Indem Sie auf „Alle Cookies akzeptieren“ klicken, stimmen Sie der Speicherung von Cookies auf Ihrem Gerät zu, um die Website-Navigation zu verbessern, die Website-Nutzung zu analysieren und unsere Marketingbemühungen zu unterstützen. Mehr Infos
Cookie-Einstellungen
Indem Sie auf „Alle Cookies akzeptieren“ klicken, stimmen Sie der Speicherung von Cookies auf Ihrem Gerät zu, um die Website-Navigation zu verbessern, die Website-Nutzung zu analysieren und unsere Marketingbemühungen zu unterstützen. Mehr Infos
Entdecken Sie die neue Open-Source-Modellfamilie Llama 3.1 von Meta, die den vielseitigen 8B, den Allrounder 70B und das Flaggschiff 405B, ihr bisher größtes und fortschrittlichstes Modell, umfasst.
Am 23. Juli 2024 veröffentlichte Meta die neue Open-Source-Modellfamilie Llama 3.1, bestehend aus dem vielseitigen 8B, dem leistungsstarken 70B und dem Llama 3.1 405B-Modell, wobei letzteres das bisher größte Open-Source-Sprachmodell (LLM) ist.
Sie fragen sich vielleicht, was diese neuen Modelle von ihren Vorgängern unterscheidet. Nun, im Laufe dieses Artikels werden Sie feststellen, dass die Veröffentlichung der Llama 3.1 Modelle einen bedeutenden Meilenstein in der KI-Technologie darstellt. Die neu veröffentlichten Modelle bieten deutliche Verbesserungen in der Verarbeitung natürlicher Sprache; darüber hinaus führen sie neue Funktionen und Erweiterungen ein, die in früheren Versionen nicht vorhanden waren. Diese Veröffentlichung verspricht, die Art und Weise zu verändern, wie wir KI für komplexe Aufgaben nutzen, und bietet ein leistungsstarkes Toolset für Forscher und Entwickler gleichermaßen.
In diesem Artikel werden wir die Llama 3.1-Modellfamilie untersuchen und uns mit ihrer Architektur, den wichtigsten Verbesserungen, den praktischen Anwendungen und einem detaillierten Vergleich ihrer Leistung befassen.
Was ist Llama 3.1?
Metas neuestes Large Language Model, Llama 3.1, macht bedeutende Fortschritte in der KI-Landschaft und kann mit den Fähigkeiten von Spitzenmodellen wie OpenAIs Chat GPT-4o und Anthropic Claude 3.5 Sonnet mithalten.
Auch wenn es sich um ein kleineres Update des vorherigen Llama 3-Modells handeln mag, hat Meta mit einigen wichtigen Verbesserungen an der neuen Modellfamilie noch einen Schritt weiter gemacht und bietet:
Unterstützung von acht Sprachen: English, Deutsch, Französisch, Italienisch, Portugiesisch, Hindi, Spanisch und Thailändisch, wodurch die Reichweite auf ein weltweites Publikum erweitert wird.
128.000 Kontextfenster-Token: Ermöglichen es den Modellen, viel längere Eingaben zu verarbeiten und den Kontext über längere Konversationen oder Dokumente hinweg aufrechtzuerhalten.
Bessere Denkfähigkeiten: Ermöglicht es den Modellen, vielseitiger zu sein und komplexe Aufgaben effektiv zu bewältigen.
Strenge Sicherheit: Es wurden Tests implementiert, um Risiken zu mindern, Verzerrungen zu reduzieren und schädliche Ergebnisse zu verhindern, wodurch ein verantwortungsvoller Umgang mit KI gefördert wird.
