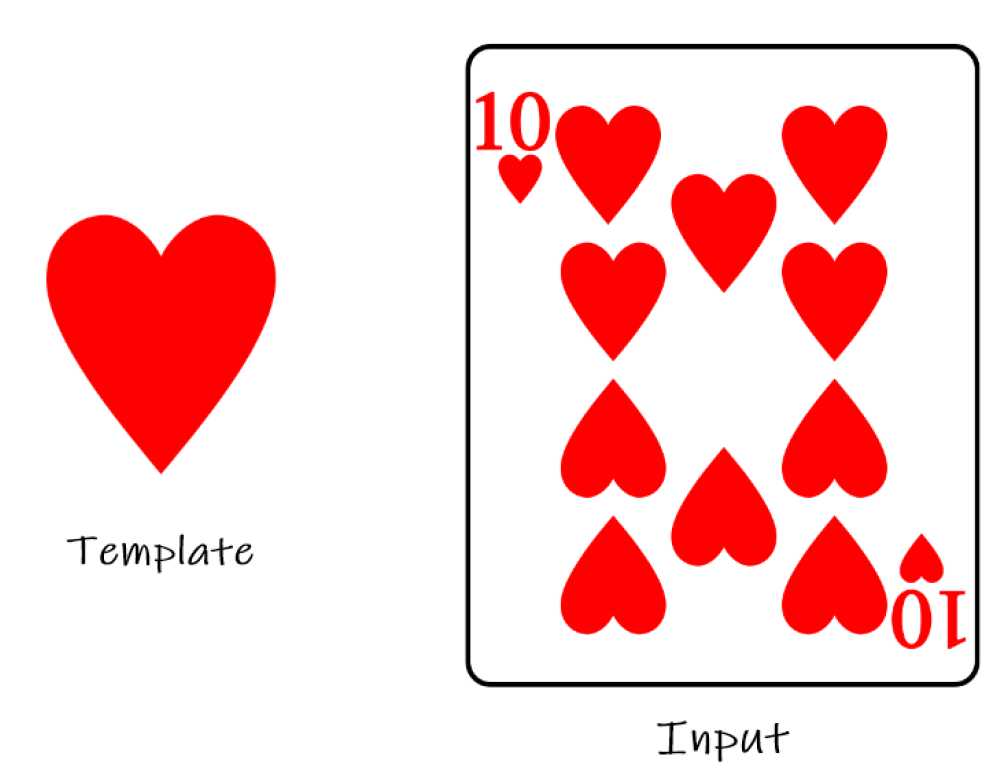
In the 1970s, pattern recognition emerged as a key area of computer vision. Researchers developed methods for recognizing shapes, textures, and objects in images, which paved the way for more complex vision tasks.

One of the early methods for pattern recognition involved template matching, where an image is compared to a set of templates to find the best match. This approach was limited by its sensitivity to variations in scale, rotation, and noise.
Early computer vision systems were constrained by the limited computational power of the time. Computers in the 1960s and 1970s were bulky, expensive, and had limited processing capabilities.
Deep learning and Convolutional Neural Networks (CNNs) marked a pivotal moment in the field of computer vision. These advancements have dramatically transformed how computers interpret and analyze visual data, enabling a wide range of applications that were previously thought impossible.
