Indem Sie auf „Alle Cookies akzeptieren“ klicken, stimmen Sie der Speicherung von Cookies auf Ihrem Gerät zu, um die Website-Navigation zu verbessern, die Website-Nutzung zu analysieren und unsere Marketingbemühungen zu unterstützen. Mehr Infos
Cookie-Einstellungen
Indem Sie auf „Alle Cookies akzeptieren“ klicken, stimmen Sie der Speicherung von Cookies auf Ihrem Gerät zu, um die Website-Navigation zu verbessern, die Website-Nutzung zu analysieren und unsere Marketingbemühungen zu unterstützen. Mehr Infos
Werfen Sie mit uns einen Blick zurück auf die Entwicklung der Objekterkennung. Wir werden uns darauf konzentrieren, wie sich YOLO (You Only Look Once) in den letzten Jahren weiterentwickelt haben.
Computer Vision ist ein Teilbereich der künstlichen Intelligenz (KI), der sich darauf konzentriert, Maschinen das Sehen und Verstehen von Bildern und Videos beizubringen, ähnlich wie Menschen die reale Welt wahrnehmen. Während das Erkennen von Objekten oder das Identifizieren von Aktionen für Menschen selbstverständlich ist, erfordern diese Aufgaben spezifische und spezialisierte Computer-Vision-Techniken, wenn es um Maschinen geht. Eine wichtige Aufgabe in der Computer Vision ist beispielsweise die Objekterkennung, bei der Objekte innerhalb von Bildern oder Videos identifiziert und lokalisiert werden.
Seit den 1960er Jahren arbeiten Forscher daran, die detect Objekten durch Computer zu verbessern. Bei frühen Methoden wie dem Vorlagenabgleich wurde eine vordefinierte Vorlage über ein Bild gezogen, um Übereinstimmungen zu finden. Diese Ansätze waren zwar innovativ, hatten aber mit Veränderungen der Objektgröße, -ausrichtung und -beleuchtung zu kämpfen. Heute haben wir fortgeschrittene Modelle wie Ultralytics YOLO11 die selbst kleine und teilweise verdeckte Objekte, so genannte verdeckte Objekte, mit beeindruckender Genauigkeit detect können.
Da sich die Computer Vision ständig weiterentwickelt, ist es wichtig, einen Rückblick auf die Entwicklung dieser Technologien zu werfen. In diesem Artikel werden wir die Entwicklung der Objekterkennung untersuchen und die Transformation der YOLO (You Only Look Once) beleuchten. Fangen wir an!
Die Ursprünge der Computer Vision
Bevor wir uns mit der Objekterkennung befassen, sollten wir einen Blick auf die Anfänge der Computer Vision werfen. Die Ursprünge des Computerbildes gehen auf die späten 1950er und frühen 1960er Jahre zurück, als Wissenschaftler zu erforschen begannen, wie das Gehirn visuelle Informationen verarbeitet. In Experimenten mit Katzen entdeckten die Forscher David Hubel und Torsten Wiesel, dass das Gehirn auf einfache Muster wie Kanten und Linien reagiert. Dies bildete die Grundlage für die Idee der Merkmalsextraktion - das Konzept, dass visuelle Systeme grundlegende Merkmale in Bildern, wie z. B. Kanten, detect und erkennen, bevor sie zu komplexeren Mustern übergehen.
Abb. 1. Das Verständnis, wie das Gehirn einer Katze auf Lichtbalken reagiert, trug zur Entwicklung der Merkmalsextraktion in der Computer Vision bei.
Etwa zur gleichen Zeit tauchte eine neue Technologie auf, die physische Bilder in digitale Formate umwandeln konnte, was das Interesse daran weckte, wie Maschinen visuelle Informationen verarbeiten könnten. Im Jahr 1966 trieb das Summer Vision Project des Massachusetts Institute of Technology (MIT) die Dinge weiter voran. Obwohl das Projekt nicht vollständig erfolgreich war, zielte es darauf ab, ein System zu schaffen, das den Vordergrund vom Hintergrund in Bildern trennen konnte. Für viele in der Vision AI Community markiert dieses Projekt den offiziellen Beginn von Computer Vision als wissenschaftliches Gebiet.