Die neue Modellfamilie Llama 3.1 stellt mit ihrem beeindruckenden 405-Milliarden-Parameter-Modell einen großen Fortschritt dar. Diese beträchtliche Anzahl von Parametern stellt einen bedeutenden Sprung in der KI-Entwicklung dar und verbessert die Fähigkeit des Modells, komplexe Texte zu verstehen und zu generieren. Das 405B-Modell umfasst eine Vielzahl von Parametern, wobei sich jeder Parameter auf die weights and biases im neuronalen Netz bezieht, die das Modell während des Trainings erlernt. Dadurch kann das Modell kompliziertere Sprachmuster erfassen, einen neuen Standard für große Sprachmodelle setzen und das zukünftige Potenzial der KI-Technologie aufzeigen. Dieses groß angelegte Modell verbessert nicht nur die Leistung bei einer Vielzahl von Aufgaben, sondern verschiebt auch die Grenzen dessen, was KI in Bezug auf Texterzeugung und -verständnis erreichen kann.
Modellarchitektur
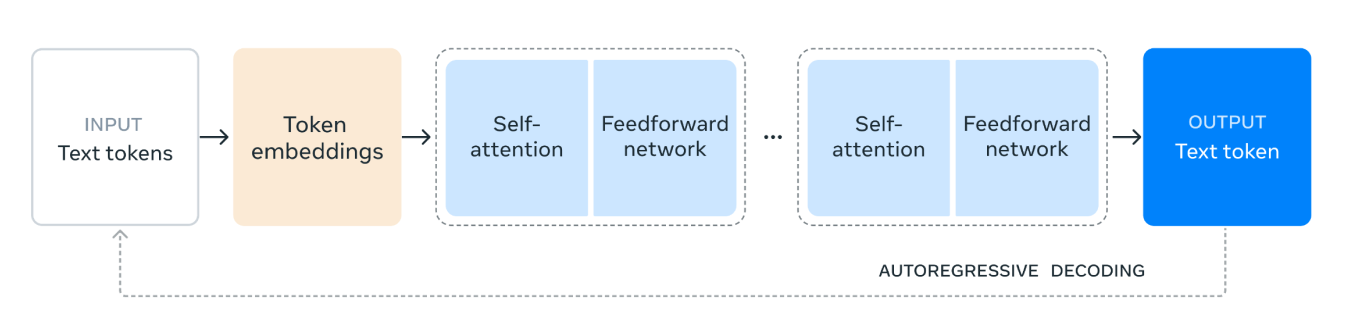
Llama 3.1 nutzt die Decoder-Only-Transformer-Modellarchitektur, einen Eckpfeiler für moderne große Sprachmodelle. Diese Architektur ist bekannt für ihre Effizienz und Effektivität bei der Bewältigung komplexer Sprachaufgaben. Der Einsatz von Transformatoren ermöglicht es Llama 3.1, sich im Verständnis und der Generierung von menschenähnlichem Text hervorzutun, was einen deutlichen Vorteil gegenüber Modellen bietet, die ältere Architekturen wie LSTMs und GRUs verwenden.
Darüber hinaus verwendet die Llama 3.1-Modellfamilie die Mixture of Experts (MoE) Architektur, die die Trainingseffizienz und -stabilität verbessert. Der Verzicht auf die MoE-Architektur gewährleistet einen konsistenteren und zuverlässigeren Trainingsprozess, da MoE manchmal Komplexitäten mit sich bringen kann, die die Modellstabilität und -leistung beeinträchtigen können.
Abb. 1. Ein Diagramm zur Veranschaulichung der Transformer-Modellarchitektur von Llama 3.1.
Die Llama 3.1 Modellarchitektur funktioniert wie folgt:
1. Eingabe-Text-Token: Der Prozess beginnt mit der Eingabe, die aus Text-Token besteht. Diese Token sind einzelne Texteinheiten, wie z. B. Wörter oder Teilwörter, die das Modell verarbeiten wird.