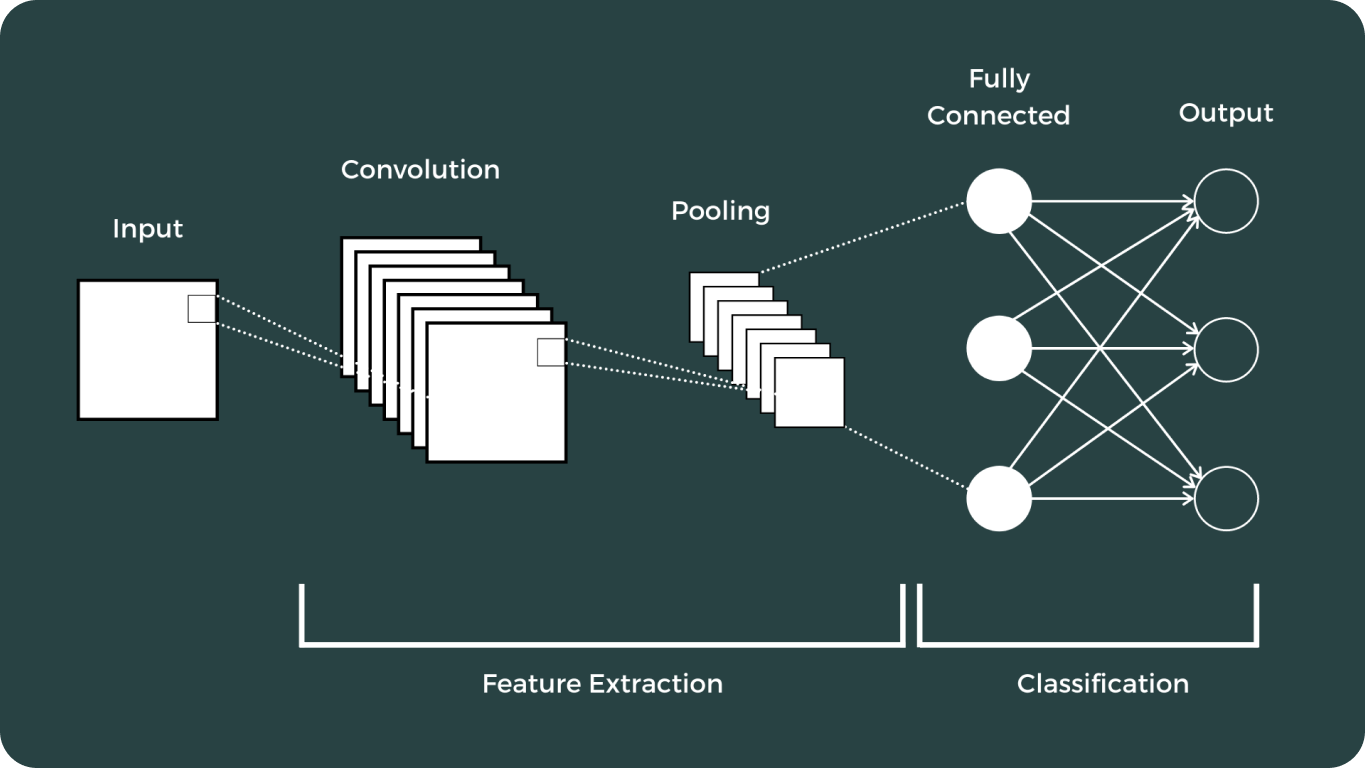
The journey of vision models has been extensive, featuring some of the most notable ones:
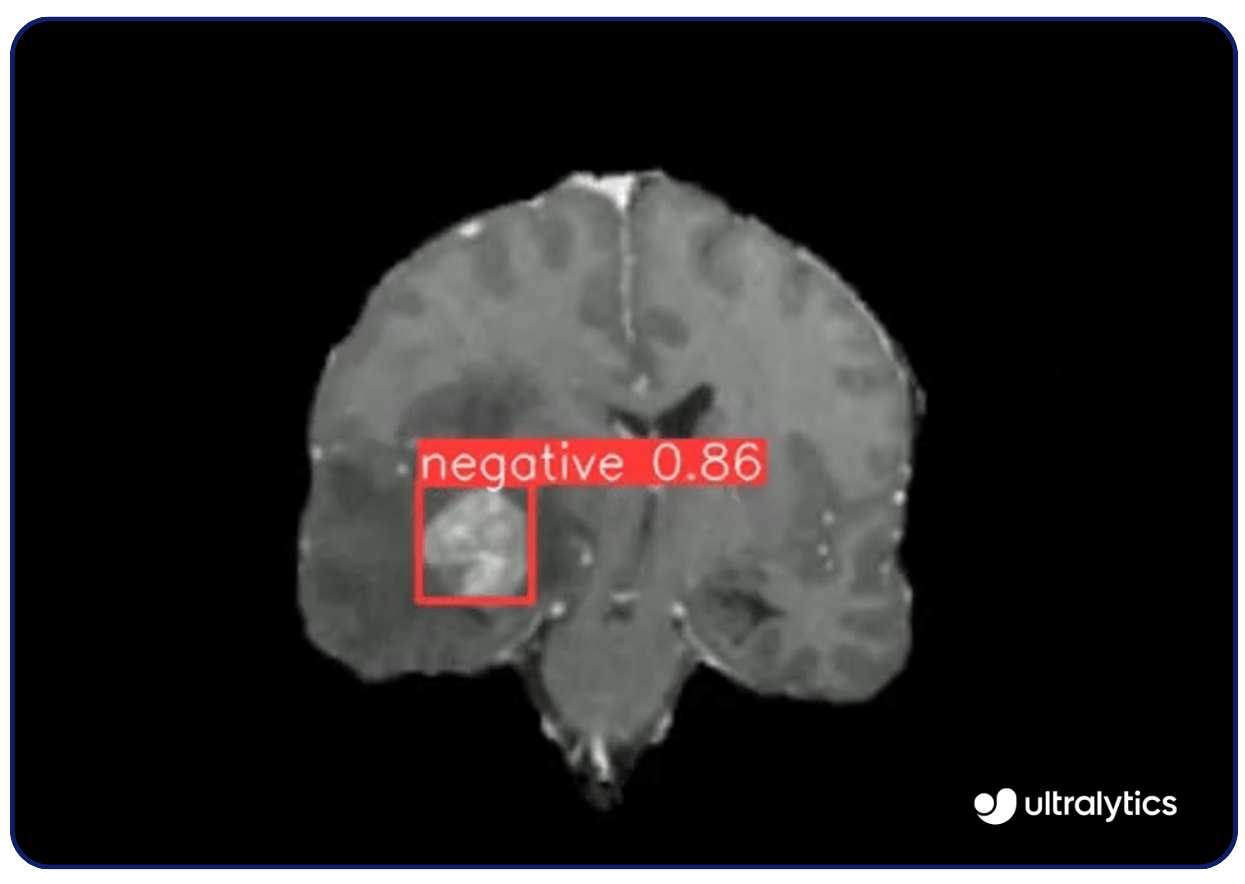
The uses of computer vision are numerous. For instance, vision models like Ultralytics YOLOv8 are utilized in medical imaging to detect diseases such as cancer and diabetic retinopathy. They analyze X-rays, MRIs, and CT scans with high precision, identifying abnormalities early. This early detection capability allows for timely interventions and improved patient outcomes.
Computer vision models help monitor and protect endangered species by analyzing images and videos from wildlife habitats. They identify and track animal behavior, providing data on its population and movements. This technology informs conservation strategies and policy decisions to protect species like tigers and elephants.
With the help of vision AI, other environmental threats such as wildfires and deforestation can be monitored, ensuring fast response times from local authorities.

Even though they have already performed significant achievements, due to their extreme complexity and the demanding nature of their development, vision models face numerous challenges that require ongoing research and future advancements.
Vision models, especially deep learning ones, are often seen as "black boxes" with limited transparency. This is due to such models being incredibly complex. The lack of interpretability hinders trust and accountability, especially in critical applications like healthcare for example.
Training and deploying state-of-the-art AI models demands significant computational resources. This is particularly true for vision models, which often require processing large amounts of image and video data. High-definition images and videos, being among the most data-intensive training inputs, add to the computational burden. For instance, a single HD image can occupy several megabytes of storage, making the training process resource-intensive and time-consuming.
This necessitates powerful hardware and optimized computer vision algorithms to handle the extensive data and complex computations involved in developing effective vision models. Research on more efficient architectures, model compression, and hardware accelerators like GPUs and TPUs are key areas that will advance the future of vision models.
These improvements aim to reduce computational demands and increase processing efficiency. Furthermore, leveraging advanced pre-trained models like YOLOv8 can significantly reduce the need for extensive training, streamlining the development process and enhancing efficiency.
Nowadays, the applications of vision models are widespread, ranging from healthcare, such as tumor detection, to everyday uses like traffic monitoring. These advanced models have brought innovation to countless industries by providing enhanced accuracy, efficiency, and capabilities that were previously unimaginable.
As technology continues to advance, the potential for vision models to innovate and improve various aspects of life and industry remains boundless. This ongoing evolution underscores the importance of continued research and development in the field of computer vision.
Curious about the future of vision AI? For more information on the latest advancements, explore the Ultralytics Docs, and check out their projects on the Ultralytics GitHub and YOLOv8 GitHub. Additionally, for insights into AI applications across various industries, the solutions pages on Self-Driving Cars and Manufacturing offer particularly useful information.