Das Verständnis der Geschichte der Objekterkennung
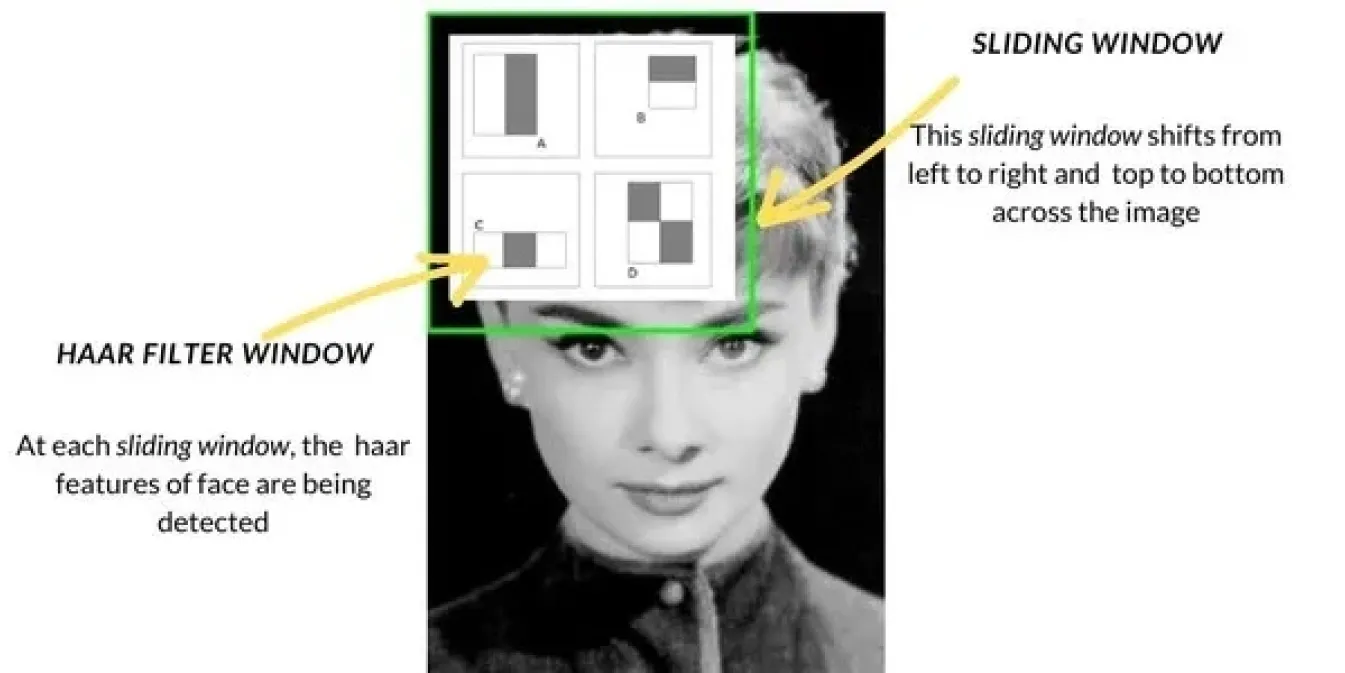
Mit den Fortschritten der Computer Vision in den späten 1990er und frühen 2000er Jahren verlagerten sich die Methoden der Objekterkennung von grundlegenden Techniken wie dem Template Matching zu fortschrittlicheren Ansätzen. Eine beliebte Methode war die Haar-Kaskade, die für Aufgaben wie die Gesichtserkennung weit verbreitet wurde. Bei dieser Methode werden Bilder mit einem gleitenden Fenster gescannt, in jedem Bildabschnitt auf bestimmte Merkmale wie Kanten oder Texturen geprüft und diese Merkmale dann kombiniert, um Objekte wie Gesichter detect . Haar Cascade war viel schneller als frühere Methoden.
Abb. 2. Verwendung von Haar Cascade zur Gesichtserkennung.