2. Token-Einbettungen: Die Text-Token werden dann in Token-Einbettungen umgewandelt. Einbettungen sind dichte Vektordarstellungen der Token, die ihre semantische Bedeutung und Beziehungen innerhalb des Textes erfassen. Diese Transformation ist entscheidend, da sie es dem Modell ermöglicht, mit numerischen Daten zu arbeiten.
3. Self-Attention-Mechanismus: Self-Attention ermöglicht es dem Modell, die Bedeutung verschiedener Token in der Eingabesequenz bei der Kodierung jedes Tokens zu gewichten. Dieser Mechanismus hilft dem Modell, den Kontext und die Beziehungen zwischen Token zu verstehen, unabhängig von ihrer Position in der Sequenz. Im Self-Attention-Mechanismus wird jedes Token in der Eingabesequenz als ein Vektor von Zahlen dargestellt. Diese Vektoren werden verwendet, um drei verschiedene Arten von Darstellungen zu erstellen: Abfragen, Schlüssel und Werte.
Das Modell berechnet, wie viel Aufmerksamkeit jedes Token anderen Token schenken sollte, indem es die Abfragevektoren mit den Schlüsselvektoren vergleicht. Dieser Vergleich führt zu Bewertungen, die die Relevanz jedes Tokens in Bezug auf andere angeben.
4. Feedforward-Netzwerk: Nach dem Selbstbeobachtungsprozess durchlaufen die Daten ein Feedforward-Netzwerk. Dieses Netz ist ein vollständig verbundenes neuronales Netz, das nichtlineare Transformationen auf die Daten anwendet und dem Modell hilft, komplexe Muster zu erkennen und zu lernen.
5. Wiederholte Schichten: Die Self-Attention- und Feedforward-Netzwerkschichten werden mehrfach gestapelt. Diese wiederholte Anwendung ermöglicht es dem Modell, komplexere Abhängigkeiten und Muster in den Daten zu erfassen.
6. Ausgabe-Text-Token: Schließlich werden die verarbeiteten Daten verwendet, um das Ausgabe-Text-Token zu generieren. Dieses Token ist die Vorhersage des Modells für das nächste Wort oder Teilwort in der Sequenz, basierend auf dem Eingabekontext.
Leistung und Vergleiche der LLama 3.1-Modellfamilie mit anderen Modellen
Benchmark-Tests zeigen, dass Llama 3.1 nicht nur mit diesen hochmodernen Modellen mithalten kann, sondern sie in bestimmten Aufgaben sogar übertrifft und seine überlegene Leistung demonstriert.
Llama 3.1 405B: Hohe Kapazität
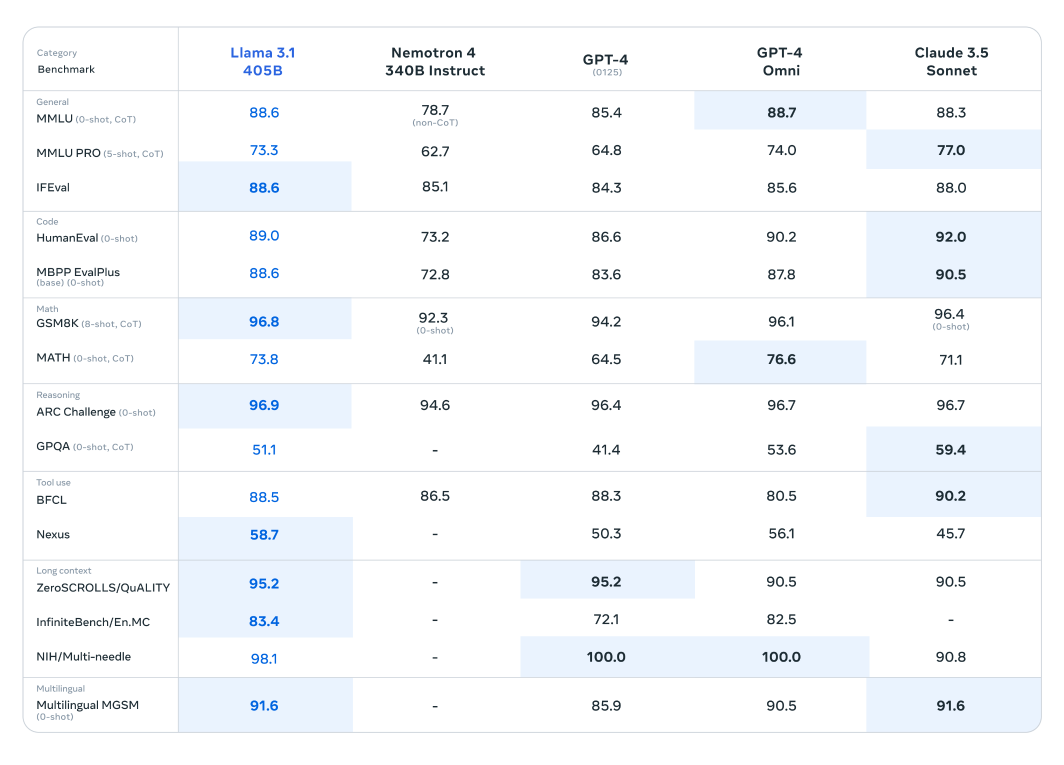
