



Entdecken Sie die Geschichte, Errungenschaften, Herausforderungen und zukünftigen Richtungen von Vision-Modellen.

Entdecken Sie die Geschichte, Errungenschaften, Herausforderungen und zukünftigen Richtungen von Vision-Modellen.
Stellen Sie sich vor, Sie betreten ein Geschäft, in dem eine Kamera Ihr Gesicht identifiziert, Ihre Stimmung analysiert und Ihnen Produkte vorschlägt, die auf Ihre Vorlieben zugeschnitten sind – alles in Echtzeit. Dies ist keine Science-Fiction, sondern eine Realität, die durch moderne Vision-Modelle ermöglicht wird. Laut einem Bericht von Fortune Business Insight wurde die globale Marktgröße für Computer Vision im Jahr 2023 auf 20,31 Milliarden USD geschätzt und soll von 25,41 Milliarden USD im Jahr 2024 auf 175,72 Milliarden USD im Jahr 2032 wachsen, was die raschen Fortschritte und die zunehmende Verbreitung dieser Technologie in verschiedenen Branchen widerspiegelt.
Der Bereich der Computer Vision ermöglicht es Computern, Objekte in Bildern detect, zu identifizieren und zu analysieren. Ähnlich wie andere Bereiche der künstlichen Intelligenz hat sich auch die Computer Vision in den letzten Jahrzehnten rasant entwickelt und bemerkenswerte Fortschritte erzielt.
Die Geschichte der Computer Vision ist umfangreich. In ihren frühen Jahren waren Computer-Vision-Modelle in der Lage, einfache Formen und Kanten zu erkennen, oft beschränkt auf grundlegende Aufgaben wie das Erkennen geometrischer Muster oder das Unterscheiden zwischen hellen und dunklen Bereichen. Die heutigen Modelle können jedoch komplexe Aufgaben wie Echtzeit-Objekterkennung, Gesichtserkennung und sogar die Interpretation von Emotionen aus Gesichtsausdrücken mit außergewöhnlicher Genauigkeit und Effizienz ausführen. Dieser dramatische Fortschritt unterstreicht die unglaublichen Fortschritte in Bezug auf Rechenleistung, algorithmische Raffinesse und die Verfügbarkeit riesiger Datenmengen für das Training.
In diesem Artikel werden wir die wichtigsten Meilensteine in der Entwicklung der Computer Vision untersuchen. Wir werden ihre frühen Anfänge beleuchten, die transformative Wirkung von Convolutional Neural Networks (CNNs) untersuchen und die bedeutenden Fortschritte analysieren, die folgten.
Wie in anderen KI-Bereichen begann die frühe Entwicklung der Computer Vision mit grundlegender Forschung und theoretischer Arbeit. Ein bedeutender Meilenstein war Lawrence G. Roberts' bahnbrechende Arbeit zur 3D-Objekterkennung, die in seiner Dissertation "Machine Perception of Three-Dimensional Solids" in den frühen 1960er Jahren dokumentiert wurde. Seine Beiträge legten den Grundstein für zukünftige Fortschritte in diesem Bereich.
Die frühe Forschung im Bereich der Computer Vision konzentrierte sich auf Bildverarbeitungstechniken wie Kantenerkennung und Merkmalsextraktion. Algorithmen wie der Sobel-Operator, der in den späten 1960er Jahren entwickelt wurde, gehörten zu den ersten, die Kanten durch Berechnung des Gradienten der Bildintensität detect .

Techniken wie die Sobel- und Canny-Kantendetektoren spielten eine entscheidende Rolle bei der Identifizierung von Grenzen innerhalb von Bildern, die für die Erkennung von Objekten und das Verständnis von Szenen unerlässlich sind.
In den 1970er Jahren entwickelte sich die Mustererkennung zu einem wichtigen Bereich der Computer Vision. Forscher entwickelten Methoden zur Erkennung von Formen, Texturen und Objekten in Bildern, die den Weg für komplexere Bildverarbeitungsaufgaben ebneten.