Daneben wurden auch Methoden wie Histogram of Oriented Gradients (HOG) und Support Vector Machines (SVMs) eingeführt. HOG verwendete die Sliding-Window-Technik, um zu analysieren, wie sich Licht und Schatten in kleinen Abschnitten eines Bildes veränderten, was half, Objekte anhand ihrer Formen zu identifizieren. SVMs klassifizierten dann diese Merkmale, um die Identität des Objekts zu bestimmen. Diese Methoden verbesserten die Genauigkeit, hatten aber immer noch in realen Umgebungen zu kämpfen und waren langsamer als die heutigen Techniken.
Der Bedarf an Echtzeit-Objekterkennung
In den 2010er Jahren brachte der Aufstieg von Deep Learning und Convolutional Neural Networks (CNNs) eine große Veränderung in der Objekterkennung. CNNs ermöglichten es Computern, automatisch wichtige Merkmale aus großen Mengen von Daten zu lernen, was die Erkennung wesentlich genauer machte.
Diese Modelle waren jedoch langsam, da sie Bilder in mehreren Schritten verarbeiteten, was sie für Echtzeitanwendungen in Bereichen wie selbstfahrenden Autos oder Videoüberwachung unpraktisch machte.
Mit dem Fokus auf die Beschleunigung der Prozesse wurden effizientere Modelle entwickelt. Modelle wie Fast R-CNN und Faster R-CNN halfen, indem sie die Auswahl von Regionen von Interesse verfeinerten und die Anzahl der für die Erkennung erforderlichen Schritte reduzierten. Dies beschleunigte zwar die Objekterkennung, war aber für viele Anwendungen in der realen Welt, die sofortige Ergebnisse benötigten, immer noch nicht schnell genug. Die wachsende Nachfrage nach Echtzeit-Erkennung trieb die Entwicklung noch schnellerer und effizienterer Lösungen voran, die sowohl Geschwindigkeit als auch Genauigkeit in Einklang bringen konnten.
Abb. 3. Vergleich der Geschwindigkeiten von R-CNN, Fast R-CNN und Faster R-CNN.
YOLO (You Only Look Once): Ein wichtiger Meilenstein
YOLO ist ein Objekterkennungsmodell, das die Computervision neu definiert, indem es die Erkennung mehrerer Objekte in Bildern und Videos in Echtzeit ermöglicht, was es von früheren Erkennungsmethoden unterscheidet. Anstatt jedes erkannte Objekt einzeln zu analysieren, behandelt die Architektur vonYOLO die Objekterkennung als eine einzige Aufgabe und sagt sowohl den Ort als auch die Klasse der Objekte in einem Durchgang mithilfe von CNNs voraus.
Das Modell funktioniert, indem es ein Bild in ein Raster unterteilt, wobei jeder Teil für die Erkennung von Objekten in seinem jeweiligen Bereich verantwortlich ist. Es macht mehrere Vorhersagen für jeden Abschnitt und filtert die weniger zuverlässigen Ergebnisse heraus, wobei nur die genauen Ergebnisse beibehalten werden.
Abbildung 4. Ein Überblick über die Funktionsweise YOLO .
Mit der Einführung von YOLO in Computer-Vision-Anwendungen wurde die Objekterkennung viel schneller und effizienter als bei früheren Modellen. Aufgrund seiner Geschwindigkeit und Genauigkeit wurde YOLO schnell zu einer beliebten Wahl für Echtzeitlösungen in Branchen wie Fertigung, Gesundheitswesen und Robotik.
Ein weiterer wichtiger Punkt ist, dass YOLO als Open-Source-Programm von Entwicklern und Forschern kontinuierlich verbessert werden konnte, was zu noch fortschrittlicheren Versionen führte.