Das Llama 3.1-Modell wurde umfassend anhand von über 150 Benchmark-Datensätzen evaluiert, wobei es rigoros mit anderen führenden Large Language Models verglichen wurde. Das Llama 3.1 405B-Modell, das als das leistungsfähigste der neu veröffentlichten Serie gilt, wurde mit Branchengrößen wie GPT-4 von OpenAI und Claude 3.5 Sonnet verglichen. Die Ergebnisse dieser Vergleiche zeigen, dass Llama 3.1 einen Wettbewerbsvorteil aufweist und seine überlegene Leistung und Fähigkeiten bei verschiedenen Aufgaben unter Beweis stellt.
Abb. 2. Eine Tabelle, die die Leistung des Llama 3.1 405B-Modells mit ähnlichen Modellen vergleicht.
Die beeindruckende Parameteranzahl und die fortschrittliche Architektur dieses Modells ermöglichen es ihm, sich durch komplexes Verständnis und Textgenerierung auszuzeichnen und seine Konkurrenten in bestimmten Benchmarks oft zu übertreffen. Diese Bewertungen unterstreichen das Potenzial von Llama 3.1, neue Standards im Bereich der großen Sprachmodelle zu setzen und Forschern und Entwicklern ein leistungsstarkes Werkzeug für vielfältige Anwendungen zu bieten.
Llama 3.1 70B: Mittelklasse
Die kleineren und leichteren Llama-Modelle zeigen im Vergleich zu ihren Pendants ebenfalls eine bemerkenswerte Leistung. Das Llama 3.1 70B-Modell wurde mit größeren Modellen wie Mistral 8x22B und GPT-3.5 Turbo verglichen. So zeigt beispielsweise das Llama 3.1 70B-Modell in den Reasoning-Datensätzen wie dem ARC Challenge-Datensatz und den Coding-Datensätzen wie den HumanEval-Datensätzen durchweg eine überlegene Leistung. Diese Ergebnisse unterstreichen die Vielseitigkeit und Robustheit der Llama 3.1-Serie über verschiedene Modellgrößen hinweg und machen sie zu einem wertvollen Werkzeug für eine breite Palette von Anwendungen.
Llama 3.1 8B: Leichtgewichtig
Darüber hinaus wurde das Llama 3.1 8B-Modell mit Modellen ähnlicher Größe verglichen, darunter Gemma 2 9B und Mistral 7B. Diese Vergleiche zeigen, dass das Llama 3.1 8B-Modell seine Konkurrenten in verschiedenen Benchmark-Datensätzen in verschiedenen Genres übertrifft, wie z. B. dem GPQA-Datensatz für logisches Denken und dem MBPP EvalPlus für Programmierung, was seine Effizienz und Leistungsfähigkeit trotz seiner geringeren Parameteranzahl unter Beweis stellt.