Eine der frühen Methoden zur Mustererkennung war der Template-Matching-Ansatz, bei dem ein Bild mit einer Reihe von Templates verglichen wird, um die beste Übereinstimmung zu finden. Dieser Ansatz war jedoch durch seine Empfindlichkeit gegenüber Variationen in Bezug auf Skalierung, Rotation und Rauschen begrenzt.
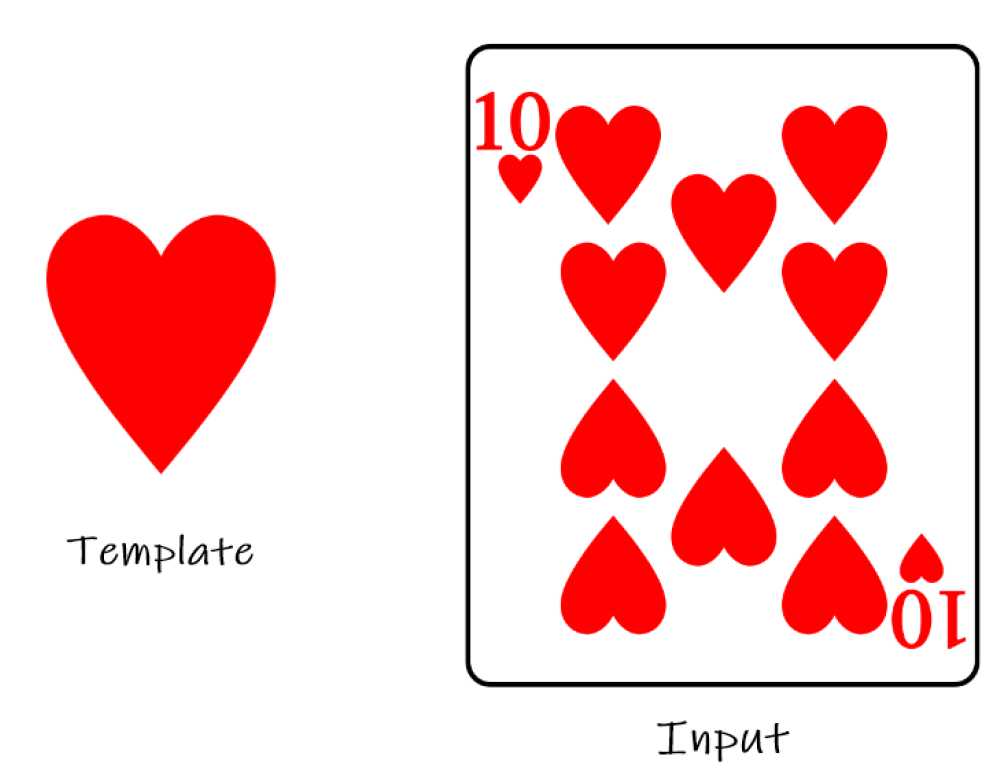
Frühe Computer-Vision-Systeme waren durch die begrenzte Rechenleistung der damaligen Zeit eingeschränkt. Computer in den 1960er und 1970er Jahren waren sperrig, teuer und hatten nur begrenzte Verarbeitungskapazitäten.
Deep Learning und Convolutional Neural Networks (CNNs) markierten einen Wendepunkt im Bereich der Computer Vision. Diese Fortschritte haben die Art und Weise, wie Computer visuelle Daten interpretieren und analysieren, dramatisch verändert und eine breite Palette von Anwendungen ermöglicht, die zuvor für unmöglich gehalten wurden.