Der Weg von YOLO zu YOLO11
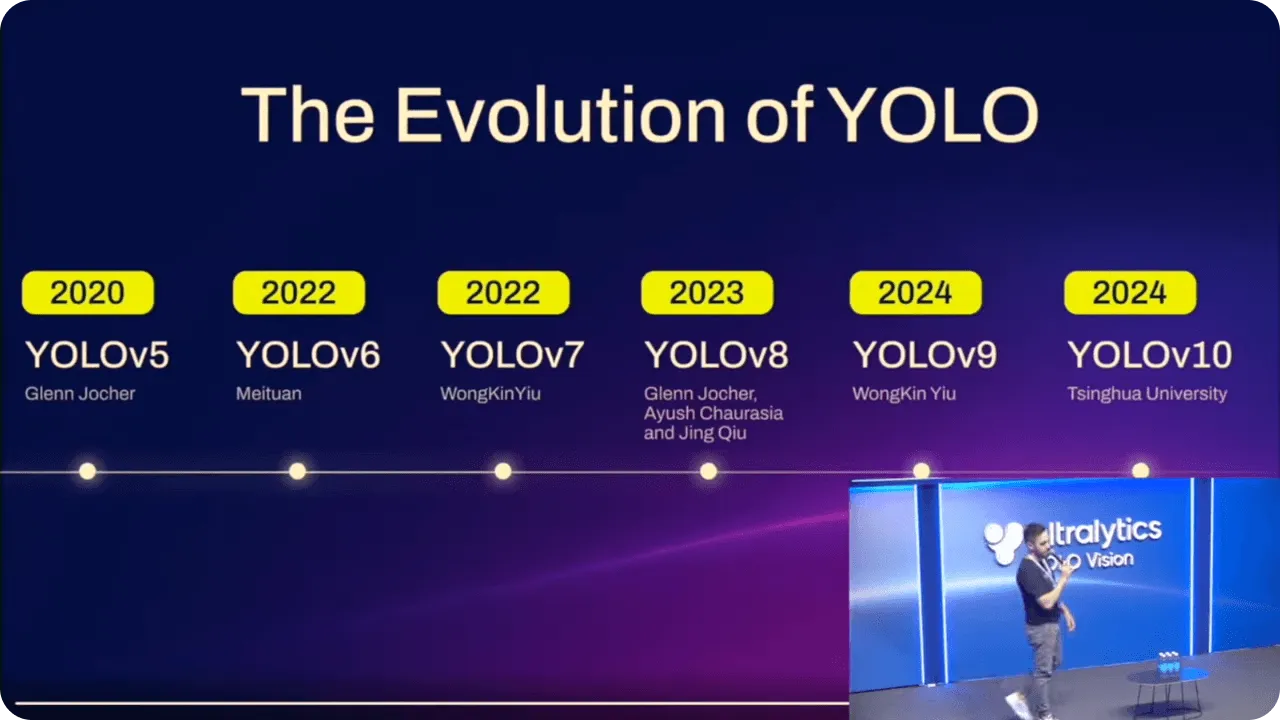
Die YOLO wurden im Laufe der Zeit immer weiter verbessert, wobei jede Version auf den Fortschritten der anderen aufbaut. Neben der besseren Leistung haben diese Verbesserungen dazu geführt, dass die Modelle für Personen mit unterschiedlicher technischer Erfahrung einfacher zu bedienen sind.
Zum Beispiel, wenn Ultralytics YOLOv5 eingeführt wurde, wurde die Bereitstellung von Modellen einfacher mit PyTorchvereinfacht, so dass ein breiterer Benutzerkreis mit fortschrittlicher KI arbeiten kann. Es brachte Genauigkeit und Benutzerfreundlichkeit zusammen und gab mehr Menschen die Möglichkeit, Objekterkennung zu implementieren, ohne dass sie Kodierungsexperten sein mussten.
Abb. 5. Die Entwicklung der YOLO .
Ultralytics YOLOv8 setzte diesen Fortschritt fort, indem es Unterstützung für Aufgaben wie die Segmentierung von Instanzen hinzufügte und die Modelle noch flexibler machte. Es wurde einfacher, YOLO sowohl für einfache als auch für komplexere Anwendungen zu verwenden, was es für eine Reihe von Szenarien nützlich macht.
Mit dem neuesten Modell, Ultralytics YOLO11wurden weitere Optimierungen vorgenommen. Durch die Verringerung der Anzahl der Parameter bei gleichzeitiger Verbesserung der Genauigkeit ist es jetzt effizienter für Echtzeitaufgaben. Egal, ob Sie ein erfahrener Entwickler oder ein Neuling im Bereich der KI sind, YOLO11 bietet einen fortschrittlichen Ansatz zur Objekterkennung, der leicht zugänglich ist.