Abb. 3. Eine Tabelle, die die Leistungen der Modelle Llama 3.1 70B und 8B mit ähnlichen Modellen vergleicht.
Wie können Sie von den Modellen der Llama 3.1-Familie profitieren?
Meta hat es ermöglicht, die neuen Modelle auf vielfältige, praktische und vorteilhafte Weise für die Nutzer anzuwenden:
Feinabstimmung
Benutzer können jetzt die neuesten Llama 3.1-Modelle für spezifische Anwendungsfälle feinabstimmen (fine-tune). Dieser Prozess beinhaltet das Trainieren des Modells mit neuen, externen Daten, denen es zuvor nicht ausgesetzt war, wodurch seine Leistung und Anpassungsfähigkeit für gezielte Anwendungen verbessert wird. Das Fine-Tuning verschafft dem Modell einen erheblichen Vorteil, da es ihm ermöglicht, Inhalte, die für bestimmte Bereiche oder Aufgaben relevant sind, besser zu verstehen und zu generieren.
Integration in ein RAG-System
Llama 3.1 Modelle lassen sich jetzt nahtlos in Retrieval-Augmented Generation (RAG) Systeme integrieren. Diese Integration ermöglicht es dem Modell, externe Datenquellen dynamisch zu nutzen, wodurch seine Fähigkeit verbessert wird, genaue und kontextbezogene Antworten zu geben. Durch das Abrufen von Informationen aus großen Datensätzen und deren Einbeziehung in den Generierungsprozess verbessert Llama 3.1 seine Leistung bei wissensintensiven Aufgaben erheblich und bietet den Benutzern präzisere und fundiertere Ergebnisse.
Generierung synthetischer Daten
Sie können auch das 405-Milliarden-Parameter-Modell verwenden, um qualitativ hochwertige synthetische Daten zu generieren und so die Leistung spezialisierter Modelle für spezifische Anwendungsfälle zu verbessern. Dieser Ansatz nutzt die umfangreichen Fähigkeiten von Llama 3.1, um gezielte und relevante Daten zu erzeugen und so die Genauigkeit und Effizienz maßgeschneiderter KI-Anwendungen zu verbessern.
Die wichtigsten Erkenntnisse
Die Veröffentlichung von Llama 3.1 stellt einen bedeutenden Fortschritt im Bereich der Large Language Models dar und unterstreicht das Engagement von Meta für die Weiterentwicklung der KI-Technologie.
Mit seiner beträchtlichen Parameteranzahl, dem umfangreichen Training auf diversen Datensätzen und dem Fokus auf robuste und stabile Trainingsprozesse setzt Llama 3.1 neue Maßstäbe für Leistung und Fähigkeiten in der Verarbeitung natürlicher Sprache. Ob bei der Textgenerierung, der Zusammenfassung oder komplexen Konversationsaufgaben, Llama 3.1 demonstriert einen Wettbewerbsvorteil gegenüber anderen führenden Modellen. Dieses Modell verschiebt nicht nur die Grenzen dessen, was KI heute leisten kann, sondern bereitet auch den Weg für zukünftige Innovationen in der sich ständig weiterentwickelnden Landschaft der künstlichen Intelligenz.
Wir bei Ultralytics haben es uns zur Aufgabe gemacht, die Grenzen der KI-Technologie zu erweitern. Um unsere innovativen KI-Lösungen zu erkunden und über unsere neuesten Innovationen auf dem Laufenden zu bleiben, besuchen Sie unser GitHub-Repository. Treten Sie unserer lebhaften Community auf Discord bei und sehen Sie, wie wir Branchen wie selbstfahrende Autos und die Fertigung revolutionieren! 🚀