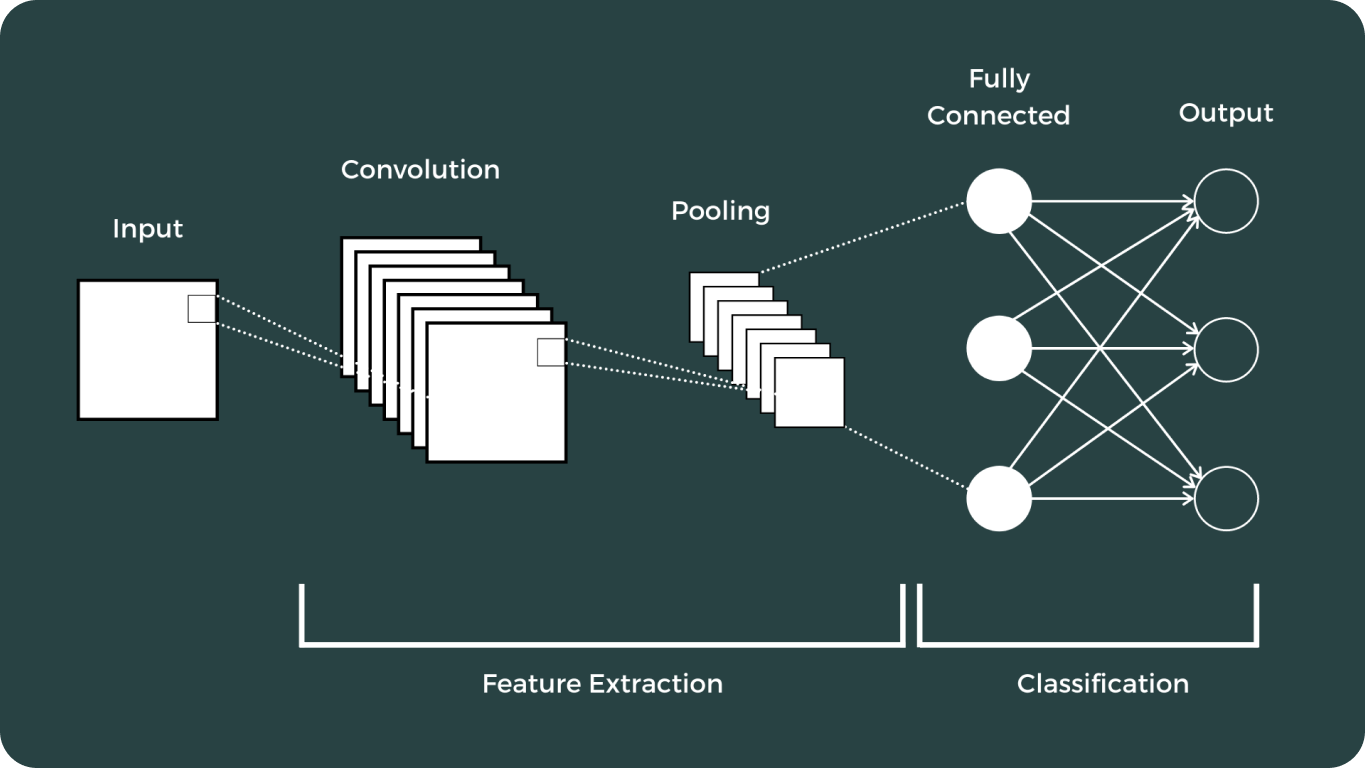
Die Entwicklung der Bilderkennungsmodelle war umfangreich und hat einige der bemerkenswertesten Modelle hervorgebracht:
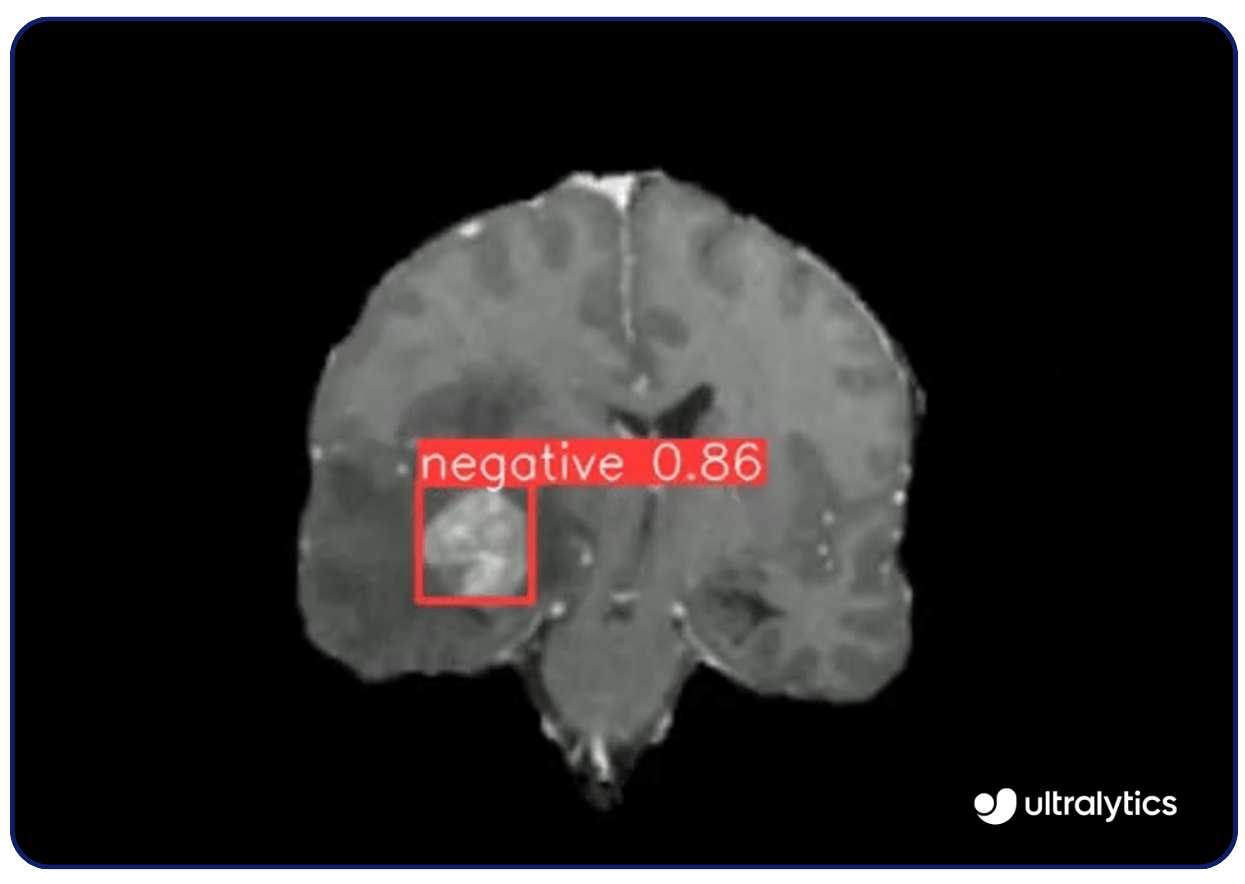
DieEinsatzmöglichkeiten von Computer Vision sind vielfältig. Zum Beispiel können Bildverarbeitungsmodelle wie Ultralytics YOLOv8 werden in der medizinischen Bildgebung eingesetzt, um Krankheiten wie Krebs und diabetische Retinopathie detect . Sie analysieren Röntgenstrahlen, MRTs und CT-Scans mit hoher Präzision und erkennen Anomalien frühzeitig. Diese Fähigkeit zur Früherkennung ermöglicht rechtzeitige Eingriffe und bessere Ergebnisse für die Patienten.
Computer-Vision-Modelle helfen bei der Überwachung und dem Schutz gefährdeter Arten, indem sie Bilder und Videos von Wildtierhabitaten analysieren. Sie identifizieren und track das Verhalten der Tiere und liefern Daten über ihren Bestand und ihre Bewegungen. Diese Technologie liefert Informationen für Erhaltungsstrategien und politische Entscheidungen zum Schutz von Arten wie Tigern und Elefanten.