YOLO11 kennenlernen: Neue Funktionen und Verbesserungen
YOLO11, das auf der jährlichen Hybrid-Veranstaltung Ultralytics, YOLO Vision 2024 (YV24), vorgestellt wurde, unterstützt dieselben Computer-Vision-Aufgaben wie YOLOv8, z. B. Objekterkennung, Instanzsegmentierung, Bildklassifizierung und Posenschätzung. Anwender können also problemlos zu diesem neuen Modell wechseln, ohne ihre Arbeitsabläufe anpassen zu müssen. Darüber hinaus macht die verbesserte Architektur von YOLO11die Vorhersagen noch präziser. Tatsächlich erreicht YOLO11m eine höhere durchschnittliche GenauigkeitmAP) auf dem COCO mit 22 % weniger Parametern als YOLOv8m.
YOLO11 ist außerdem so konzipiert, dass es auf einer Reihe von Plattformen effizient läuft, von Smartphones und anderen Edge-Geräten bis hin zu leistungsfähigeren Cloud-Systemen. Diese Flexibilität gewährleistet eine reibungslose Leistung über verschiedene Hardware-Konfigurationen für Echtzeitanwendungen. Darüber hinaus ist YOLO11 schneller und effizienter, wodurch die Rechenkosten gesenkt und die Inferenzzeiten verkürzt werden. Ganz gleich, ob Sie das Ultralytics Python oder den codefreien Ultralytics HUB verwenden, YOLO11 lässt sich problemlos in Ihre bestehenden Arbeitsabläufe integrieren.
Die Zukunft der YOLO und der Objekterkennung
Die Auswirkungen der fortschrittlichen Objekterkennung auf Echtzeitanwendungen und KI sind bereits branchenübergreifend zu spüren. Da Branchen wie Öl und Gas, das Gesundheitswesen und der Einzelhandel zunehmend auf KI setzen, steigt die Nachfrage nach schneller und präziser Objekterkennung weiter an. YOLO11 zielt darauf ab, diese Nachfrage zu befriedigen, indem es eine leistungsstarke Erkennung selbst auf Geräten mit begrenzter Rechenleistung ermöglicht.
Mit der zunehmenden Verbreitung von KI ist es wahrscheinlich, dass Objekterkennungsmodelle wie YOLO11 für Echtzeitentscheidungen in Umgebungen, in denen Geschwindigkeit und Genauigkeit entscheidend sind, noch wichtiger werden. Mit fortlaufenden Verbesserungen im Design und in der Anpassungsfähigkeit wird die Zukunft der Objekterkennung voraussichtlich noch mehr Innovationen für eine Vielzahl von Anwendungen bringen.
Wesentliche Erkenntnisse
Die Objekterkennung hat einen langen Weg zurückgelegt und sich von einfachen Methoden zu den fortschrittlichen Deep-Learning-Techniken entwickelt, die wir heute kennen. YOLO waren das Herzstück dieses Fortschritts und ermöglichten eine schnellere und genauere Echtzeit-Erkennung in verschiedenen Branchen. YOLO11 baut auf diesem Erbe auf, verbessert die Effizienz, senkt die Rechenkosten und erhöht die Genauigkeit, was es zu einer zuverlässigen Wahl für eine Vielzahl von Echtzeitanwendungen macht. Mit den kontinuierlichen Fortschritten in den Bereichen KI und Computer Vision sieht die Zukunft der Objekterkennung rosig aus und bietet Raum für noch mehr Verbesserungen bei Geschwindigkeit, Präzision und Anpassungsfähigkeit.
Neugierig auf KI? Bleiben Sie mit unserer Community in Verbindung, um weiterzulernen! Besuchen Sie unser GitHub-Repository, um zu erfahren, wie wir KI nutzen, um innovative Lösungen in Branchen wie der Fertigung und dem Gesundheitswesen zu entwickeln. 🚀








.webp)

.webp)