Mithilfe von Vision AI können andere Umweltbedrohungen wie Waldbrände und Entwaldung überwacht werden, wodurch schnelle Reaktionszeiten der lokalen Behörden gewährleistet werden.

Obwohl sie bereits bedeutende Erfolge erzielt haben, stehen Bilderkennungsmodelle aufgrund ihrer extremen Komplexität und der anspruchsvollen Art ihrer Entwicklung vor zahlreichen Herausforderungen, die fortlaufende Forschung und zukünftige Fortschritte erfordern.
Bilderkennungsmodelle, insbesondere Deep-Learning-Modelle, werden oft als "Black Boxes" mit begrenzter Transparenz angesehen. Dies liegt daran, dass solche Modelle unglaublich komplex sind. Der Mangel an Interpretierbarkeit beeinträchtigt das Vertrauen und die Verantwortlichkeit, insbesondere in kritischen Anwendungen wie beispielsweise dem Gesundheitswesen.
Das Trainieren und Bereitstellen modernster KI-Modelle erfordert erhebliche Rechenressourcen. Dies gilt insbesondere für Bilderkennungsmodelle, die oft große Mengen an Bild- und Videodaten verarbeiten müssen. Hochauflösende Bilder und Videos, die zu den datenintensivsten Trainingsinputs gehören, erhöhen die Rechenlast zusätzlich. So kann beispielsweise ein einzelnes HD-Bild mehrere Megabyte Speicherplatz belegen, was den Trainingsprozess ressourcenintensiv und zeitaufwendig macht.
Dies erfordert leistungsstarke Hardware und optimierte Algorithmen für Computer Vision, um die umfangreichen Daten und komplexen Berechnungen zu bewältigen, die für die Entwicklung effektiver Bilderkennungsmodelle erforderlich sind. Die Forschung an effizienteren Architekturen, Modellkomprimierung und Hardwarebeschleunigern wie GPUs und TPUs sind Schlüsselbereiche, die die Zukunft der Bilderkennungsmodelle voranbringen werden.
Diese Verbesserungen zielen darauf ab, den Rechenaufwand zu verringern und die Verarbeitungseffizienz zu erhöhen. Darüber hinaus werden fortgeschrittene vortrainierte Modelle wie YOLOv8 den Bedarf an umfangreichem Training erheblich reduzieren, was den Entwicklungsprozess rationalisiert und die Effizienz steigert.
Heutzutage sind die Anwendungen von Bilderkennungsmodellen weit verbreitet und reichen vom Gesundheitswesen, wie z. B. der Tumorerkennung, bis hin zu alltäglichen Anwendungen wie der Verkehrsüberwachung. Diese fortschrittlichen Modelle haben unzähligen Branchen Innovationen gebracht, indem sie eine verbesserte Genauigkeit, Effizienz und Fähigkeiten bieten, die bisher unvorstellbar waren.
Da die Technologie immer weiter fortschreitet, bleibt das Potenzial von Bilderkennungsmodellen, verschiedene Aspekte des Lebens und der Industrie zu innovieren und zu verbessern, grenzenlos. Diese fortlaufende Entwicklung unterstreicht die Bedeutung kontinuierlicher Forschung und Entwicklung auf dem Gebiet der Computer Vision.
Sind Sie neugierig auf die Zukunft der künstlichen Intelligenz? Weitere Informationen zu den neuesten Fortschritten finden Sie in den Ultralytics Docs und in den Projekten auf Ultralytics GitHub und YOLOv8 GitHub. Darüber hinaus bieten die Lösungsseiten zu selbstfahrenden Autos und zur Fertigung besonders nützliche Informationen über KI-Anwendungen in verschiedenen Branchen.


